作者:锦瑟城门 | 来源:互联网 | 2023-09-11 17:57
想象以下代码:
在线试试吧!
uint64_t x = 0x81C6E3292A71F955ULL;
uint32_t y = (uint32_t) (x >> 32);
y接收 64 位整数的较高 32 位部分。我的问题是是否存在任何内在函数或任何 CPU 指令可以在不进行移动和移位的情况下在单个操作中执行此操作?
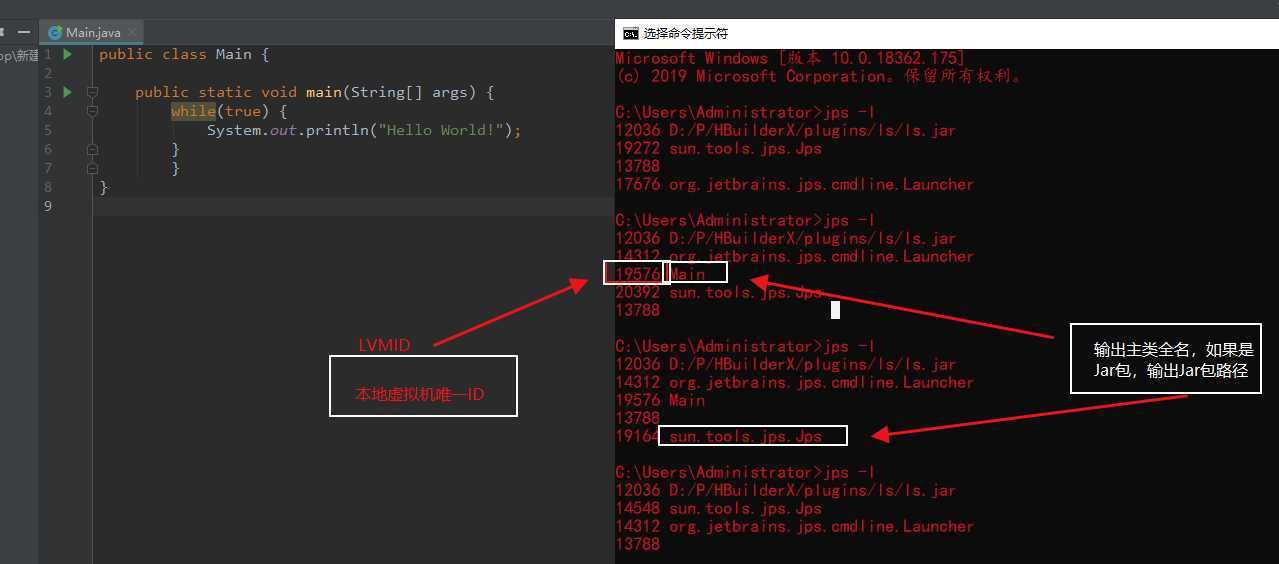
至少铛(在上面挂尝试,它-在线)创建两个指令mov rax, rdi,并shr rax, 32对于这一点,所以无论是铛不会做这样的优化,或不存在这样的特殊指令。
如果存在像movhi dst_reg, src_reg.
回答
如果有更好的方法来对任意 uint64_t 进行位域提取,编译器就会使用它。(至少在理论上;编译器确实错过了优化,他们的选择有时会支持延迟,即使它花费更多的 uops。)
对于无法用纯 C 语言以编译器已经很容易理解的方式有效表达的内容,您只需要内在函数。 (或者,如果您的编译器很笨,无法发现明显的情况。)
您可以想象输入值来自两个 32 位值相乘的情况,那么在某些 CPU 上编译器使用加宽mul r32已经在两个单独的 32 位寄存器中生成结果可能是值得的,而不是imul r64, r64+ shr reg,32, 如果它可以轻松使用 EAX/EDX。但是除了gcc -mtune=silvermont其他调整选项之外,您不能让编译器这样做。
shr reg, 32具有 1 个周期延迟,并且可以在大多数现代 x86 微体系结构 ( https://uops.info/ )上的 1 个以上执行端口上运行。唯一可能希望的是它可以将结果放在不同的寄存器中,而不会覆盖输入。
大多数现代非 x86 ISA 都类似于 RISC,具有 3 个操作数指令,因此移位指令可以复制和移位,这与 x86 移位不同,编译器mov除了shr稍后还需要原始 64 位值之外,还需要一个,或者(在一个小函数的情况下)需要不同寄存器中的返回值。
并且一些 ISA 具有位域提取指令。PowerPC 甚至有一个有趣的旋转和屏蔽指令 ( rlwinm)(屏蔽是由立即数指定的位范围),它与正常移位指令不同。编译器将根据需要使用它 - 不需要内在函数。 https://devblogs.microsoft.com/oldnewthing/20180810-00/?p=99465
带有BMI2 的rorx rax, rdi, 32x86必须复制和旋转,而不是在同一寄存器内卡住移位。uint32_t在不内联的独立版本中,返回的函数可以/应该使用它而不是 mov+shr,因为调用者已经不得不忽略 RAX 中的高垃圾。(x86-64 System V 和 Windows x64 都将返回值定义为仅与 arg 的 C 类型匹配的寄存器宽度;例如,返回uint32_t意味着 RAX 的高 32 位不是返回值的一部分,并且可以容纳任何内容。通常它们为零,因为写入一个 32 位寄存器隐式地零扩展到 64,但是像return bar()bar 返回 uint64_t这样的东西可以让 RAX 保持不变而不必截断它;实际上优化的尾调用是可能的。)
没有内在的 for rorx; 编译器应该知道什么时候使用它。(但是 gcc/clang-O3 -march=haswell错过了这个优化。) https://godbolt.org/z/ozjhcc8Te
如果编译器在循环中执行此操作,则它可以32在寄存器中shrx reg,reg,reg作为复制和移位。或者更傻,它可以使用pext与0xffffffffULL <<32作为面膜。但这更糟糕,shrx因为延迟更高。
AMD TBM(仅限推土机系列,而非 Zen)具有bextr(位域提取)的直接形式,并且它以 1 uop 的速度高效运行(https://agner.org/optimize/)。 https://godbolt.org/z/bn3rfxzch显示 gcc11 -O3 -march=bdver4(挖掘机)使用bextr rax, rdi, 0x2020,而 clang 错过了该优化。 gcc -march=znver1使用 mov + shr 是因为 Zen 删除了尾随位操作以及 XOP 扩展。
标准 BMI1bextr需要寄存器中的位置/长度,而在英特尔 CPU 上是 2 uop,因此它是垃圾。它确实有一个内在的,但我建议不要使用它。 mov+shr在 Intel CPU 上速度更快。






 京公网安备 11010802041100号
京公网安备 11010802041100号