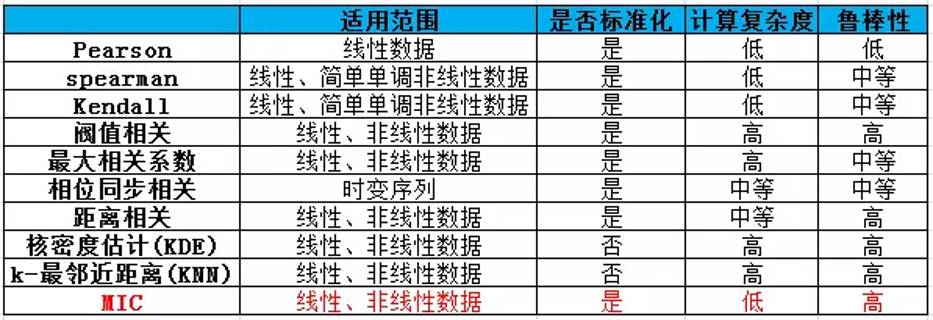
对于连续变量的计算不是很方便(X和Y都是集合, $x_i$, y 都是离散的取值),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
MIC 即:Maximal Information Coefficient 最大互信息系数克服了这两个问题。使用MIC来衡量两个基因之间的关联程度,线性或非线性关系,相较于Mutual Information(MI)互信息而言有更高的准确度。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在 [0,1]。
MIC的优越性
根据 MIC 的性质,MIC 具有普适性、公平性和对称性。所谓普适性,是指在样本量足够大(包含了样本的大部分信息)时,能够捕获各种各样的有趣的关联,而不限定于特定的函数类型(如线性函数、指数函数或周期函数),或者说能均衡覆盖所有的函数关系。一般变量之间的复杂关系不仅仅是通过单独一个函数就能够建模的,而是需要叠加函数来表现。所谓公平性,是指在样本量足够大时能为不同类型单噪声程度相似的相关关系给出相近的系数。例如,对于一个充满相同噪声的线性关系和一个正弦关系,一个好的评价算法应该给出相同或相近的相关系数。







 京公网安备 11010802041100号
京公网安备 11010802041100号