自2007年以来,亚马逊已售出数千万台Kindle,令人印象深刻。但这也意味着数以千万计的人可能会因为这些 Kindle 中的软件漏洞而被黑客入侵。他们的设备可能会变成机器人,或者他们的私人本地网络可能会受到损害,甚至他们的账单帐户中的信息也可能会被盗,当然也可以植入游戏、金融等诈骗广告到这些被控制的kindle中,危险性不言而喻。
远程访问用户 Kindle 的最简单方法是通过电子书。恶意图书可以通过“自助出版”服务发布并在任何虚拟图书馆(包括 Kindle 商店)中免费访问,或通过亚马逊“发送到 Kindle”服务直接发送到最终用户设备。
虽然你可能对某本书的写作不满意,但没有人希望下载到的书中带有病毒。没有公开这样的场景。防病毒软件没有电子书的签名。
但是……已经可以成功制作恶意的书。如果你在 Kindle 设备上打开这本书,它可能会导致一段隐藏的代码以 root 权限执行。从这一刻起,您可以假设您已经失去了对电子阅读器的控制。
2021 年 4 月,kindle 5.13.5 版本前的 Kindle 固件中都存在这个漏洞。
基本上,Kindle OS 是一个 Linux 内核,其中包含主要由 busybox 提供的一组本机程序、用于进程间通信的 LIPC 子系统以及用于用户界面 (UI) 和服务的 Java 和 Webkit 子系统。
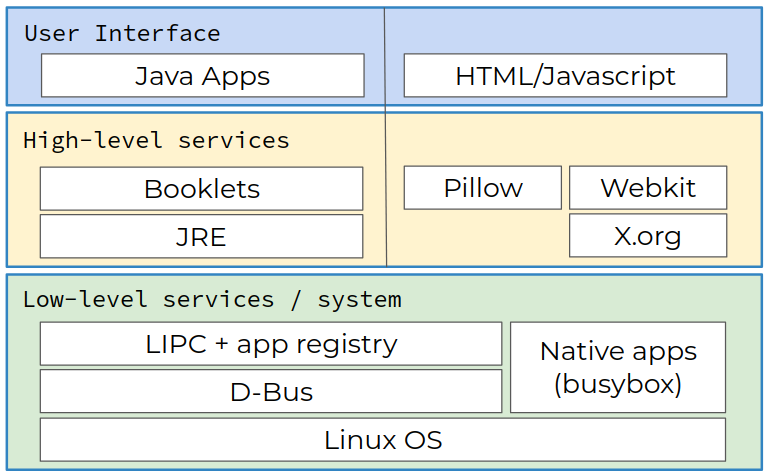
图 1: Kindle Touch 架构。
LIPC 是一个基于 D-Bus 的 IPC 库及其将所有 Kindle 组件链接在一起的环境。Kindle 进程可以使用此库来启动应用程序、公开应用程序属性/设置、侦听或发出事件。例如,用 HTML 和 Javascript 编写的 Webkit 应用程序可以使用 LIPC 与 Java 服务或本机应用程序交互。
大多数 UI 是用 Java 编写的。Java 子系统(框架)为服务和 UI(所谓的小册子)提供 LIPC 处理程序。比如 Kindle 主页 UI 窗口就是com.lab126.booklet.home框架管理的小册子。
Webkit 子系统(HTML5 和 Javascript)是另一种创建 UI 元素的方法。内置的实验浏览器是 Webkit 子系统的一部分。Pillow 是一个允许从 Javascript 访问 LIPC 的库。
Kindle 电子阅读器固件最新版本(5.13.4)已在亚马逊官方网站公开下载。源代码也部分可用。但源代码对我们的研究没有帮助,因为它主要由第三方开源项目组成,包括 Linux 内核,并在亚马逊上进行了小幅调整。负责解析和呈现电子书的组件没有源代码。
我们的第一个目标是发现电子书解析框架中的漏洞。为此,我们有足够的固件文件,不需要真正的 Kindle 设备。
让我们看看负责处理电子书的组件。
这/mnt/us/documents是常规电子书目录,当您在 Kindle 设备上下载新书时。谁将首先处理文件?
该/usr/bin/scanner服务会定期扫描文档目录中的新文件,并根据文件扩展名使用“提取器”库之一从电子书中提取元数据。所有提取器都列在/var/local/appreg.dbsqlite 数据库中。每种支持的 Kindle 电子书格式都有一个处理程序:
| 文件格式 | 提取器 |
| 外汇 | /usr/lib/ccat/libyjextractorE.so |
| azw1, tpz | /usr/lib/ccat/libtopazE.so |
/usr/lib/ccat/libpdfE.so | |
| azw3 | /usr/lib/ccat/libmobi8extractorE.so |
| azw、mbp、mobi、prc | /usr/lib/ccat/libEBridge.so |
如果扫描仪与文件扩展名不匹配或出现解析错误,则不会向用户显示电子书。
我们没有深入研究扫描过程,因为提取元数据的操作过于简单,无法提示解析错误。
扫描仪完成工作后,主屏幕上会显示新书的缩略图。从这一刻起,Java 框架负责在您单击这本书时打开它。可以在/opt/amazon/ebook/lib固件目录中找到实现打开和呈现电子书的逻辑的 Java 存档 (JAR) 文件。首先,这些都是MobiReader-impl.jar,YJReader-impl.jar,PDFReader-impl.jar,HTMLReader-impl.jar和TopazReader-impl.jar文件。
为了进一步研究,我们决定将注意力集中在 PDF 文件格式上,因为它是最常见但同时也是复杂的格式之一。
我们来看看PDFReader-impl.jar(com.amazon.ebook.booklet.pdfreader.impl.PDFModel类)中PDF书籍打开功能的实现:
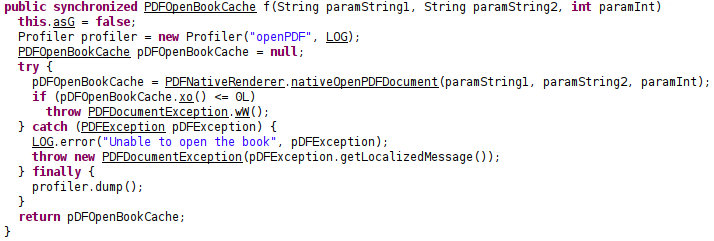
如您所见,此函数只是对nativeOpenPDFDocument具有/usr/java/lib/libPDFClientJNI.so库中主体的本机函数的包装。
该nativeOpenPDFDocument函数启动PDF服务器/usr/bin/pdfreader,分叉进程,并通过开源HTTP客户端/服务器库向其同步发送“openBook”消息/usr/lib/libsoup-2.4.so。实际上,它向 发送 GET 请求https://127.0.0.1:7667/command/openBook。
该pdfreader服务器是我们研究的主要对象。最终,我们将在此过程的上下文中运行我们的有效负载。
在启动时,pdfreader服务器通过setuid调用将自身降低到“框架”用户(uid 9000)的权限。然后它启动一个侦听端口 7667 的汤服务器,为高级 PDF 操作定义了数十个处理程序,包括我们感兴趣的“openBook”和“startRendering”。
该/usr/lib/libFoxitWrapper.so库由 Amazon 编写,提供了用于工作的 API与 PDF 文件。将pdfreader在其汤处理器使用这个库。例如,“openBook”处理程序如下所示:
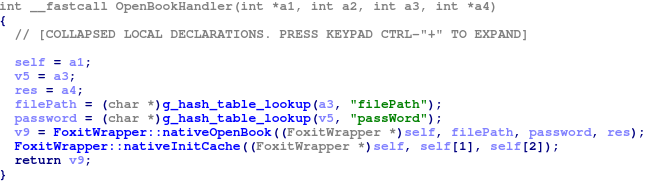
请注意该libFoxitWrapper.so库的以下重要功能:
openPDFDocumentFromLibrary(char *file, char* password, uint32_t* handle) – 打开 PDF 文档。getCurrentPage(uint32_t handle, uint32_t page, uint32_t flag) – 将 PDF 页面解析为内部结构。renderPageFromLibrary(uint32_t handle, uint32_t page, uint32_t width, uint32_t height, float scale, uint8_t landscape, uint8_t* out)– 渲染 PDF 页面,将其转换为图像。当被调用时,流过滤器开始被解析。这些函数是对 PDF 树结构进行模糊测试的良好切入点。
顾名思义,它libFoxitWrapper.so是/usr/lib/libfpdfemb.so库提供在 Kindle 设备上的流行 Foxit PDF SDK 的包装器。这libfpdfemb.so是 Foxit Software Inc. 专有的闭源库。可以在 Internet 上找到 Foxit Embedded PDF SDK 手册。
我们试图从libFoxitWrapper.so库中对上述函数进行模糊测试,但这种方法没有带来任何结果,除了一组空指针异常。一种更有前景的 PDF 格式方法是选择一个特定对象或流过滤器作为测试目标。因此,我们决定对libfpdfemb.so库进行模糊测试。
但首先,让我们来看看经典的模糊测试模型。
模糊任何闭源库的最简单方法是编写一个可执行文件,将库加载到内存中并调用目标函数。这个加载器将一个带有排列数据的文件作为命令行参数,读入它,并将数据传递给被测函数。接下来,加载器被检测或在模拟器上运行,以收集每个测试用例的代码覆盖矩阵。第三方模糊器/置换器之一用于根据覆盖矩阵生成新的测试用例。
为了对libfpdfemb.so库进行模糊测试,我们选择了 American Fuzzy Lop (AFL) 和 Quick emulator (Qemu) 的组合。主机是Ubuntu。
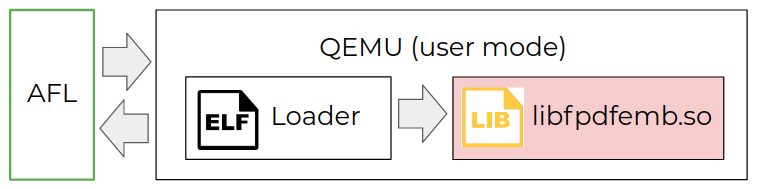
图 2:模糊测试方案。
我们还需要注意一件事。Kindle 设备基于 ARM 处理器。因此,我们的加载器是使用arm-linux-gnueabi-g++. Qemu 很容易在 x86 上模拟 ARM。
一个简单的搜索在单词“CPDF”和“解码器”libfpdfemb.so库使我们能够找出所有可能的流过滤器/解码器:Predictor,Decrypt,Flate,Fax,Lzw,AsciiHex,RunLen,Ascii85,Jpeg,Jbig2和Jpx。让我们用一个例子来看看其中的一个。
图 3:带有 jbig2 过滤器的 PDF 页面片段。
如您所见,Im1声明了带有 jbig2 过滤器的图像。Jbig2 是一种用于双层图像的图像压缩标准。jbig2 编码器将输入页面分割为多个区域:文本、半色调图像、细化等。这些区域保存在JBIG2Globals流中。渲染 PDF 页面时,libfpdfemb.so解析JBIG2Globals流并重建图像。
库中Jbig2Module定义的对象libfpdfemb.so负责解码 jbig2 压缩图像。
图 1: Kindle Touch 架构。
LIPC 是一个基于 D-Bus 的 IPC 库及其将所有 Kindle 组件链接在一起的环境。Kindle 进程可以使用此库来启动应用程序、公开应用程序属性/设置、侦听或发出事件。例如,用 HTML 和 Javascript 编写的 Webkit 应用程序可以使用 LIPC 与 Java 服务或本机应用程序交互。
大多数 UI 是用 Java 编写的。Java 子系统(框架)为服务和 UI(所谓的小册子)提供 LIPC 处理程序。比如 Kindle 主页 UI 窗口就是com.lab126.booklet.home框架管理的小册子。
Webkit 子系统(HTML5 和 Javascript)是另一种创建 UI 元素的方法。内置的实验浏览器是 Webkit 子系统的一部分。Pillow 是一个允许从 Javascript 访问 LIPC 的库。
Kindle 电子阅读器固件最新版本(5.13.4)已在亚马逊官方网站公开下载。源代码也部分可用。但源代码对我们的研究没有帮助,因为它主要由第三方开源项目组成,包括 Linux 内核,并在亚马逊上进行了小幅调整。负责解析和呈现电子书的组件没有源代码。
我们的第一个目标是发现电子书解析框架中的漏洞。为此,我们有足够的固件文件,不需要真正的 Kindle 设备。
让我们看看负责处理电子书的组件。
这/mnt/us/documents是常规电子书目录,当您在 Kindle 设备上下载新书时。谁将首先处理文件?
该/usr/bin/scanner服务会定期扫描文档目录中的新文件,并根据文件扩展名使用“提取器”库之一从电子书中提取元数据。所有提取器都列在/var/local/appreg.dbsqlite 数据库中。每种支持的 Kindle 电子书格式都有一个处理程序:
| 文件格式 | 提取器 |
| 外汇 | /usr/lib/ccat/libyjextractorE.so |
| azw1, tpz | /usr/lib/ccat/libtopazE.so |
/usr/lib/ccat/libpdfE.so | |
| azw3 | /usr/lib/ccat/libmobi8extractorE.so |
| azw、mbp、mobi、prc | /usr/lib/ccat/libEBridge.so |
如果扫描仪与文件扩展名不匹配或出现解析错误,则不会向用户显示电子书。
我们没有深入研究扫描过程,因为提取元数据的操作过于简单,无法提示解析错误。
扫描仪完成工作后,主屏幕上会显示新书的缩略图。从这一刻起,Java 框架负责在您单击这本书时打开它。可以在/opt/amazon/ebook/lib固件目录中找到实现打开和呈现电子书的逻辑的 Java 存档 (JAR) 文件。首先,这些都是MobiReader-impl.jar,YJReader-impl.jar,PDFReader-impl.jar,HTMLReader-impl.jar和TopazReader-impl.jar文件。
为了进一步研究,我们决定将注意力集中在 PDF 文件格式上,因为它是最常见但同时也是复杂的格式之一。
我们来看看PDFReader-impl.jar(com.amazon.ebook.booklet.pdfreader.impl.PDFModel类)中PDF书籍打开功能的实现:
如您所见,此函数只是对nativeOpenPDFDocument具有/usr/java/lib/libPDFClientJNI.so库中主体的本机函数的包装。
该nativeOpenPDFDocument函数启动PDF服务器/usr/bin/pdfreader,分叉进程,并通过开源HTTP客户端/服务器库向其同步发送“openBook”消息/usr/lib/libsoup-2.4.so。实际上,它向 发送 GET 请求https://127.0.0.1:7667/command/openBook。
该pdfreader服务器是我们研究的主要对象。最终,我们将在此过程的上下文中运行我们的有效负载。
在启动时,pdfreader服务器通过setuid调用将自身降低到“框架”用户(uid 9000)的权限。然后它启动一个侦听端口 7667 的汤服务器,为高级 PDF 操作定义了数十个处理程序,包括我们感兴趣的“openBook”和“startRendering”。
该/usr/lib/libFoxitWrapper.so库由 Amazon 编写,提供了用于工作的 API与 PDF 文件。将pdfreader在其汤处理器使用这个库。例如,“openBook”处理程序如下所示:
请注意该libFoxitWrapper.so库的以下重要功能:
openPDFDocumentFromLibrary(char *file, char* password, uint32_t* handle) – 打开 PDF 文档。getCurrentPage(uint32_t handle, uint32_t page, uint32_t flag) – 将 PDF 页面解析为内部结构。renderPageFromLibrary(uint32_t handle, uint32_t page, uint32_t width, uint32_t height, float scale, uint8_t landscape, uint8_t* out)– 渲染 PDF 页面,将其转换为图像。当被调用时,流过滤器开始被解析。这些函数是对 PDF 树结构进行模糊测试的良好切入点。
顾名思义,它libFoxitWrapper.so是/usr/lib/libfpdfemb.so库提供在 Kindle 设备上的流行 Foxit PDF SDK 的包装器。这libfpdfemb.so是 Foxit Software Inc. 专有的闭源库。可以在 Internet 上找到 Foxit Embedded PDF SDK 手册。
我们试图从libFoxitWrapper.so库中对上述函数进行模糊测试,但这种方法没有带来任何结果,除了一组空指针异常。一种更有前景的 PDF 格式方法是选择一个特定对象或流过滤器作为测试目标。因此,我们决定对libfpdfemb.so库进行模糊测试。
但首先,让我们来看看经典的模糊测试模型。
模糊任何闭源库的最简单方法是编写一个可执行文件,将库加载到内存中并调用目标函数。这个加载器将一个带有排列数据的文件作为命令行参数,读入它,并将数据传递给被测函数。接下来,加载器被检测或在模拟器上运行,以收集每个测试用例的代码覆盖矩阵。第三方模糊器/置换器之一用于根据覆盖矩阵生成新的测试用例。
为了对libfpdfemb.so库进行模糊测试,我们选择了 American Fuzzy Lop (AFL) 和 Quick emulator (Qemu) 的组合。主机是Ubuntu。
图 2:模糊测试方案。
我们还需要注意一件事。Kindle 设备基于 ARM 处理器。因此,我们的加载器是使用arm-linux-gnueabi-g++. Qemu 很容易在 x86 上模拟 ARM。
一个简单的搜索在单词“CPDF”和“解码器”libfpdfemb.so库使我们能够找出所有可能的流过滤器/解码器:Predictor,Decrypt,Flate,Fax,Lzw,AsciiHex,RunLen,Ascii85,Jpeg,Jbig2和Jpx。让我们用一个例子来看看其中的一个。
图 3:带有 jbig2 过滤器的 PDF 页面片段。
如您所见,Im1声明了带有 jbig2 过滤器的图像。Jbig2 是一种用于双层图像的图像压缩标准。jbig2 编码器将输入页面分割为多个区域:文本、半色调图像、细化等。这些区域保存在JBIG2Globals流中。渲染 PDF 页面时,libfpdfemb.so解析JBIG2Globals流并重建图像。
库中Jbig2Module定义的对象libfpdfemb.so负责解码 jbig2 压缩图像。

 转存失败重新上传取消
转存失败重新上传取消
图 4: Jbig2Module对象。
其StartDecode方法声明如下:

在其他过滤器中,我们使用StartDecode函数作为入口点对 jbig2 解码算法进行了模糊测试,并排列了图像大小(width和height参数)、图像流(src_buf, src_size)和JBIG2Globals流(global_data, global_size)。您可以在下面看到我们用来调用StartDecode. 基变量是libfpdfemb.so库在内存中的地址。
结果,我们在JBIG2Globals解码算法中发现了一个有价值的堆溢出漏洞。
让我们看一下以下JBIG2Globals流:
图 5:格式错误的JBIG2Globals流。
这里定义了两个页面区域:
((width + 31) >> 5) <<2。这是一个格式错误的流。在细化区域中定义了一个超大的矩形。
在这种情况下会发生什么?该算法尝试将基础图像扩展到新的维度。新图像的高度重新计算为height + y,并(height + y) * stride为调整大小的图像分配堆内存。但是扩展函数中有一个错误导致堆溢出:INT_MAX在计算新图像的内存大小时错过了检查。32 位寄存器溢出,为图像分配 0x100 字节而不是 0x400000100。

图6:该expand功能。
这意味着通过使用细化区域,我们可以“细化”图像之外的数据,并获得任意写入原语。在以下示例中,第二个细化区域从堆中的图像开始处以 0x1234 * 0x10 字节的偏移量覆盖 0x10(跨步)字节。数据 blob(0x71 到 0x79 字节)由 jbig2 算法解压缩,然后与堆内容进行异或。
图 7:受控堆溢出。
我们可以创建任意数量的细化区域并覆盖彼此相距一定距离的部分内存。此外,写入是通过 XOR 操作完成的这一事实允许我们仅修复内存的特定位,而不是整个字,并在需要时绕过 ASLR 保护。
如前所述,libfpdfemb.so库是该pdfreader过程的一部分。这个进程的数据段和堆段是读/写/执行的。ASLR 内置于 Linux 内核中,由参数控制/proc/sys/kernel/randomize_va_space。它在 Kindle 设备上的默认值为 1,这意味着数据段的基地址紧跟在可执行代码段的末尾之后。换句话说,数据段和堆没有随机化。这两个事实使得利用发现的 jbig2 漏洞变得微不足道。
我们现在在pdfreader流程的上下文中存在 RCE 漏洞。用户将 PDF 书下载到他的 Kindle 设备。当这本书被打开时,会启动一个恶意负载。
该pdfreader进程具有框架用户权限:uid=9000(framework) gid=150(javausers) groups=150(javausers). 它可以发送 LIPC 消息,访问特殊的内部文件,但它仍然是有限的。我们想成为 root 来重置所有限制。
因此,研究的第二阶段是找到一个 LPE 漏洞,该漏洞允许框架用户在 root 用户下运行代码。
首先,我们越狱了我们的一个 Kindle,因为仅仅从固件中获取文件来搜索逻辑 LPE 是不够的。我们需要查看正在运行的进程和打开的端口,并能够调试 Kindle 服务。
可以在 Internet 上找到某些版本的 Kindle 固件的软件越狱。但最通用的方式是通过串口越狱。虽然这需要拆卸设备,但这就是我们所做的。

图 8:通过串口越狱 Kindle。
我们拿到了一个越狱的设备,然后分析了拥有root权限的服务,以及它们访问的资源。最终,我们在 Kindle 服务中发现了一个逻辑错误,或者更准确地说,是权限管理不当。太好了,无需对设备驱动程序进行模糊测试。
框架用户对/var/tmp/framework目录具有完全访问权限,他可以在其中创建任何可执行文件。实际上,这是用户的工作目录。例如,我们可以创建一个payload.sh记录用户权限的 bash 脚本文件:
框架用户对/var/local/appreg.dbsqlite 数据库具有读/写访问权限,该数据库本质上是一个应用程序注册表。这意味着我们可以使用/usr/lib/libsqlite3.so库或简单地编辑文件来修复数据库条目。我们想要修补表中的“命令”条目之一properties。
图 9:中的 properties表格appreg.db。
例如,我们可以修补条目com.lab126.browser:将value字段设置为/var/tmp/framework/payload.sh而不是/usr/bin/mesquite。以下 SQL 请求完成工作:

框架可以请求由appmgrd服务代表的应用程序管理器启动任意应用程序。我们可以发送 LIPC 消息以使用/usr/lib/liblipc.so库打开浏览器应用程序。此 shell 命令执行相同的操作:
应用程序管理器负责启动内置应用程序。为此,它会侦听适当的 LIPC 事件。要启动浏览器应用程序,它会com.lab126.browser从 中读取条目appreg.db,并执行该value字段中指定的命令。当我们修补这个数据库条目时,我们的payload.sh脚本就启动了。
该appmgrd服务具有根权限。“root: uid=0(root) gid=0(root)”字符串由payload.sh.
所描述的 LPE 漏洞可以很容易地从pdfreader我们拥有的进程中利用。在libsqlite3.so和liblipc.so库已经加载到进程的内存。通过结合发现的两个漏洞,任何恶意负载都可以以 root 身份运行。
上面演示了电子书如何充当恶意软件。由于恶意软件代码是以 root 用户权限执行的,打开这样的书可能会导致无法弥补的损害。攻击者可能删除了您的电子书,可能获得对您亚马逊帐户的完全访问权限,可能将您的 Kindle 转换为机器人,攻击您本地网络中的其他设备,等等。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有