跨流可见多流自注意力
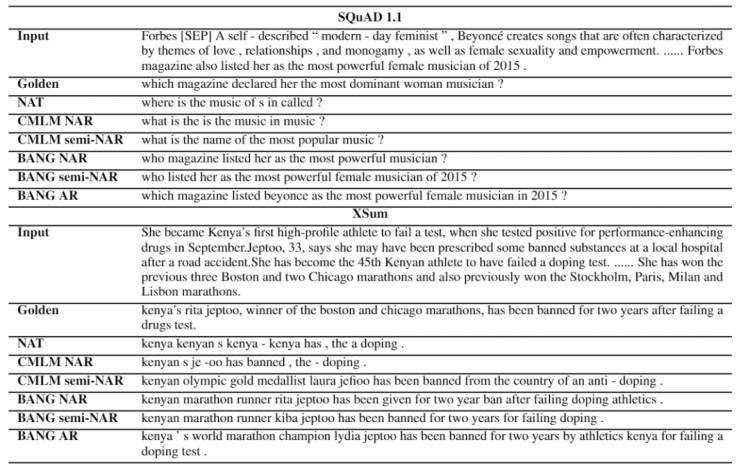
为了实现上述的优化目标,且高效并行化计算,研究员们提出了跨流可见多流自注意力机制。以预测 y_4 为例,如图1:
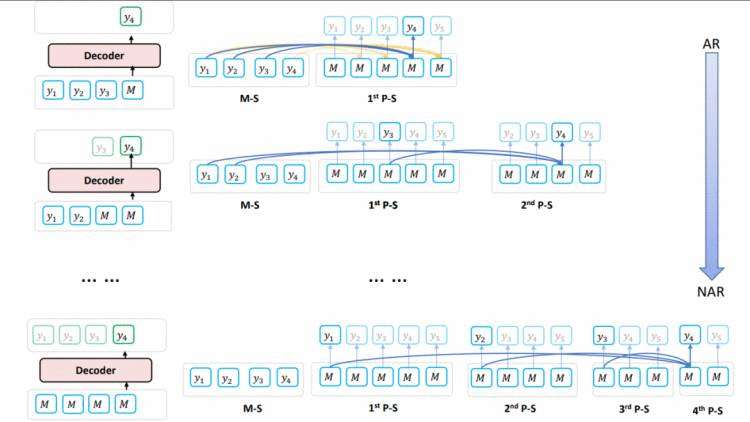
图1:BANG 预训练中的信息流
在图1 BANG 预训练中的信息流中,M-S 指主要流(main stream),喂入真实的字符;P-S 指预测流(predicting stream),喂入 [M]([MASK])。P-S 中的 [MASK] 向 M-S 和它之前的 P-S 进行注意力计算来获取前文的真实单词 +[MASK] 字符的信息。
图1最上面的一行展示了主要流和第一个预测流。预测 y_4 使用的 [M] 向主要流中的 y_1,y_2,y_3 进行注意力计算,即 y_4 以条件概率 P(y_4 |y_1,y_2,y_3) 进行预测,其效果如左侧所示。第一个预测流中的所有字符以完整的前文信息进行了自回归的预测。
图1中的第二行则展示了 y_4 在第二个预测流中的效果。第二个预测流中,每个被预测的单词所看到的前文信息都被遮盖住了一个字符,即如左侧所示,y_4 看到真实的 y_1 和 y_2,但是 y_3 被 [M] 遮盖。其实现如右侧的主要流和两个预测流所示。第二个预测流中的 [M] 向主要流的 y_1,y_2 以及第一个预测流中 y_3 的 [M] 进行注意力计算。第一个预测流 y_3 的 [M] 与第二个预测流中的 y_4 则组成了条件概率 P(y_3,y_4 |y_1,y_2)。比较第一行和第二行,可以看到,随着注意力流的增大,前面的上文信息被遮盖,生成方式也从自回归向非自回归移动。
图1中最后一行展示了 y_4 在第四个预测流中,最终以非自回归的方式进行预测。此时第四预测流中预测 y_4 的 [M] 向第一个预测流中 y_1 的 [M],第二个预测流中 y_2 的 [M] 和第三个预测流中 y_3 的 [M] 进行注意力计算,此时没有任何真实的上文信息被使用。
可以看到,第一个预测流中,每个单词都以自回归进行预测;每个预测流中的第一个单词以非自回归进行预测;其他位置则以介于自回归和非自回归之间的方式进行预测。假设目标序列长度 |Y|=n,则 BANG 设置 n 个预测流,此时每个词的任意长度前缀被 [M] 替换的情形都在同一个时间步中被进行并行的预测。
为了优化 GPU 的显存占用和计算量,BANG 采用了成块的计算方案。因为每个位置只会看到它之前的预测流信息,所以 BANG 从第一个预测流向最后一个预测流进行计算,将重复计算的 K 和 V 向量缓存下来。在第 l 层的工作流程如下:

其中,Linear 是从隐状态中获取 Q,K, V 向量的三个线性计算函数,⊕ 代表拼接操作,Attn 函数则可以描述为:
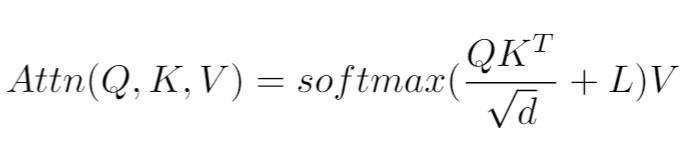
其中,L 为相对位置偏差和控制哪些位置可以被看到的遮盖矩阵。
微调策略
继续以预测 y_4 为例,来看一下针对自回归、非自回归、半自回归的微调策略。在 BANG 自回归生成微调中,预测流中的 [M] 可以从主要流中获取完整的前文信息。其训练方式同 XLNet 的双流机制。

图2:BANG 自回归微调
在 BANG 的非自回归微调中,只有一个预测流,并放置若干个 [M],使用单向信息流,与预训练一致。最后以第一个结束符 [SEP] 代表生成作为结束。

图3:BANG 非自回归微调
而在 BANG 的半非自回归微调中,训练过程同预训练方案,推断过程如图4所示,可以进行任意步数的自回归生成,作为高质量的上文线索,然后将剩余部分并行生成。
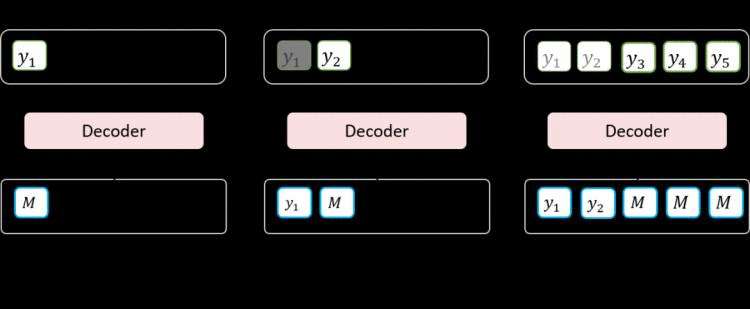
图4:BANG 半非自回归生成

实验结果
主实验
BANG 使用了 Wikipedia 加 BookCorpus 的 16GB 英语语料,使用 MASS 的连续字段掩盖预测任务进行了 BANG_base 的预训练。对于每个连续的64个单词的片段,会掩盖其中连续的15%即9个单词,用预测其掩盖的部分作为输出。BANG_base 使用了6层编码器、6层解码器、隐状态768和9个预测流进行了35轮的预训练。并使用了 SQuAD 1.1 问题生成、XSum 摘要和 PersonaChat 对话生成作为评测集,进行了自回归、非自回归、半自回归的对比,结果如下:
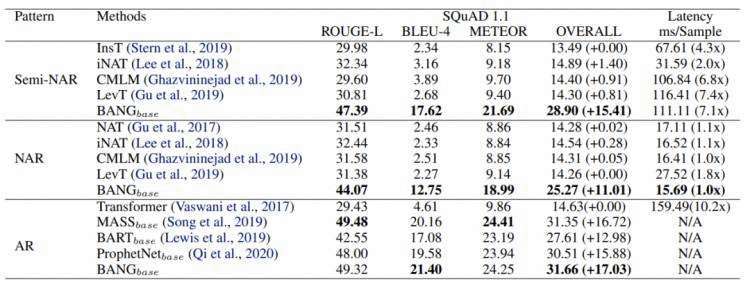
表1:SQuAD 1.1 问题生成的实验结果
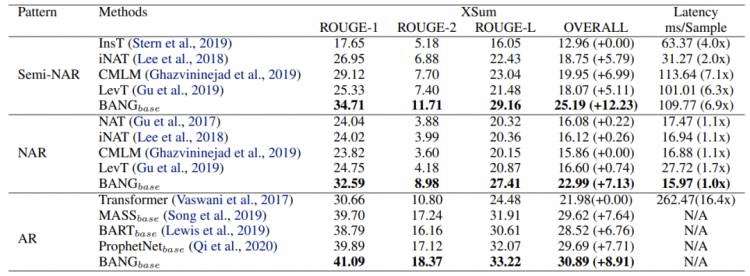
表2:XSum 摘要任务的实验结果
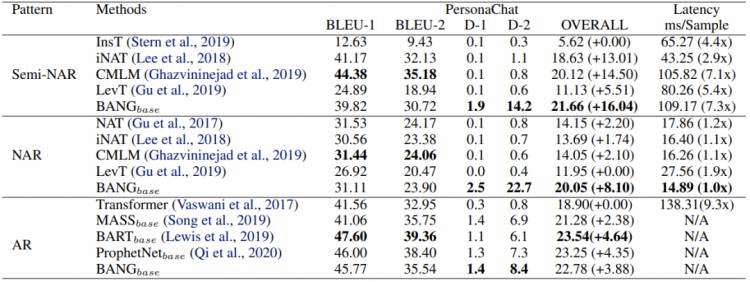
表3:PersonaChat 对话生成的实验结果
可以看到,BANG 对于非自回归和半非自回归的效果提升非常明显,推断速度基本相似,而对于自回归模型的效果与当前主流的自回归预训练模型也达到了相似的水准。BANG 非自回归的结果达到了未预训练 Transformer 的相似水平,并带来了约十倍的推断速度提升,这表明,通过预训练,非自回归也可以在普通的自然语言生成任务上得到不错的生成质量。
与非自回归预训练对比
因为 BANG 是非自回归的第一个大规模语料的预训练工作,所以在表1-表3中的非自回归和半非自回归的对比模型是没有经过预训练的。为了验证 BANG 对于非自回归生成预训练的有效性,研究员们使用了非自回归的方案进行了预训练并与 BANG 进行对比:
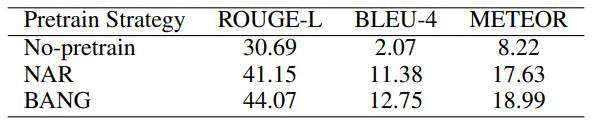
表4:SQuAD 1.1 问题生成上,没有预训练、非自回归预训练和 BANG 预训练的对比
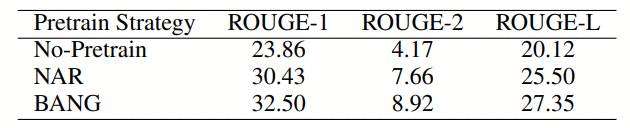
表5:Xsum 摘要任务上,没有预训练、非自回归预训练和 BANG 预训练的对比
可以看出,预训练可以显著提升非自回归的生成结果,而经过相同的非自回归微调,BANG 一致地超过了纯非自回归预训练结果。这表明,BANG 所提出的沟通自回归和非自回归的预训练方案是取得更好结果的原因。
案例分析
本文作者:齐炜祯、宫叶云、段楠
论文链接:(将于近日更新)
BANG: Bridging Autoregressive and Non-autoregressive Generation with Large Scale Pretraining
https://arxiv.org/abs/2012.15525
近期,研究员还将开源代码,敬请关注:
https://github.com/microsoft/BANG

福 利
CSDN给大家发压岁钱啦!
2月4日到2月11日每天上午11点
价值198元的芒果TV年卡,价值99元的CSDN月卡!现金红包,CSDN电子书月卡等奖品大放送!百分百中奖!
电脑端点击链接参与:https://t.csdnimg.cn/gAkN
更多精彩推荐
☞爬了20W+条猫咪交易数据,它不愧是人类团宠☞英超引入 AI 球探,寻找下一个足球巨星
☞三年投 1000 亿,达摩院何以仗剑走天涯?☞2021年浅谈多任务学习
点分享点收藏点点赞点在看












 京公网安备 11010802041100号
京公网安备 11010802041100号