从零开始学R语言Day6|DataFrame
1.0 DataFrame类型
DataFrame是一种用于存储类似电子表格的数据的格式,他可以同时存储多个维度不同类型的数据,就像我们所熟悉的excel、csv文件一样,通常我们调用或导入的excel、csv文件的数据格式都是DataFrame格式的。
1.1 创建数据框
使用data.frame函数创建DataFrame类型数据,创建DataFrame输入的数据一般是以列为单位输入,实例如下
> a <- data.frame(
&#43; name &#61; c("zhangsan","lisi","wangwu","zhaoliu"),
&#43; subject &#61; c("math","math","math","math"),
&#43; score &#61; c(76,81,63,90),
&#43; row.names &#61; NULL #行的名字为空&#xff0c;若需要&#xff0c;可以自己定义想要的行名&#xff0c;方式参照其他参数
&#43;
&#43; )
我们可以直接print(a)在终端打印&#xff0c;也可以使用View(a)输出结果&#xff0c;用View(a)打印的结果往往更直观美观&#xff0c;在这里两种形式都将展示
print(a)name subject score
1 zhangsan math 76
2 lisi math 81
3 wangwu math 63
4 zhaoliu math 90
View(a)
1.2 获取结构和摘要
使用str()函数获取DataFrame的结构
> str(a)
&#39;data.frame&#39;: 4 obs. of 3 variables:$ name : Factor w/ 4 levels "lisi","wangwu",..: 3 1 2 4$ subject: Factor w/ 1 level "math": 1 1 1 1$ score : num 76 81 63 90
使用summary()获取数据的摘要和性质
> summary(a)name subject score lisi :1 math:4 Min. :63.00 wangwu :1 1st Qu.:72.75 zhangsan:1 Median :78.50 zhaoliu :1 Mean :77.50 3rd Qu.:83.25 Max. :90.00
那么为什么有必要特意提及这两个函数呢&#xff1f;因为在实际的数据清理和处理过程中&#xff0c;我们面临的数据量可能十分庞大&#xff0c;打开数据文件一时也难以分析出数据的特征&#xff0c;而这两个函数就能很方便的给我们呈现一些特征&#xff0c;方便我们接下来的编程处理&#xff08;PS&#xff1a;数据处理是需要我们根据数据的特征来写代码的&#xff09;为了方便说明&#xff0c;我在此举一个数据比较大的例子&#xff0c;方便大家理解
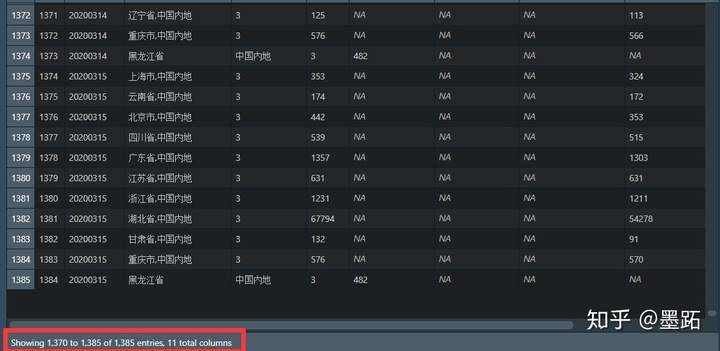
大家看到红色部分&#xff0c;这是一个有一千多条数据的数据集&#xff0c;面板只有那么大&#xff0c;能看到的只是局部的数据&#xff0c;因此难以把握数据的全貌。
> data <- read.csv("ncov_num.csv",encoding&#61;"UTF-8") #导入数据文件中的数据
> is.data.frame(data) #判断数据是否是dataframe类型
[1] TRUE #值为真&#xff0c;说明是dataframe类型
> str(data) #查看数据结构
&#39;data.frame&#39;: 1385 obs. of 11 variables:$ X : int 0 1 2 3 4 5 6 7 8 9 ...$ ann_date : int 20200124 20200124 20200124 20200124 20200124 20200124 20200124 20200124 20200124 20200124 ...$ area_name : Factor w/ 31 levels "安徽省,中国内地",..: 29 18 2 14 25 19 1 21 22 5 ...$ parent_name : Factor w/ 2 levels "3","中国内地": 1 2 1 1 1 1 1 1 1 1 ...$ level : int 5 3 36 3 15 2 15 15 1 53 ...$ confirmed_num : int NA 2 NA NA NA NA NA NA NA NA ...$ suspected_num : logi NA NA NA NA NA NA ...$ confirmed_num_now: logi NA NA NA NA NA NA ...$ suspected_num_now: int 0 NA 1 0 0 0 0 0 0 2 ...$ cured_num : int 0 0 0 0 0 0 0 0 0 0 ...$ dead_num : int NA 0 NA NA NA NA NA NA NA NA ...
整个文件的数据结构和主要的数据特征都在上面呈现出来&#xff0c;比如说我们通过这个操作就发现这个文件中有大量的NA值&#xff0c;而之后我们将知道&#xff0c;使用条件语句时&#xff0c;NA值时无法判断真假的&#xff0c;将会报错。因此就会考虑优先去除NA值这一操作&#xff0c;从而避免报错之后来寻错而造成的大量时间损失
> summary(data)X ann_date area_name parent_name Min. : 0 Min. :20200124 北京市,中国内地: 52 3 :1246 1st Qu.: 346 1st Qu.:20200204 广东省,中国内地: 52 中国内地: 139 Median : 692 Median :20200216 黑龙江省 : 52 Mean : 692 Mean :20200221 湖北省,中国内地: 52 3rd Qu.:1038 3rd Qu.:20200228 四川省,中国内地: 52 Max. :1384 Max. :20200315 重庆市,中国内地: 52 (Other) :1073 level confirmed_num suspected_num confirmed_num_nowMin. : 1 Min. : 2.0 Mode:logical Mode:logical 1st Qu.: 72 1st Qu.: 44.5 NA&#39;s:1385 NA&#39;s:1385 Median : 206 Median : 75.0 Mean : 2007 Mean :164.3 3rd Qu.: 576 3rd Qu.:319.0 Max. :67794 Max. :482.0 NA&#39;s :1246 suspected_num_now cured_num dead_num Min. : 0.0 Min. : 0.00 Min. : 0.000 1st Qu.: 10.0 1st Qu.: 0.00 1st Qu.: 0.000 Median : 87.0 Median : 1.00 Median : 1.000 Mean : 932.5 Mean : 73.43 Mean : 3.669 3rd Qu.: 307.0 3rd Qu.: 4.00 3rd Qu.: 6.500 Max. :54278.0 Max. :3085.00 Max. :13.000 NA&#39;s :139 NA&#39;s :1246
而倘若我们需要做一些统计分析等等&#xff0c;summary函数则会直观的统计出各个维度数据的重要指标信息&#xff0c;如上&#xff0c;最小值、最大值、四分位数、中位数、空值数目等等……这些数据都有利于我们对一个庞大的数据集形成大致的基本的认知。
1.3提取特定行或列
1.3.1提取特定列
对于一个庞大的文件&#xff0c;我们很多时候往往只需要抽取一个维度的数据进行分析&#xff0c;因此提取特定列的作用显得相当重要&#xff0c;而在R中提取特定列相当简单&#xff0c;语法是 data.frame(数据的变量名$列名)&#xff0c;具体实例如下&#xff1a;
#在后面的例子中data都是指的下面第一行中的这个data变量名&#xff01;&#xff01;&#xff01;
> data <- read.csv("ncov_num.csv",encoding&#61;"UTF-8")
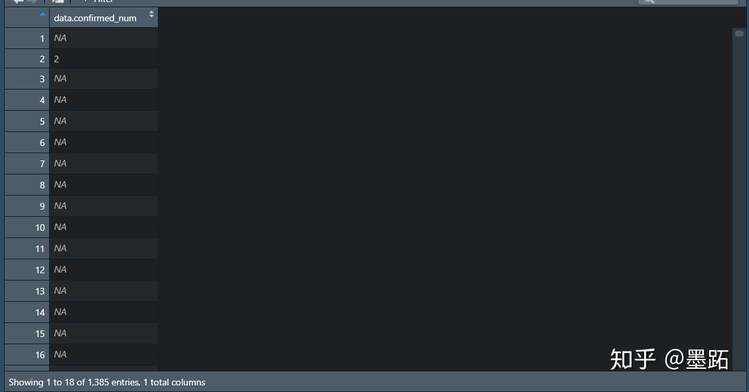
> confirmed.num <- data.frame(data$confirmed_num)
> View(confirmed.num)
1.3.2提取前n行(n为任意整数)的所有列
result <- data[1:2,] #提取前两行的所有列
效果&#xff1a;
1.3.3提取单元格数据
变量名[行&#xff0c;列]
如果要提取任意的几个单元格的数据该怎么做&#xff1f;
> result <- data[c(2,3),c(2,5)]
没错&#xff0c;就是用c函数将每一个行列的单元格联接起来
1.4添加行和列
1.4.1 添加列
添加列只需要用新列命来添加列向量&#xff0c;示例如下
> a <- data.frame(
&#43; name &#61; c("zhangsan","lisi","wangwu","zhaoliu"),
&#43; subject &#61; c("math","math","math","math"),
&#43; score &#61; c(76,81,63,90)
&#43;
&#43; )
> aname subject score
1 zhangsan math 76
2 lisi math 81
3 wangwu math 63
4 zhaoliu math 90> a$dept <- c("Operations","IT","HR","Finance") #这就是增加的那一个向量
>
>
> b <- a #把增加了列的新向量复制给b
> bname subject score dept
1 zhangsan math 76 Operations
2 lisi math 81 IT
3 wangwu math 63 HR
4 zhaoliu math 90 Finance#前后对比一下就发现成功加入了一列
注意&#xff01;&#xff01;&#xff01;添加的新列的元素必须和其他列的元素个数相同&#xff0c;否则会报错
如果是两个dataframe结构相同&#xff0c;比如说都是4×4的结构&#xff0c;则可以使用cbind()函数将其粘合起来&#xff0c;这里不再举例&#xff0c;具体操作和矩阵一直&#xff0c;请回看Day4
1.4.2添加行
添加行只有一种方式就是使用与现有数据帧相同结构的新行&#xff0c;并使用rbind()函数&#xff0c;不再赘述&#xff0c;详细操作请回看Day4
墨跖&#xff1a;从零开始学R语言Day4|向量、矩阵和数组zhuanlan.zhihu.com
【未完待续&#xff0c;持续更新……】












 京公网安备 11010802041100号
京公网安备 11010802041100号