引子
写代码的每个同学估计都对注解(annotation)并不陌生,至少也用过@Override这样的注解。Java中的注解是个很神奇的东西,用了注解就可以少些很多代码,但是有没有想过这些注解呢如何实现的呢?这篇文章就带你走进Java注解的世界。本文的所有代码都在我的GitHub上的annokit里面,欢迎star和fork and pull request。
Java注解介绍
开始之前我们先来说一些基本的概念:
注解的介绍
Java注解是附加在代码中的一些元信息,用于编译和运行时进行解析和使用,起到说明、配置的功能。注解不会影响代码的实际逻辑,仅仅起到辅助性的作用。包含在java.lang.annotation包中。注解的定义类似于接口的定义,使用@interface来定义,定义一个方法即为注解类型定义了一个元素,方法的声明不允许有参数或throw语句,返回值类型被限定为原始数据类型、字符串String、Class、enums、注解类型,或前面这些的数组,方法可以有默认值。注解并不直接影响代码的语义,但是他可以被看做是程序的工具或者类库。它会反过来对正在运行的程序语义有所影响。注解可以从源文件、class文件或者在运行时通过反射机制多种方式被读取。
Java元注解
元注解是指注解的注解。包括 @Retention @Target @Document @Inherited四种。(java.lang.annotation中提供,为注释类型)。
| 注解 | 说明 |
|---|
| @Target | 定义注解的作用目标 |
| @Retention | 定义注解的保留策略。RetentionPolicy.SOURCE:注解仅存在于源码中,在class字节码文件中不包含;RetentionPolicy.CLASS:默认的保留策略,注解会在class字节码文件中存在,但运行时无法获得;RetentionPolicy.RUNTIME:注解会在class字节码文件中存在,在运行时可以通过反射获取到。 |
| @Document | 说明该注解将被包含在javadoc中 |
| @Inherited | 说明子类可以继承父类中的该注解 |
Target类型说明
| Target类型 | 说明 |
|---|
| ElementType.TYPE | 接口、类、枚举、注解 |
| ElementType.FIELD | 字段、枚举的常量 |
| ElementType.METHOD | 方法 |
| ElementType.PARAMETER | 方法参数 |
| ElementType.CONSTRUCTOR | 构造函数 |
| ElementType.LOCAL_VARIABLE | 局部变量 |
| ElementType.ANNOTATION_TYPE | 注解 |
| ElementType.PACKAGE | 包 |
Java注解实现
运行时处理的注解(反射机制)
1.定义注解
我们定义了一个使用反射实现的注解Reflect,注解有一个参数name,含有默认值。另外,保留策略要使用RUNTIME,将注解保留到运行时,这样才能在运行时使用反射来获取到注解。
package com.github.hackersun.annotation;import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;/*** Desc:* Author:sunguoli@meituan.com* Date:15/12/20*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Reflect {String name() default "sunguoli";}
2.实现注解处理器
注解处理器的代码:
package com.github.hackersun.processor.reflect;import com.github.hackersun.annotation.Reflect;
import java.lang.reflect.Method;/*** Desc:* Author:sunguoli@meituan.com* Date:15/12/20*/
public class ReflectProcessor {public void parseMethod(final Class clazz) throws Exception {final Object obj = clazz.getConstructor(new Class[] {}).newInstance(new Object[] {});final Method[] methods = clazz.getDeclaredMethods();for (final Method method : methods) {final Reflect my = method.getAnnotation(Reflect.class);if (null != my) {method.invoke(obj, my.name());}}}
}
3.测试注解
测试代码:
package com.github.hackersun.sample;import com.github.hackersun.annotation.Reflect;
import com.github.hackersun.processor.reflect.ReflectProcessor;/*** Desc:* Author:sunguoli@meituan.com* Date:15/12/20*/
public class ReflectTest {@Reflectpublic static void sayHello(final String name) {System.out.println("==>> Hi, " + name + " [sayHello]");}@Reflect(name = "AngelaBaby")public static void sayHelloToSomeone(final String name) {System.out.println("==>> Hi, " + name + " [sayHelloToSomeone]");}public static void main(final String[] args) throws Exception {final ReflectProcessor relectProcessor = new ReflectProcessor();relectProcessor.parseMethod(ReflectTest.class);}
}
Output:
==>> Hi, sunguoli [sayHello]
==>> Hi, AngelaBaby [sayHelloToSomeone]
编译时处理的注解(虚处理器方式AbstractProcessor)
介绍
Java代码编译过程
我们先来说一下Javac编译器的编译过程,大致可分为三个步骤:
- 解析与填充符号表过程;
- 插入式注解处理器的注解处理过程;
- 语义分析与字节码生成过程。
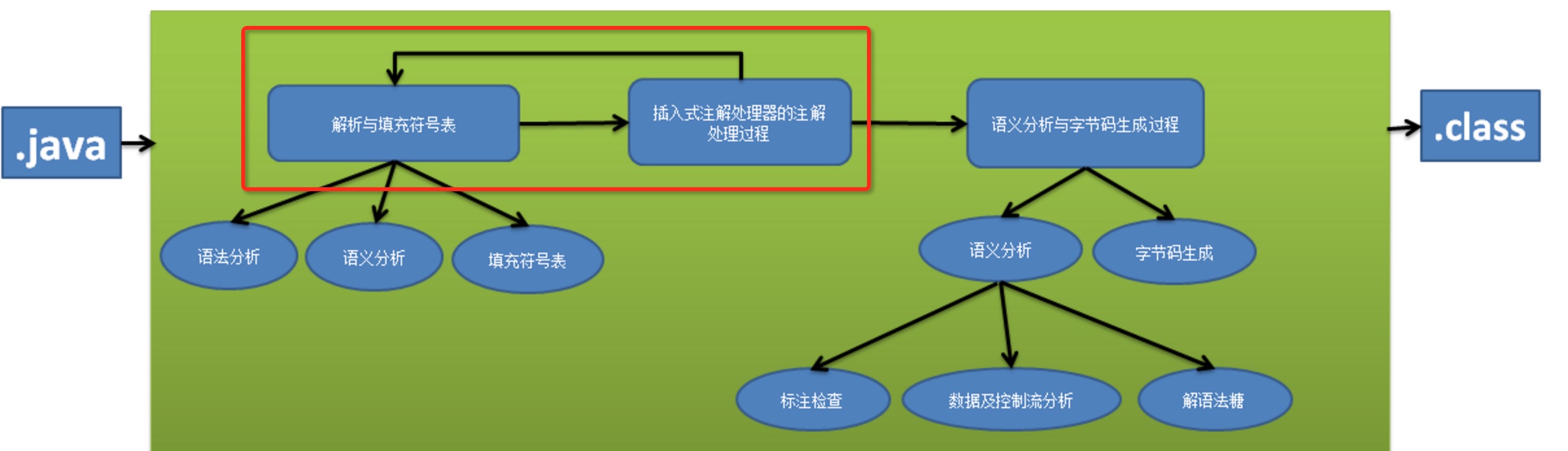
我们从图中就能看出来,注解处理器可以在第二个阶段处理注解,也就是我们要说的这种实现方式,通过继承AbstractProcessor的方式来实现。
注解处理器的注解处理过程:
插入式注解处理器可以在编译器时读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行了修改,那么编译器将回到解析及填充符号表的过程重新处理,直到所有的插入式注解处理器都没有再对语法树进行修改为止。
Example
1.注解定义
import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.SupportedAnnotationTypes;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;/*** Desc:* Author:sunguoli@meituan.com* Date:15/12/11 下午9:22*/
@Target({ElementType.TYPE,ElementType.METHOD,ElementType.FIELD})
@Retention(RetentionPolicy.SOURCE)
public @interface NameScanner{}
我们定义了一个可以使用在class,method,field上的注解NameScanner。保留策略是源码级。
2.定义注解处理器
import javax.annotation.processing.*;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
import javax.tools.Diagnostic;
import java.util.Set;/*** Desc:* Author:sunguoli@meituan.com* Date:15/12/11 下午9:33*/
@SupportedAnnotationTypes("*")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class NameScannerProcessor extends AbstractProcessor{@Overridepublic void init(ProcessingEnvironment processingEnv){super.init(processingEnv);}@Overridepublic boolean process(Set annotations, RoundEnvironment roundEnv){if(!roundEnv.processingOver()){for(Element element : roundEnv.getElementsAnnotatedWith(NameScanner.class)){String name = element.getSimpleName().toString();processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE, "element name: " + name);}}return false;}
}
这个注解处理器会把每一个被注解的元素名称打印出来。
3.测试
/*** Desc:* Author:sunguoli@meituan.com* Date:15/12/11 下午9:47*/
@NameScanner
public class NameScannerTest {@NameScannerprivate String name;@NameScannerprivate int age;@NameScannerpublic String getName(){return this.name;}@NameScannerpublic void setName(String name){this.name = name;}public static void main(String[] args){System.out.println("--finished--");}
}
我们来手动编译一下:
$ javac NameScanner.java
$ javac NameScannerProcessor.java
$ javac -processor NameScannerProcessor NameScannerTest.java
Output:
注: element name: NameScannerTest
注: element name: name
注: element name: age
注: element name: getName
注: element name: setName
通过输出看到注解处理器把每一个被注解的元素都打印出来了。实现了我们的注解功能。
示例代码的解释说明
- init(ProcessingEnvironment env): 每一个注解处理器类都必须有一个空的构造函数。然而,这里有一个特殊的init()方法,它会被注解处理工具调用,并输入ProcessingEnviroment参数。ProcessingEnviroment提供很多有用的工具类Elements, Types和Filer。后面我们将看到详细的内容。
- process(Set
其他参数的说明
在init()中我们获得如下引用:
- Elements:一个用来处理Element的工具类(后面将做详细说明);
- Types:一个用来处理TypeMirror的工具类(后面将做详细说明);
- Filer:正如这个名字所示,使用Filer你可以创建文件。
在注解处理过程中,我们扫描所有的Java源文件。源代码的每一个部分都是一个特定类型的Element。换句话说:Element代表程序的元素,例如包、类或者方法。每个Element代表一个静态的、语言级别的构件。在下面的例子中,我们通过注释来说明这个:
package com.example; // PackageElementpublic class Foo { // TypeElementprivate int a; // VariableElementprivate Foo other; // VariableElementpublic Foo () {} // ExecuteableElementpublic void setA ( // ExecuteableElementint newA // TypeElement) {}
}
我们必须换个角度来看源代码,它只是结构化的文本,他不是可运行的。你可以想象它就像你将要去解析的XML文件一样(或者是编译器中抽象的语法树)。就像XML解释器一样,有一些类似DOM的元素。你可以从一个元素导航到它的父或者子元素上。
举例来说,假如你有一个代表public class Foo类的TypeElement元素,你可以遍历它的孩子,如下:
TypeElement fooClass = ... ;
for (Element e : fooClass.getEnclosedElements()){ // iterate over children Element parent = e.getEnclosingElement(); // parent == fooClass
}
正如你所见,Element代表的是源代码。TypeElement代表的是源代码中的类型元素,例如类。然而,TypeElement并不包含类本身的信息。你可以从TypeElement中获取类的名字,但是你获取不到类的信息,例如它的父类。这种信息需要通过TypeMirror获取。你可以通过调用elements.asType()获取元素的TypeMirror。
总结
这篇文章只是一个Java注解的入门,无法通过一篇文章就能详细的介绍的程度,还是多看多写代码把。我的Github项目annokit实现了一些其他的注解,例如@Factory,@Setter,@Getter等,Setter和Getter并没有100%的做完,主要是由于涉及到需要修改语法树,如果不修改语法树而是生成class文件的话,一来就把本来是一个整体的class弄成两个了,再者也会和编译后生成的.class文件冲突。但是修改语法树的工作量很大,所以这里没有完全实现。










 京公网安备 11010802041100号
京公网安备 11010802041100号