假如我们现在在电脑前看电影,那么我们的注意力一定是集中在显示器而忽略键盘鼠标等物。“注意力机制”实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。
在计算机算力资源的限制下,注意力机制绝对是提高效率的一种必要手段。将注意力集中到有用的信息上,不要在噪声中花费时间。
核心目标:从众多信息中选择出对当前任务目标更关键的信息将注意力放在这上面。
1.注意力机制需要决定整段输入的哪个部分需要更加关注;
2.从关键的部分进行特征提取,得到重要的信息。
用数学语言来表达这个思想就是:用![X=[x_1, x_2, ..., x_N]](https://img0.php1.cn/3cdc5/6de3/78c/f66e41c7331b07e0.gif) 表示N个输入信息,为了节省计算资源,不需要让神经网络处理这N个输入信息,而只需要从X中选择一些与任务相关的信息输进行计算。软性注意力(Soft Attention)机制是指在选择信息的时候,不是从N个信息中只选择1个,而是计算N个输入信息的加权平均,再输入到神经网络中计算。
表示N个输入信息,为了节省计算资源,不需要让神经网络处理这N个输入信息,而只需要从X中选择一些与任务相关的信息输进行计算。软性注意力(Soft Attention)机制是指在选择信息的时候,不是从N个信息中只选择1个,而是计算N个输入信息的加权平均,再输入到神经网络中计算。
相对的,**硬性注意力(Hard Attention)就是指选择输入序列某一个位置上的信息,比如随机选择一个信息或者选择概率最高的信息。**但一般还是用软性注意力机制来处理神经网络的问题。
它们的输入形式不同。基于项的注意力的输入需要是包含明确的项的序列,或者需要额外的预处理步骤来生成包含明确的项的序列(这里的项可以是一个向量、矩阵,甚至一个特征图)。而基于位置的注意力则是针对输入为一个单独的特征图设计的,所有的目标可以通过位置指定。
得权重系数
方法:向量点积,余弦相似性,引入额外的神经网络来求值。
给定这样一个场景:把输入信息向量X看做是一个信息存储器,现在给定一个查询向量q,用来查找并选择X中的某些信息,那么就需要知道被选择信息的索引位置。采取“软性”选择机制,不是从存储的多个信息中只挑出一条信息来,而是雨露均沾,从所有的信息中都抽取一些,只不过最相关的信息抽取得就多一些。
于是定义一个注意力变量z∈[1, N]来表示被选择信息的索引位置,即z=i来表示选择了第i个输入信息,然后计算在给定了q和X的情况下,选择第i个输入信息的概率αi:
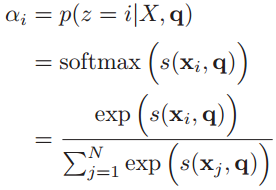
其中αi构成的概率向量就称为注意力分布(Attention Distribution)。s(xi , q)是注意力打分函数,有以下几种形式:
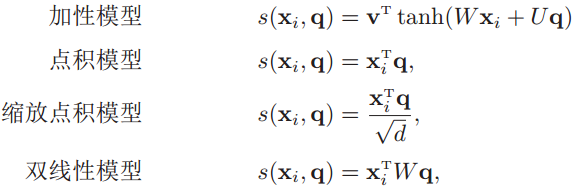
其中W、U和v是可学习的网络参数,d是输入信息的维度。
注意力分布αi表示在给定查询q时,输入信息向量X中第i个信息与查询q的相关程度。采用“软性”信息选择机制给出查询所得的结果,就是用加权平均的方式对输入信息进行汇总,得到Attention值:
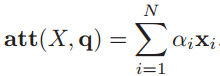
更一般的,可以用**键值对(key-value pair)**来表示输入信息,那么N个输入信息就可以表示为![(K, V)= [(k_1,v_1),(k_2,v_2),...,(k_N,v_N)]](https://img0.php1.cn/3cdc5/6de3/78c/a3b7a47ab2d2f84c.gif)
![(K, V)= [(k_1,v_1),(k_2,v_2),...,(k_N,v_N)]](https://img0.php1.cn/3cdc5/6de3/78c/6fc83b1499f8586d.gif) ,其中“键”用来计算注意分布αi,“值”用来计算聚合信息。
,其中“键”用来计算注意分布αi,“值”用来计算聚合信息。
那么就可以将注意力机制看做是一种软寻址操作:把输入信息X看做是存储器中存储的内容,元素由地址Key(键)和值Value组成,当前有个Key=Query的查询,目标是取出存储器中对应的Value值,即Attention值。而在软寻址中,并非需要硬性满足Key=Query的条件来取出存储信息,而是通过计算Query与存储器内元素的地址Key的相似度来决定,从对应的元素Value中取出多少内容。每个地址Key对应的Value值都会被抽取内容出来,然后求和,这就相当于由Query与Key的相似性来计算每个Value值的权重,然后对Value值进行加权求和。加权求和得到最终的Value值,也就是Attention值。
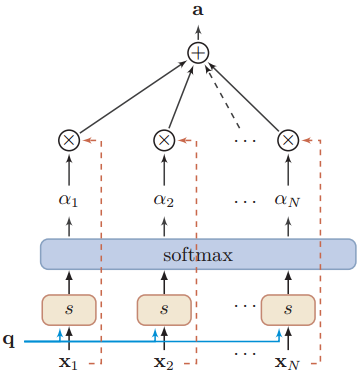
如下图所示,以上的计算可以归纳为三个过程:
第一步:根据Query和Key计算二者的相似度。可以用上面所列出的加性模型、点积模型或余弦相似度来计算,得到注意力得分si;
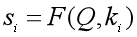
第二步:用softmax函数对注意力得分进行数值转换。一方面可以进行归一化,得到所有权重系数之和为1的概率分布,另一方面可以用softmax函数的特性突出重要元素的权重;
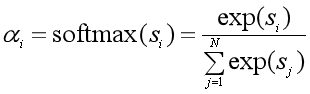
第三步:根据权重系数对Value进行加权求和:
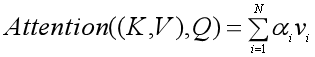
图示如下:
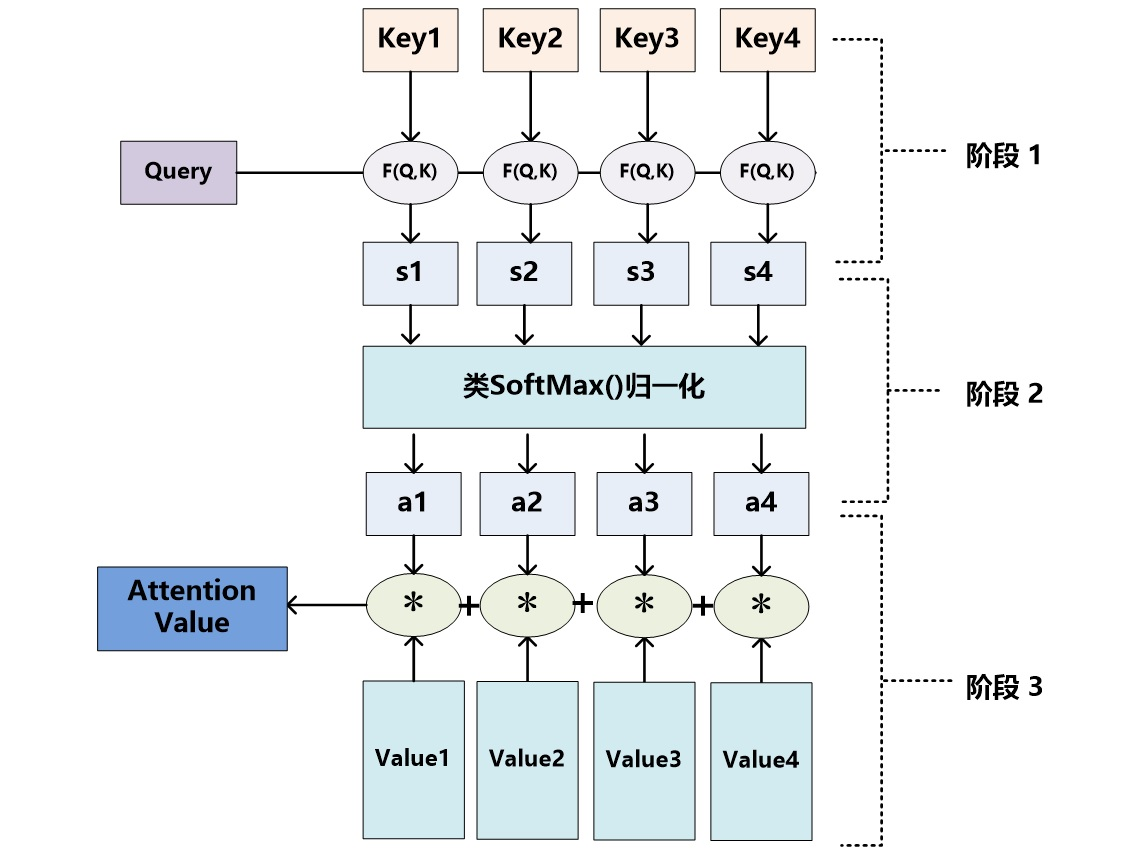
可以把以上的过程用简洁的公式整理出来:
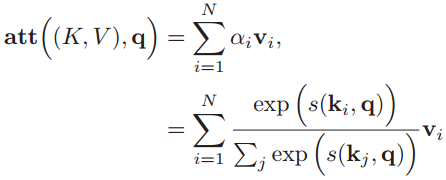
以上就是软性注意力机制的数学原理。
注意力机制是一种通用的思想,本身不依赖于特定框架,但是目前主要和**Encoder-Decoder框架(编码器-解码器)**结合使用。
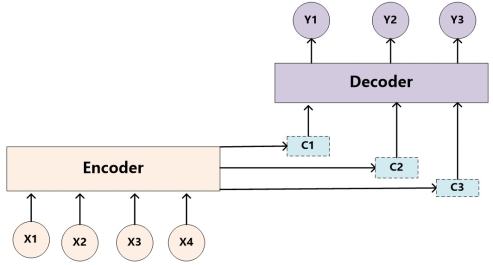
编码器和解码器并非是特定的某种神经网络模型,在不同的任务中会套用不同的模型,比如文本处理和语言识别中常用RNN模型,图形处理中一般采用CNN模型。
(RNN作为编码器和解码器的Encoder-Decoder框架也叫做异步的序列到序列模型,而这就是Seq2Seq模型)
没有引入注意力机制的RNN Encoder-Decoder框架:
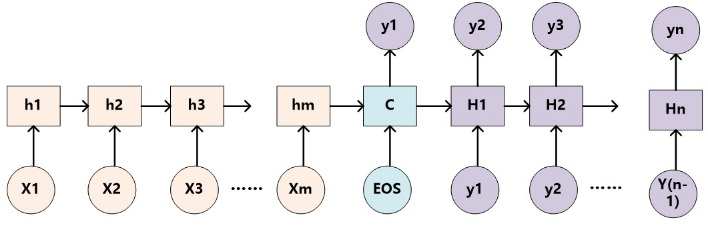
未加入注意力机制的RNN Encoder-Decoder框架在处理序列数据时,可以做到先用编码器把长度不固定的序列X编码成长度固定的向量表示C,再用解码器把这个向量表示解码为另一个长度不固定的序列y,输入序列X和输出序列y的长度可能是不同的。
1、把输入序列X中的元素一步步输入到Encoder的RNN网络中,计算隐状态ht,然后再把所有的隐状态[h1, h2, …, hT]整合为一个语义表示向量c:
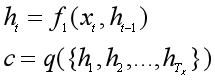
2、Decoder的RNN网络每一时刻t都会输出一个预测的yt。首先根据语义表示向量c、上一时刻预测的yt-1和Decoder中的隐状态st-1,计算当前时刻t的隐状态st:
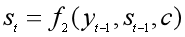
3、由语义表示向量c、上一时刻预测的词yt-1和Decoder中的隐状态st,预测第t个词yt,也就是求下面的条件概率。
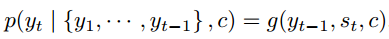
可以看到,在生成目标句子的每一个单词时,使用的语义表示向量c都是同一个,也就说生成每一个单词时,并没有产生[c1,c2,…,cT′]这样与每个输出的单词相对应的多个不同的语义表示。那么在预测某个词yt时,任何输入单词对于它的重要性都是一样的,也就是注意力分散了。
加入注意力机制的RNN Encoder-Decoder
给定一个句子X=[x1,x2,…,xT],通过编码-解码操作后,生成另一种语言的目标句子y=[y1, y2, …, yT′],也就是要计算每个可能单词的条件概率,用于搜索最可能的单词,公式如下:
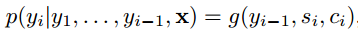
生成第t个单词的过程图示如下:
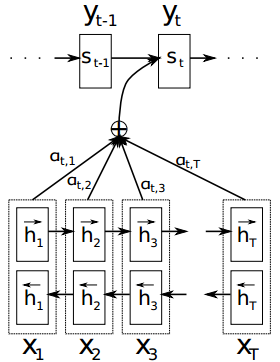
和未加入注意力机制的RNN Encoder-Decoder框架相比,一方面从yi的条件概率计算公式来看,g(•)这个非线性函数中的语义向量表示是随输出yi的变化而变化的ci,而非万年不变的c;另一方面从上图来看,每生成一个单词yt,就要用原句子序列X和其他信息重新计算一个语义向量表示ci,而不能吃老本。
增加了注意力机制的RNN Encoder-Decoder框架的关键就在于,固定不变的语义向量表示c被替换成了根据当前生成的单词而不断变化的语义表示ci。
**第一步:**给定原语言的一个句子X=[x1,x2,…,xT],把单词一个个输入到编码器的RNN网络中,计算每个输入数据的隐状态ht。这篇论文中的编码器是双向RNN,所以要分别计算出顺时间循环层和逆时间循环层的隐状态,然后拼接起来:
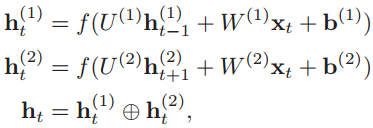
第二步:跳到解码器的RNN网络中,在第t时刻,根据已知的语义表示向量ct、上一时刻预测的yt-1和解码器中的隐状态st-1,计算当前时刻t的隐状态st:
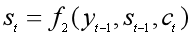
第三步:第2步中的ct还没算出来,咋就求出了隐状态st了?没错,得先求ct,可前提又是得知道st-1:
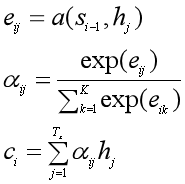
这里的eij就是还没有归一化的注意力得分。a(•)这个非线性函数叫做对齐模型(alignment model),这个函数的作用是把编码器中的每个单词xj对应的隐状态hj,和解码器中生成单词yi的前一个词对应的隐状态si-1进行对比,从而计算出每个输入单词xj和生成单词yi之间的匹配程度。匹配程度越高,注意力得分就越高,那么在生成单词yi时,就需要给与这个输入单词更多的关注。
得到注意力得分eij后,用softmax函数进行归一化,得到注意力概率分布σij。用这个注意力分布作为每个输入单词xj受关注程度的权重,对每个输入单词对应的隐状态hj进行加权求和,就得到了每个生成的单词yi所对应的语义向量表示ci,也就是attention值。
第四步:求出Attention值可不是我们的目的,**我们的目的是求出生成的单词yi的条件概率。**经过上面三步的计算,万事俱备,就可以很舒服地得到单词yi的条件概率:
以上就是一个注意力机制与RNN Encoder-Decoder框架相结合,并用于机器翻译的例子,我们不仅知道了怎么计算Attention值(语言向量表示ci),而且知道了怎么用Attention值来完成机器学习任务。
在软注意力Encoder-Decoder模型中,更具体地来说,在英-中机器翻译模型中,输入序列和输出序列的内容甚至长度都是不一样的,注意力机制是发生在编码器和解码器之间,也可以说是发生在输入句子和生成句子之间。而自注意力模型中的自注意力机制则发生在输入序列内部,或者输出序列内部,可以抽取到同一个句子内间隔较远的单词之间的联系,比如句法特征(短语结构)。
自注意机制是query=key=value只使用内部信息的Attention。普通的Attention机制都是求输出Target句子中某个单词和输入Source句子每个单词之间的相似度,而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制。
显然,Self-Attention更容易捕获句子中长距离的相互依赖的特征,Self-Attention在计算过程中直接将句子中任意两个单词之间的联系通过一个计算结果直接表示,远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
在同一层网络的输入和输出(不是模型最终的输出)之间,利用注意力机制“动态”地生成不同连接的权重,来得到该层网络输出。
前面说了自注意力模型可以建立序列内部的长距离依赖关系,其实通过全连接神经网络也可以做到,但是问题在于全连接网络的连接边数是固定不变的,因而无法处理长度可变的序列。而自注意力模型可以动态生成不同连接的权重,那么生成多少个权重,权重的大小是多少,都是可变的,当输入更长的序列时,只需要生成更多连接边即可。如下图,虚线连接边是动态变化的。
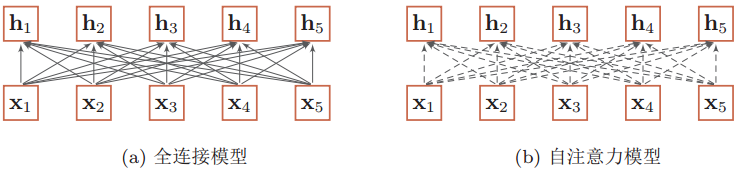
用数学公式来表达自注意力机制:假设一个神经层中的输入序列为X=[x1,x2,…,xN],输出序列为同等长度的H=[h1, h2, …, hN],首先通过线性变换得到三组向量序列:
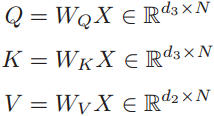
其中Q, K, V 分别为查询向量序列,键向量序列和值向量序列, WQ, WK, WV分别是可以学习的参数矩阵。
于是输出向量hi这样计算:
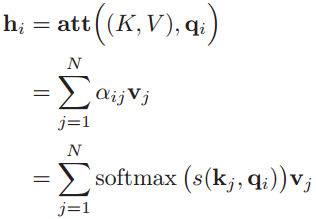
其中 i, j ∈ [1, N]为输出和输入向量序列的位置,连接权重 αij由注意力机制动态生成。
自注意力模型可以作为神经网络的一层来使用,也可以用来替换卷积层或循环层,也可以与卷积层或循环层交叉堆叠使用。
首先,宏观的说一下Transformer的思想。
翻译任务有三种关系:源句内部的关系、目标句内部的关系、源句与目标句之间的关系,原来的模型只学到其中一种,Transformer引入self-attention的机制将三种关系全部做了学习。
Transformer**提出了multi-head attention的机制,分别学习对应的三种关系,使用了全Attention的结构。用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:
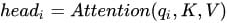
最后再把这些结果拼接起来:
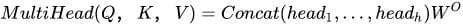
对于词语的位置,Transformer使用positional encoding机制进行数据预处理,增大了模型的并行性,取得了更好的实验效果。
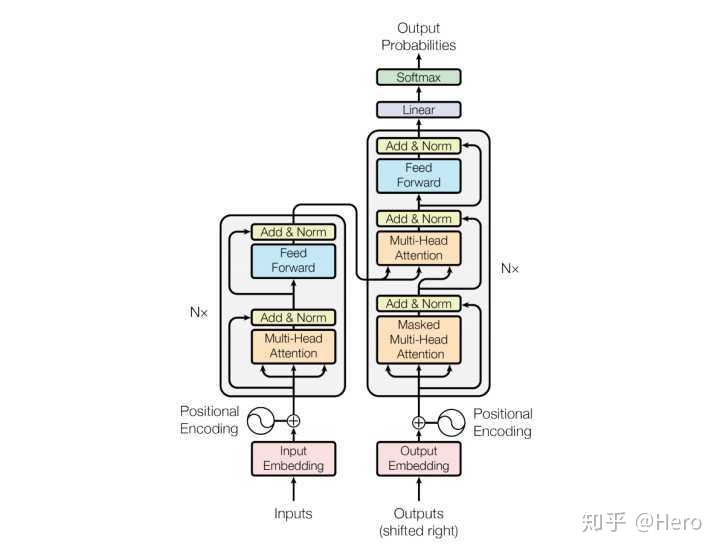
 Decoder
Decoder
Decoder中有三个子层,其中两个multi-head attention层。下面的attention层是利用self-attention学习目标句内部的关系,之后该层输出与encoder传过来的结果一起输入到上面的attention层,这个attention层并不是 self-attention,而是encoder-decoder attention,用来学习源句与目标句之间的关系。对于这个Attention,query代表decoder上一步的输出,key和value是来自encoder的输出。这里值得一提的是,解码过程是像RNN一样一步步生成的,因为要用上一位置的输出当作这一位置attention的query。
最后再经过一个与编码部分类似的feed forward层,就可以得到decoder的输出了。
最近越来越多的文章表明,Transformer能够很好地适应图像数据,有望在视觉届也取得统治地位。
第一篇的应用到的视觉Transformer来自Google,叫Vision Transformer。这篇的名字也很有趣,an image is worth 16x16 words,即一幅图值得16X16个单词。这篇文章的核心想法,就是把一幅图变成16x16的文字,然后再输入Transformer进行编码,之后再用简单的小网络进行下有任务的学习。
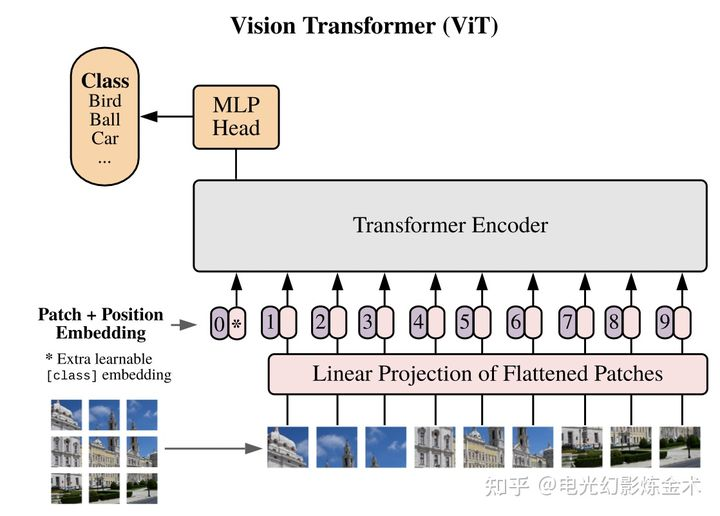
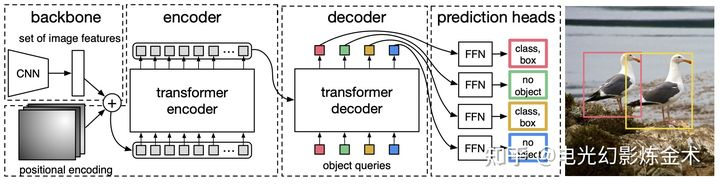
Vision transformer主要是把transformer用于图像分类的任务,那么能不能把transformer用于目标检测呢?Facebook提出的模型DETR(detection transformer)给出了肯定的回答。DETR的模型架构也非常简单,如下图所示,输入是一系列提取的图片特征,经过两个transformer,输出一系列object的特征,然后再通过前向网络将物体特征回归到bbox和cls。
 主要参考:
主要参考:
1.https://www.cnblogs.com/Luv-GEM/p/10712256.html
2.https://easyai.tech/ai-definition/attention/
3.https://zhuanlan.zhihu.com/p/105080984
4.https://zhuanlan.zhihu.com/p/361893386?utm_source=wechat_session&utm_medium=social&utm_oi=1125847523901984769&utm_campaign=shareopn
5.https://zhuanlan.zhihu.com/p/362366192?utm_source=wechat_session&utm_medium=social&utm_oi=1125847523901984769&utm_campaign=shareopn







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 