作者:mobiledu2502887427 | 来源:互联网 | 2023-05-19 16:29
小编给大家分享一下python爬虫案例之如何获取招聘要求,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
大致流程如下:
1.从代码中取出pid
2.根据pid拼接网址 => 得到 detail_url,使用requests.get,防止爬虫挂掉,一旦发现爬取的detail重复,就重新启动爬虫
3.根据detail_url获取网页html信息 => requests - > html,使用BeautifulSoup
若爬取太快,就等着解封
if html.status_code!=200
print('status_code if {}'.format(html.status_code))4.根据html得到soup => soup
5.从soup中获取特定元素内容 => 岗位信息
6.保存数据到MongoDB中
代码:
# @author: limingxuan
# @contect: limx2011@hotmail.com
# @blog: https://www.jianshu.com/p/a5907362ba72
# @time: 2018-07-21
import requests
from bs4 import BeautifulSoup
import time
from pymongo import MongoClient
headers = {
'accept': "application/json, text/Javascript, */*; q=0.01",
'accept-encoding': "gzip, deflate, br",
'accept-language': "zh-CN,zh;q=0.9,en;q=0.8",
'content-type': "application/x-www-form-urlencoded; charset=UTF-8",
'COOKIE': "JSESSIOnID=""; __c=1530137184; sid=sem_pz_bdpc_dasou_title; __g=sem_pz_bdpc_dasou_title; __l=r=https%3A%2F%2Fwww.zhipin.com%2Fgongsi%2F5189f3fadb73e42f1HN40t8~.html&l=%2Fwww.zhipin.com%2Fgongsir%2F5189f3fadb73e42f1HN40t8~.html%3Fka%3Dcompany-jobs&g=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1531150234,1531231870,1531573701,1531741316; lastCity=101010100; toUrl=https%3A%2F%2Fwww.zhipin.com%2Fjob_detail%2F%3Fquery%3Dpython%26scity%3D101010100; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1531743361; __a=26651524.1530136298.1530136298.1530137184.286.2.285.199",
'origin': "https://www.zhipin.com",
'referer': "https://www.zhipin.com/job_detail/?query=python&scity=101010100",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
}
conn = MongoClient('127.0.0.1',27017)
db = conn.zhipin_jobs
def init():
items = db.Python_jobs.find().sort('pid')
for item in items:
if 'detial' in item.keys(): #当爬虫挂掉时,跳过已爬取的页
continue
detail_url = 'https://www.zhipin.com/job_detail/{}.html'.format(item['pid']) #单引号和双引号相同,str.format()新格式化方式
#第一阶段顺利打印出岗位页面的url
print(detail_url)
#返回的html是 Response 类的结果
html = requests.get(detail_url,headers = headers)
if html.status_code != 200:
print('status_code is {}'.format(html.status_code))
break
#返回值soup表示一个文档的全部内容(html.praser是html解析器)
soup = BeautifulSoup(html.text,'html.parser')
job = soup.select('.job-sec .text')
print(job)
#???
if len(job)<1:
continue
item[&#39;detail&#39;] = job[0].text.strip() #职位描述
location = soup.select(".job-sec .job-location .location-address")
item[&#39;location&#39;] = location[0].text.strip() #工作地点
item[&#39;updated_at&#39;] = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()) #实时爬取时间
#print(item[&#39;detail&#39;])
#print(item[&#39;location&#39;])
#print(item[&#39;updated_at&#39;])
res = save(item) #调用保存数据结构
print(res)
time.sleep(40)#爬太快IP被封了24小时==
#保存数据到MongoDB中
def save(item):
return db.Python_jobs.update_one({&#39;_id&#39;:item[&#39;_id&#39;]},{&#39;$set&#39;:item}) #why item ???
# 保存数据到MongoDB
if __name__ == &#39;__main__&#39;:
init()
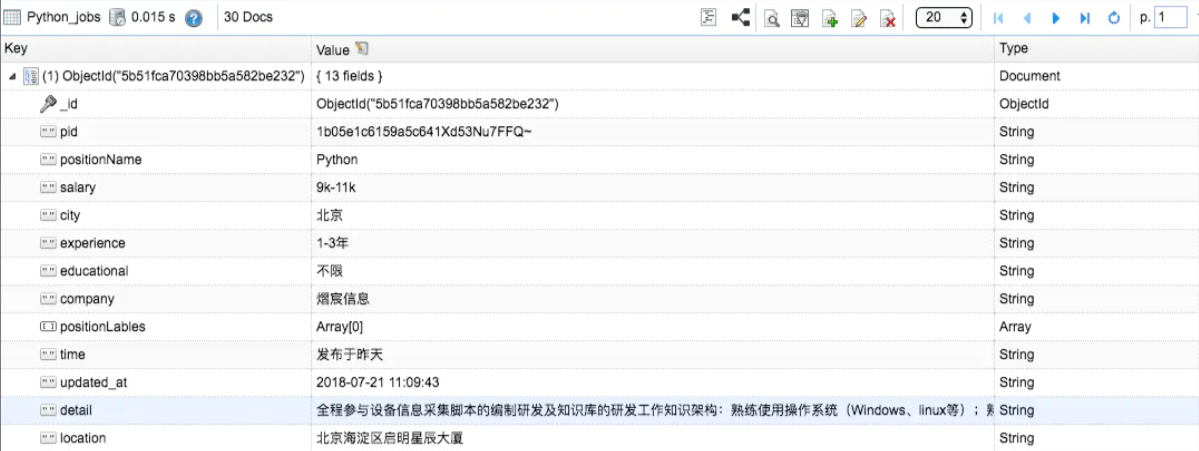
最终结果就是在MongoBooster中看到新增了detail和location的数据内容
以上是python爬虫案例之如何获取招聘要求的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注编程笔记行业资讯频道!
![Python3爬虫入门:pyspider的基本使用[python爬虫入门]](https://img1.php1.cn/3cdc5/324f/339/9d0ec9721f26646a.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号