作者提供代码在https://github.com/thunlp/OpenNRE网址
主要技术:
文章主要是通过一对实体和对应的多个包含实体对的句子实例作为训练数据集,对训练句子多个实例进行多层卷积然后得到表示 编码,然后通过
编码,然后通过 ,对句子进行权重分配,来表示不同句子对两个实体关系分类的贡献不同。
,对句子进行权重分配,来表示不同句子对两个实体关系分类的贡献不同。
主要是一些老的方法避免不了错误数据以及噪声的影响,由此提出的句子级别attention模型来提取关系,首先我们画出模型整体图进行解析:
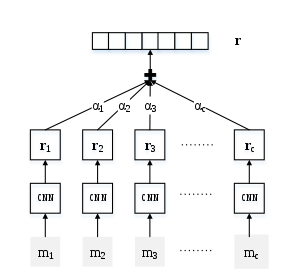
图1
在图中其中 表示一对实体的原始句子,
表示一对实体的原始句子, 表示句及级别的权重,也就是对分类的贡献度,从这里可以看出整个模型思路比较简单。
表示句及级别的权重,也就是对分类的贡献度,从这里可以看出整个模型思路比较简单。
首先对面为一个句子用cnn编码句子形成语义句子表示;然后为了能够利用所有的句子集合的信息,把提取关系表示为句子embedding的组成。通过attention减少错误句子对关系提取的影响,其中权重是能够训练的。
整个模型共有以下三方面贡献:
1/与现有方法比较,利用了所有句及集合信息;2/为了消除句子噪声影响,提出句子级别的attention;3/在实验中发现有助于关系提取的测试;
模型介绍:
input:首先是一个句子集合{x1,x2,...,xn}以及对应的实体对,
output:输出每一个已经定义好的关系类别概率R;
模型组成两个模块:
(1)句子编码:给定一个句子x和两个实体对,用cnn句子的分布表示X;具体模型结构见图2
(2)经过句子表示分布之后,通过attention选择哪些对真实关系有作用;
句子编码:
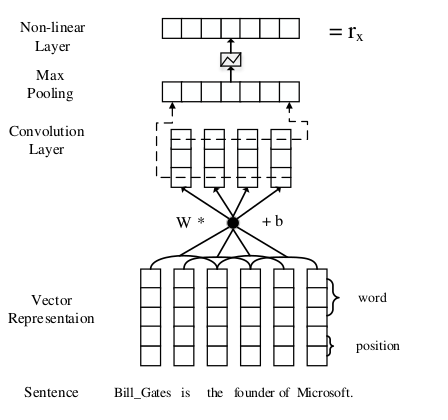
图2
如图2我们把句子x转换为表示分布X,首先转换成真实多特征向量,然后卷积层,max-pooling非线性用来构建句子分布表示X;
具体过程如下:
(1)输入表示:输入表示,我们把句子信息分成两个部分,一个是实体对应的位置信息编码,一个是单词编码共同组成句子向量;
给定一个有m个单词组成句子x;x={w1,w2,...,wm},每一个wi由实值向量表示,单词表示由embedding矩阵的列向量构成;即一 个列向量表示一个词汇的表示,那么共有V个词汇假设,那么v矩阵共有 *V个维度。所以矩阵
*V个维度。所以矩阵 ;
;
位置编码:越接近目标实体的单词越和关系有关在这样的思想下,用实体位置关系进行embedding可以有效多帮助cnn追踪每个单词是在实体的前端还是后端。例子:bill is the founder of microsoft,founder对应第一个实体的距离是3,并且对应后一个是2.
在这个例子中假设,单词的编码维度 是3,位置编码的维度
是3,位置编码的维度 是1,连接单词编码与位置编码,和在一起作为句子向量
是1,连接单词编码与位置编码,和在一起作为句子向量 ,其中
,其中 之所以乘以2是由于,每个单词对应两个实体之间的对应关系。
之所以乘以2是由于,每个单词对应两个实体之间的对应关系。
3.12 有关于本论文的卷积以及max-pooling 非线性层
在整个关系提取中,最大的挑战在于句子的长度是可变的,并且重要的信息可以在任何位置,所以需要全局特征,卷积网络能够很好的捕获这些特征,卷积特征首先利用跨度为l的滑动窗口提取局部特征,例如图2,l=3,然后通过max-pooling获取输入句子的固定特征向量.
因此卷积被定义为句子向量W和一个卷积矩阵 ,其中
,其中 就是句子embedding的大小,可以理解为卷积输出的维度大小,定义
就是句子embedding的大小,可以理解为卷积输出的维度大小,定义 作为滑动窗口大小的表示,也就是word的联合维度大小..
作为滑动窗口大小的表示,也就是word的联合维度大小..
假设第i个窗口定义如下:
 (1)
(1)
对于卷积边界直接使用零进行扩充,因此第i个卷积核的表示为:
 (2)也容易比较理解,就是把句子局部特征进行提取.
(2)也容易比较理解,就是把句子局部特征进行提取.
那么作者紧接着在第i步用如下公式进行处理: (3)最后再采用非线性函数进行处理.最终得到句子表示.
(3)最后再采用非线性函数进行处理.最终得到句子表示.
3.2 对于多实例选择attention
假设对于一对实体(head,tail) 有句子实例集合S= ,那么每一个
,那么每一个 ,表示一个句子的特征表示,整个实体对的相对于
,表示一个句子的特征表示,整个实体对的相对于
实体对关系的信息表示为: ,整个公式非常明显,就不做多解释.对于权重是怎么计算的,接下来将详细解释.
,整个公式非常明显,就不做多解释.对于权重是怎么计算的,接下来将详细解释.
其中 ,其中
,其中 , (8)
, (8)  是基于查询的函数匹配句子输入
是基于查询的函数匹配句子输入 是和关系r的得分,我们选择双线性形式,达到最佳表现.其中A是对角矩阵,其中r表示与关系有关系的表示.
是和关系r的得分,我们选择双线性形式,达到最佳表现.其中A是对角矩阵,其中r表示与关系有关系的表示.
最后定义关系分类概率 (9)
(9)
其中 是关系总共的数量,
是关系总共的数量, 是神经网络最后的输出,对应所有关系的分数.定义如下:
是神经网络最后的输出,对应所有关系的分数.定义如下:

3.3优化细节
本文模型主要是用了交叉熵函数







 京公网安备 11010802041100号
京公网安备 11010802041100号