作者:没有丝袜姑娘 | 来源:互联网 | 2023-06-24 12:45
一、模型
优先队列是允许至少下列两种操作的数据结构:insert(插入),以及deleteMin(删除最小者),函数的作用是找出、返回并删除优点队列中最小的元素。insert操作等价于enqueue(入队),而deleteMin则是队列运算dequeue(出队)在优点队列中的等价操作。
二、简单实现
有几种明显的方法实现优先队列。我们可以使用一个简单链表在表头以O(1)执行插入操作,并且遍历该链表以删除最小元,但是这需要O(N)时间。另一种方法是,始种让链表保持排序状态,这使得插入代价高昂O(N),而deleteMin花费低廉O(1)。基于deleteMin的操作从不多于插入操作的事实,前者是更好的想法。
另一种实现优点队列的方法是使用二叉查找树,它对这两种操作的平均运行时间都是O(logN)。尽管插入是随机的,而删除则不是,但这个结论还是成立的。但是由于我们删除的唯一元素是最小元。反复初去左子树中的节点将会损害树的平衡,使得右子树加重。然而,右子树是随机的。在最坏的情形,即deleteMin将左子树删空的情形下,右子树拥有的元素最多也就是它应具有的元素数的两倍。这只是在它的期望深度上加了一个小常数。注意,通过使用平衡树,可以把这个界变成最坏情形的界,这将防止出现坏的插入序列。
使用查找树可能有些过头,因为它支持许许多多并不需要的操作。
三、二叉堆
二叉堆以最坏时间O(logN)支持insert和deleteMin两种操作。插入操作实际上将平均花费常数时间,若无删除操作的干扰,该结构的实现将以线性时间建立一个具有N项的优先队列。
类似二叉查找树,堆也有两个性质,即结构性和堆序性。恰似AVL树,对堆的一次操作可能破坏这两个性质中的一个,因此,堆的操作必须到堆的所有性质都被满足时才能终止。
3.1 结构性质
堆是一颗被完全填满的二叉树,有可能的例外是在底层,底层上的元素从左到右填入。这样的树称为完全二叉树。
下图是一个例子:
容易证明,一颗高为h的完全二叉树有2h2^h2h到2h+1−12^{h+1}-12h+1−1。同时一个重要的观察发现,因为完全二叉树这么有规律,所以它可以用一个数组表示而不需要使用链。
下图中的数组对应上图中的堆:

对于数组中任一位置i上的元素,其左儿子在2i上,右儿子在左儿子后的单元(2i+1)中,它的父亲则在位置i/2上。因此,这里不仅不需要链,而且遍历该树所需要的操作也极为简单,在大部分计算机上运行很可能都非常快。这种实现的唯一问题在于,最大的堆大小需要事先估计,但一般这并不成问题(而且如果需要,可以重新调整大小)。
因此,一个堆结构可以有一个(comparable对象的)数组和一个代表当前堆的大小的整数组成。
3.2 堆序性质
使操作被快速执行的性质是堆序性质。由于我们想要能够快速地找出最小元,因此最小元应该在根上。如果考虑任意子树也应该是一个堆,那么任意节点就应该小于它的所有后裔。
应用这个逻辑,我们得到堆序性质。在一个堆中,对于每一个节点X,X的父亲中的关键字小于(或等于)X中的关键字,根节点除外(它没有父亲)。
下图中左边的树是一个堆,但是右面的树不是:
根据堆序性质,最小元总可以在根处找到。因此,我们以常数时间得到附加操作findMin
3.3 基本的堆操作
3.3.1 insert(插入)
为将一个元素X插入到堆中,我们在下一个可用位置创建一个空穴(hole),因为如果不创建空穴的话堆将不是完全树。如果X可以放在该空穴而并不破坏堆的序,那么插入完成。否则,我们把空穴的父节点上的元素移入该空穴中,这样,空穴就朝着根的方向上冒一步。继续该过程直到X能被放入空穴中为止。
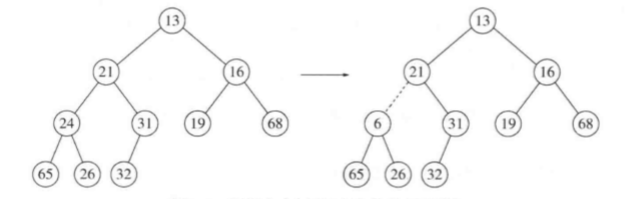
下图表示为了插入14,我们在堆的下一个可用位置建立一个空穴。由于将14插入空穴破坏了堆序性质,因此将31移入该空穴。
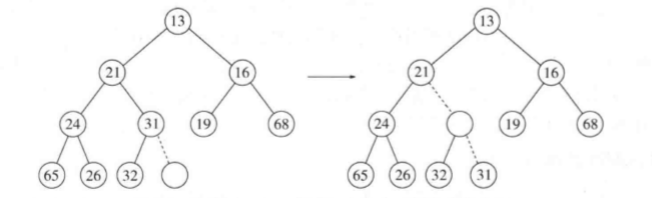
继续这个过程,直到找到14的正确位置:
这种一般的策略叫做上滤。新元素在堆中上滤直到找出正确的位置。
其实我们可以在insert例程中通过反复实施操作直至建立正确的序来实现上滤过程,可是一次交换需要3条赋值语句。如果一个元素上滤d层,那么由于交换而实施的赋值操作就达到3d,而我们这里的方法只用到d+1次赋值。
如果要插入的元素是新的最小值,那么它将一直被推向顶端。这样一来会在某一时刻hol==1,程序跳出循环。如果欲插入元素是新的最小元而一直上滤到根处,那么这种插入的时间将长达O(logN)。平均来看,上滤终止的要早。现在已经证明,执行一次插入平均需要2.607次比较,因此平均insert将元素上移1.607层。
3.3.2 deleteMin(删除最小元)
deleteMin以类似插入的方式处理。找出最小元是容易的,困难的是删除它。当删除一个最小元时,要在根节点建立一个空穴。由于现在的堆少了一个元素,因此堆中最后一个元素X必须移动到该堆的某个地方。如果X可以被放到空穴中,那么deleteMin完成,不过这一般不太可能,因此我们将空穴的两个儿子中较小者移入空穴,这样就把空穴向下推了一层。重复该步骤直到X可以被放入空穴中。因此,我们的做法是将X置入沿着从根开始包括最小儿子的一条路径上的一个正确的位置。
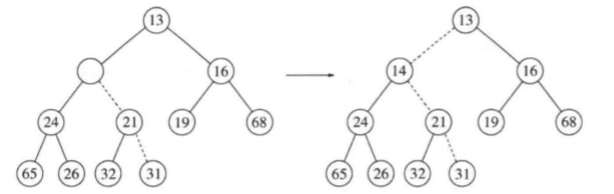
下图中左边的图现实deleteMin之前的堆。删除13后,我们必须试图正确地将31放到堆中。31不能放在空穴中,因为这将破坏堆序性质。于是,我们把较小的儿子14置入空穴,同时空穴向下滑一层。重复该过程,由于31大于19,因此把19置入空穴,在更下一层上建立一个新的空穴。然后,因为31还是太大,于是再把26置入空穴,在底层又建立一个新的空穴。最后,我们得以将31置入空穴中。这种一般的策略叫做下滤。
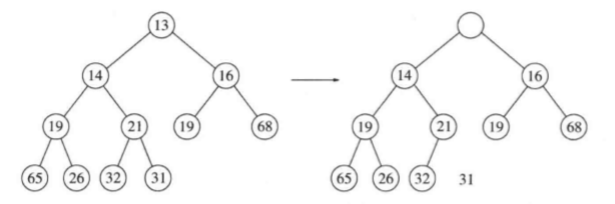
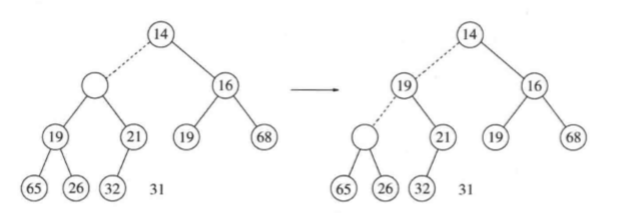
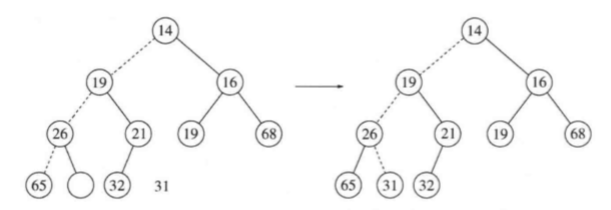
这种操作最坏情形运行时间为O(logN)。平均而言,被放到根处的元素几乎下滤到堆的底层,因此平均运行时间为O(logN)。
四、优先队列的应用
4.1 选择问题
输入N个元素以及一个整数k,这N个元素可以是排序过的。我们需要找出第k个最大的元素。
4.1.1 算法A
为了简单起见,假设只考虑找出第k个最小的元素。该算法很简单:将N个元素读入一个数组。然后对该数组应用buildHeap算法。最后,执行k次deleteMin操作。从该堆最后提取的元素就是我们的答案。
使用buildHeap构造堆的最坏情形用时是O(N),而每次deleteMin用时O(logN)。由于有k次deleteMin,因此得到总的运行时间为O(N+klogN)。
4.1.2 算法B
在任一时刻我们都将保留k个最大元素的集合S。在前k个元素读入以后,当再读入一个新的元素时,该元素将与第k个最大元素进行比较,记这个第k个最大的元素为SkS_kSk。注意,SkS_kSk是S中最小的元素。如果新的元素更大,那么用新元素代替S中的SkS_kSk。此时,S将有一个新的最小元素,它可能是新添加进的元素,也可能不是。在输入完成时,我们找到了S中最小的元素,将其返回,就是我们需要的答案。
这里使用一个堆来实现S。前k个元素通过调用一次buildHeap以总时间O(k)被置入堆中。处理每个其余的元素的时间为O(1),用于检测是否元素进入S,再加入时间O(logk),用于在必要时删除SkS_kSk并插入新元素。因此,总的时间是O(k+(N-k)logk)=O(Nlogk)。该算法也给出找出中位数的时间界O(NlogN)。










 京公网安备 11010802041100号
京公网安备 11010802041100号