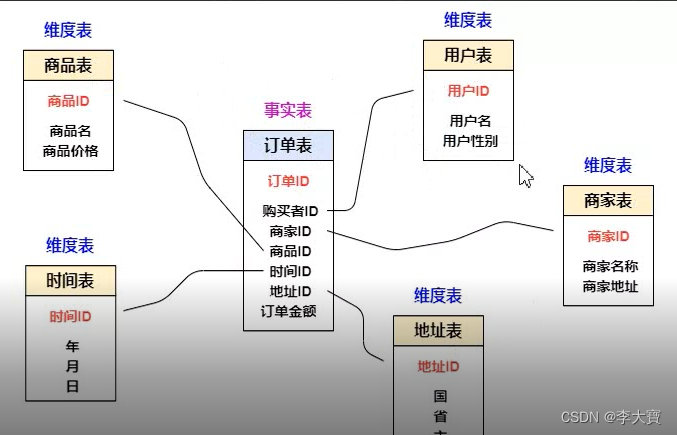
前言
只有光头才能变强。
文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y
这篇文章主要是入门大数据,不涉及到高深的知识点和理论,我相信每个人都看得懂。如果文章有错误的地方,不妨在评论区友善指出~
一、什么是大数据?
1.1 前置知识
我有的时候给外行人讲解什么是数据库,就常常用Excel来举例子(因为大多数人认识什么是Excel)。在知乎有一个类似的题目《有excel了要数据库干啥?》,大家可以去看看:
- https://www.zhihu.com/question/26779236
其实很大一部分原因就是:Excel能处理的数据量远远没有数据库得多。由于我们互联网产生的数据是非常非常多的,所以我们一般选择数据库来存储数据。
Excel只有104w行,多了加载不进去的 ---- @知乎 EamonLiao
众所周知,我们能存多少数据,是取决于我们硬盘的大小的。比如,我的磁盘的大小就256GB(实际能存储的大小是没有256GB的,但这里我就不展开了),这意味着我这电脑只能存储比256GB要小的数据。
为了能够更好地管理计算机的数据(访问和查找变得更加简单),我们就有了文件系统。
有了文件系统,已经可以存储数据了(很方便我们去获取),那为什么还会有数据库呢?
文件系统存在以下缺点: 数据共享性差,冗余度大; 数据独立性差
数据库系统实现整体结构化,这是数据库系统与文件系统的本质区别。 -----《数据库系统概论》
数据库其实就是为了针对特定类型数据处理而设计的系统,而文件系统则可看作通用型的数据存储系统 @知乎 吴穗荣
再回到大数据上,大数据就看名字我们就知道:数据量很大。大到什么程度呢?一块普通的硬盘不能将一个文件存储下来。
那我还想将这个文件存下来,怎么办呢?方案其实很简单(说白了一个是垂直伸缩,一个是水平伸缩):
-
多买几块硬盘,组成一个更大的“硬盘”,希望能容纳更多的数据。
- RAID(独立磁盘冗余阵列)技术是将多块普通磁盘组成一个阵列,共同对外提供服务。
- 比如,我现在觉得我的电脑16GB不够用了,而我的主板有两个内存槽,我多买一条16GB的内存条插入。那我就可以说,我的电脑是32GB内存的。
-
把这个文件切开几份,存到不同的硬盘中
- 比如我有1个TB的文件,我把它切分成5份,每份200G,存到不同的服务器中。
如果是普通的用户,肯定选择的是多买一块硬盘,升级硬件啊。但是互联网公司就不这样干,他们就选择将一个文件切分成几份,放到不同的服务器中。为什么?
- ***的电脑硬件成本很大。(单台计算机性能到一定的量上,再升级的成本就非常高)
- 单单一台***的电脑可能也无法处理掉这么大量的数据
综上所述,目前互联网企业中都是选择水平伸缩在一个系统中添加计算机来满足不断增长的用户量和支撑数据的平稳运行。
1.2 解决存储问题
随着数据量越来越大,在一台机器上已经无法存储所有的数据了,那我们会将这些数据分配到不同的机器来进行存储,但是这就带来一个问题:不方便管理和维护
所以,我们就希望有一个系统可以将这些分布在不同操作服务器上的数据进行统一管理,这就有了分布式文件系统
- HDFS是分布式文件系统的其中一种(目前用得最广泛的一种)
在使用HDFS的时候是非常简单的:虽然HDFS是将文件存储到不同的机器上,但是我去使用的时候是把这些文件当做是存储在一台机器的方式去使用(背后却是多台机器在执行):
- 好比:我调用了一个RPC接口,我给他参数,他返回一个response给我。RPC接口做了什么事其实我都不知道的(可能这个RPC接口又调了其他的RPC接口)-----屏蔽掉实现细节,对用户友好
1.3 解决计算问题
上面我们使用HDFS作为分布式文件系统,已经可以把数据存到不同的机器上(或者在不同的机器上读取到数据)。可以通过简单命令行的方式对文件的简单的存取。
现在呢,由于数据量是非常大的,分散到不同的机器上。我们想要对数据进行处理,我们肯定会有一段写好的程序。处理的方式有两种:
- 将数据传递给程序(机器A/B/C的数据传给机器D程序来执行)
- 程序到数据所在的地方执行(将程序分别到机器A/B/C上执行)
选哪个?我们一般会采用”程序到数据所在的地方执行“,因为在大数据里边我们的数据量很大,如果要把机器A/B/C的数据输入到机器D上,这样不划算。
- 数据量很大,通过网络传输大数据到某一台机器上做操作,不合适。
- 机器D只有一台机器,处理的效率低下。
所以我们会将程序分别放到机器A/B/C上处理,本来程序就非常小,放到别的机器上是轻轻松松的。还可以使用机器A/B/C的资源做运算,这就很合适了。
「将数据传递给程序」这种就是所谓的“移动存储到计算”,而「程序到数据所在的地方执行」这种就是所谓的“移动计算到存储的观念”。
在大数据的领域里, 移动计算比移动数据更划算。MapReduce就是这样干的:
- 每台机器执行任务的时候去检查自己有没有相应的程序,如果没有则通过网络下载程序包,然后通过反射来加载程序
二、大数据没有想象中神秘
在刚听到「大数据」这个词的时候,可能有的人会想问:所谓大数据,那数据是从哪里来的呢?
简单来说可以归类为三类:
- 日志
- 数据库
- 爬虫
1、 爬虫应该很好理解,就是通过网络爬虫获取外部数据,将这些数据自己存储起来。很多的比价网站就是爬取各种电商网站的数据,然后比较各个网站的数据后得到结果。本身它们网站本身是没有这个数据的,这个数据是从别人那爬过来的。
2、数据库本来就已经存储了我们的数据,而我们要做的只是把数据库的数据导入我们的大数据平台那儿,让数据能够得到更好的分析。
3、日志这块其实我更多想说的是打点(埋点)这块。有的人会把这埋点和日志的概念分开,只是我把它给合在一起叫「日志」。日志有用户行为日志(埋点),也有系统的运行产生的日志。用户行为日志这块说白了就是:从你进去某个APP的一刻开启。几乎你所有的操作都会被记录下来(点了某个tag、在某个tag停顿了多少秒)。猜你喜欢这类的系统就是根据你以往行为来对进行推荐。
好了,现在我们有不同的地方收集到数据,我们要最终要做的就是把这个数据汇总到一起来进行存储和分析。
于是我们就需要将日志、数据库、爬虫这些不同数据源的数据导入到我们的集群中(这个集群就是上面提到的,分布式文件系统(HDFS),分布式计算系统)。
由于数据源的不同,所以会有多种的工具对数据进行导入。比如将日志的数据收集我们会有Flume,从数据库同步我们会有Sqoop。这也就是所谓的ETL(萃取「extract」、转置「transform」、加载「load」)
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
(注:不要被上面的Sqoop、Flume 这样的名词给吓着了,其实就是现有的成熟的框架技术)
我们把所有的数据收集起来,把这个存储数据的地方叫做数据仓库。基于数据仓库我们统计能各种的指标,基于这些指标可以指导我们是否要做一个需求或决策。
比如说:现在我们要对APP的首页改版了,但不知道用户是否能接受这次的改版。于是我们就可以先对一少部分的用户做实验(这一部分的用户看到的是改版后的首页),我们根据这一部分用户的行为来判断这一次的改版是否有比较好的效果。
- 用户的行为我们都有收集起来。只要将实验用户关联到对应的指标,与现有的指标做一次对比,我们大概就知道这次改版是否真的合理。
这种拿一部分流量做实验,我们也称这种做法为「ABTest」,如果对ABTest感兴趣的同学可以在我的GitHub下搜索关键字「ABTest」来阅读具体的文章哦~
最后
这篇文章简单的说了一下所谓的「大数据」中的数据是从哪里来的,由于数据量很大,所以我们要解决数据的存储和计算的问题。
基于存储和计算问题我们业内就提供了很多现成的技术实现了,下面图中的技术每一种类型我后续都会讲解到,可以关注我,不迷路哦。
参考资料:《从0开始学大数据》--李智慧
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号「Java3y」。
-
 本文详细介绍如何使用 Python 进行数据可视化,涵盖从环境搭建到具体实例的全过程。 ... [详细]
本文详细介绍如何使用 Python 进行数据可视化,涵盖从环境搭建到具体实例的全过程。 ... [详细] 从0到1搭建大数据平台 ... [详细]毕设做到后半部分,需要实现将用户在一段时间(比如1天)内产生的新数据导入HDFS的功能,这样数据仓库中的数据才能和数据库中的数据同步在新建了一个PyDev项目后,需要如下操作(拣最 ... [详细]
从0到1搭建大数据平台 ... [详细]毕设做到后半部分,需要实现将用户在一段时间(比如1天)内产生的新数据导入HDFS的功能,这样数据仓库中的数据才能和数据库中的数据同步在新建了一个PyDev项目后,需要如下操作(拣最 ... [详细] 本文将详细介绍HTML5中新增的字符集属性charset和defaultCharset,帮助开发者更好地理解和应用这些属性,以确保网页在不同环境下的正确显示。 ... [详细]
本文将详细介绍HTML5中新增的字符集属性charset和defaultCharset,帮助开发者更好地理解和应用这些属性,以确保网页在不同环境下的正确显示。 ... [详细] 秒建一个后台管理系统?用这5个开源免费的Java项目就够了 ... [详细]Hadoop 2.6 主要由 HDFS 和 YARN 两大部分组成,其中 YARN 包含了运行在 ResourceManager 的 JVM 中的组件以及在 NodeManager 中运行的部分。本文深入探讨了 Hadoop 2.6 日志文件的解析方法,并详细介绍了 MapReduce 日志管理的最佳实践,旨在帮助用户更好地理解和优化日志处理流程,提高系统运维效率。 ... [详细]
秒建一个后台管理系统?用这5个开源免费的Java项目就够了 ... [详细]Hadoop 2.6 主要由 HDFS 和 YARN 两大部分组成,其中 YARN 包含了运行在 ResourceManager 的 JVM 中的组件以及在 NodeManager 中运行的部分。本文深入探讨了 Hadoop 2.6 日志文件的解析方法,并详细介绍了 MapReduce 日志管理的最佳实践,旨在帮助用户更好地理解和优化日志处理流程,提高系统运维效率。 ... [详细] 技术日志:深入探讨Spark Streaming与Spark SQL的融合应用 ... [详细]
技术日志:深入探讨Spark Streaming与Spark SQL的融合应用 ... [详细] RDD是Spark框架的核心计算模型,全称为弹性分布式数据集(Resilient Distributed Dataset)。本文详细解析了RDD的基本概念、特性及其在Spark中的关键操作,包括创建、转换和行动操作等,帮助读者深入理解Spark的工作原理和优化策略。通过具体示例和代码片段,进一步阐述了如何高效利用RDD进行大数据处理。 ... [详细]
RDD是Spark框架的核心计算模型,全称为弹性分布式数据集(Resilient Distributed Dataset)。本文详细解析了RDD的基本概念、特性及其在Spark中的关键操作,包括创建、转换和行动操作等,帮助读者深入理解Spark的工作原理和优化策略。通过具体示例和代码片段,进一步阐述了如何高效利用RDD进行大数据处理。 ... [详细] 篇首语:本文由编程笔记#小编为大家整理,主要介绍了一文理解Spark基础概念及工作原理相关的知识,希望对你有一定的参考价值。 ... [详细]本文介绍了在sqoop1.4.*版本中,如何实现自定义分隔符的方法及步骤。通过修改sqoop生成的java文件,并重新编译,可以满足实际开发中对分隔符的需求。具体步骤包括修改java文件中的一行代码,重新编译所需的hadoop包等。详细步骤和编译方法在本文中都有详细说明。 ... [详细]我们在之前的文章中已经初步介绍了Cloudera。hadoop基础----hadoop实战(零)-----hadoop的平台版本选择从版本选择这篇文章中我们了解到除了hadoop官方版本外很多 ... [详细]
篇首语:本文由编程笔记#小编为大家整理,主要介绍了一文理解Spark基础概念及工作原理相关的知识,希望对你有一定的参考价值。 ... [详细]本文介绍了在sqoop1.4.*版本中,如何实现自定义分隔符的方法及步骤。通过修改sqoop生成的java文件,并重新编译,可以满足实际开发中对分隔符的需求。具体步骤包括修改java文件中的一行代码,重新编译所需的hadoop包等。详细步骤和编译方法在本文中都有详细说明。 ... [详细]我们在之前的文章中已经初步介绍了Cloudera。hadoop基础----hadoop实战(零)-----hadoop的平台版本选择从版本选择这篇文章中我们了解到除了hadoop官方版本外很多 ... [详细] 篇首语:本文由编程笔记#小编为大家整理,主要介绍了大数据之非常详细Sqoop安装和基本操作相关的知识,希望对你有一定的参考价值。大数据大数据之 ... [详细]
篇首语:本文由编程笔记#小编为大家整理,主要介绍了大数据之非常详细Sqoop安装和基本操作相关的知识,希望对你有一定的参考价值。大数据大数据之 ... [详细] Tags | 热门标签RankList | 热门文章
Tags | 热门标签RankList | 热门文章- 1Python 入门必学经典知识点笔记【肯定有你不知道的】
- 2Vue的组件化
- 3每日一题:一 石头 这里注重算法和效率
- 4codeforces: D. Tricks of bitwise operators 'and' and 'or' in square sum
- 5用jQuery做定位元素,做自动化测试你尝试过吗
- 6价格暴跌87% Chia硬盘矿年底消耗全球12%硬盘
- 7电脑系统重装失败开不了机如何解决
- 8主体|发生_C++基础入门丨6. 函数——定义调用和声明
- 9android图片浏览器(二)——实现显示图片的标题
- 10燤字意思 在新华字典的读音解释笔画常用组词起名
- 11安卓主要是通过什么开发的?春招我借这份PDF的复习思路,持续更新中
- 12camelinaction.Order.setAmount()方法的使用及代码示例
- 13栈是一种先进先出的线性表,对么
- 14php – Laravel雄辩:更新模型及其关系
- 15Tensorflow:tf.shape()和x.get_shape().as_list()import tensorflow as tf import numpy as np a_array=np.a
PHP1.CN | 中国最专业的PHP中文社区 | DevBox开发工具箱 | json解析格式化 |PHP资讯 | PHP教程 | 数据库技术 | 服务器技术 | 前端开发技术 | PHP框架 | 开发工具 | 在线工具
Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved | 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有