# 定义损失函数———交叉熵 with tf.name_scope("loss"):cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices = [1]))tf.summary.scalar('cross_entropy', cross_entropy) # 计算准确率 with tf.name_scope("accuracy"):correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) # 定义优化器——Adagrad,和学习率:0.3 with tf.name_scope("train"): train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy)
⑦ 框架搭好了,正式开始计算
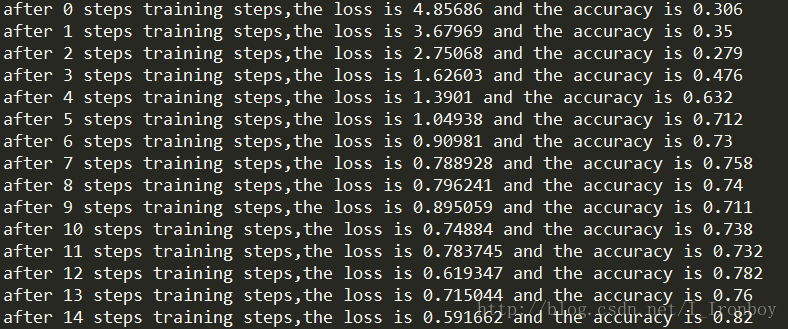
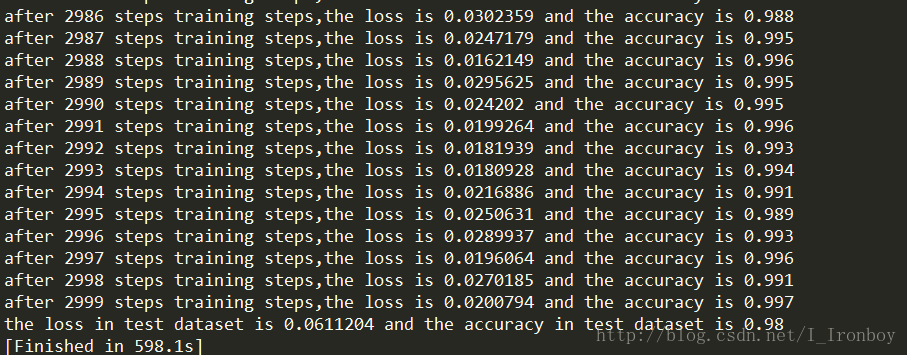
# 初始化所有的变量 init = tf.global_variables_initializer() # 开始导入数据,正式计算,迭代3000步,训练时batch size=100 with tf.Session() as sess:sess.run(init)merge = tf.summary.merge_all()writer = tf.summary.FileWriter("log",sess.graph)for i in range(3000):batch_xs,batch_ys = mnist.train.next_batch(1000)sess.run(train_step,feed_dict = {x:batch_xs,y_:batch_ys,keep_prob:0.75})loss_run = sess.run(cross_entropy,feed_dict = {x:batch_xs,y_:batch_ys,keep_prob:0.75})accuracy_run = sess.run(accuracy,feed_dict = {x:batch_xs,y_:batch_ys,keep_prob:0.75})print('after %d steps training steps,the loss is %g andthe accuracy is %g'%(i,loss_run,accuracy_run))result = sess.run(merge,feed_dict = {x:batch_xs,y_:batch_ys,keep_prob:1})writer.add_summary(result,i)# 训练完后直接加载测试集数据,进行测试if i == 2999:loss_run = sess.run(cross_entropy,feed_dict = {x:mnist.test.images,y_:mnist.test.labels,keep_prob:1})accuracy_run = sess.run(accuracy,feed_dict = {x:mnist.test.images,y_:mnist.test.labels,keep_prob:1})print('the loss in test dataset is %g andthe accuracy in test dataset is %g'%(loss_run,accuracy_run))
5 .运行结果:
… …
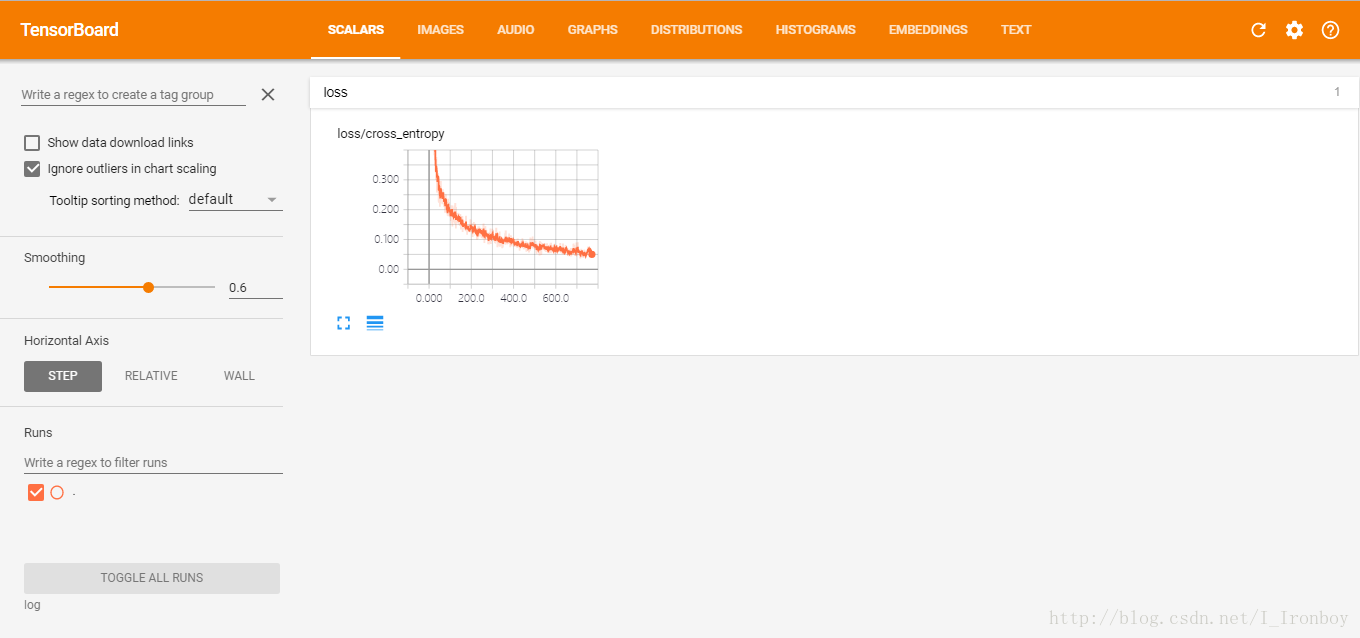
测试集上的准确度:98.00%
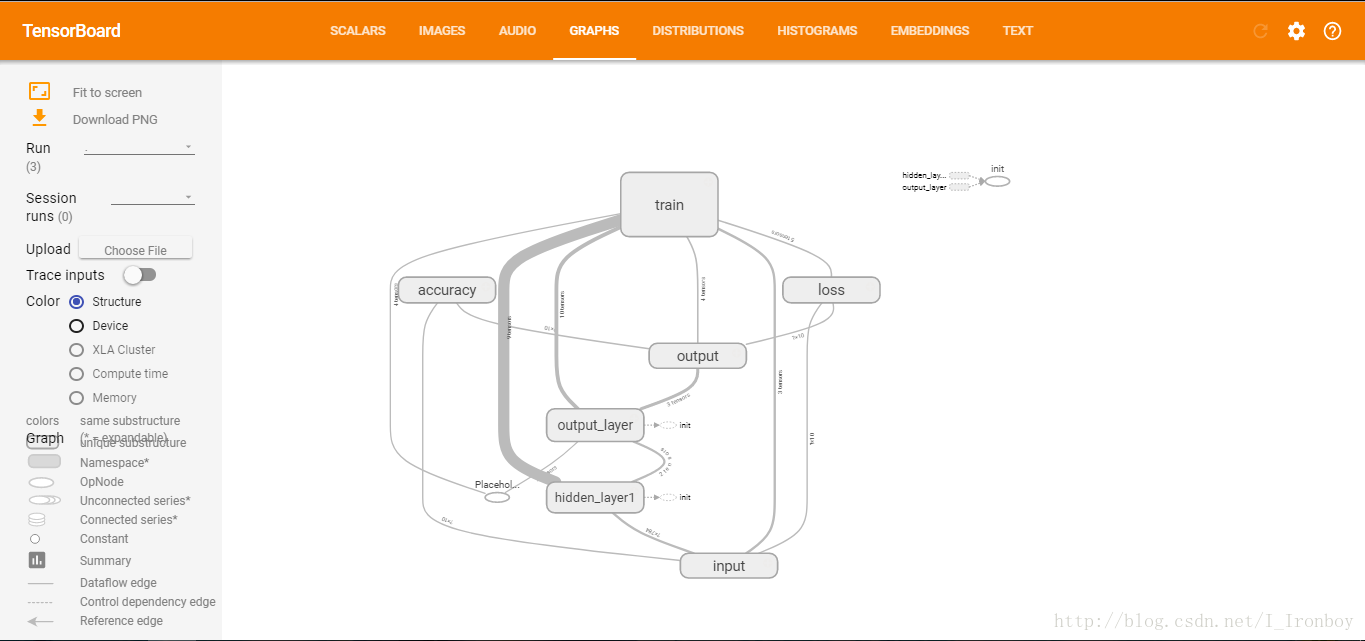
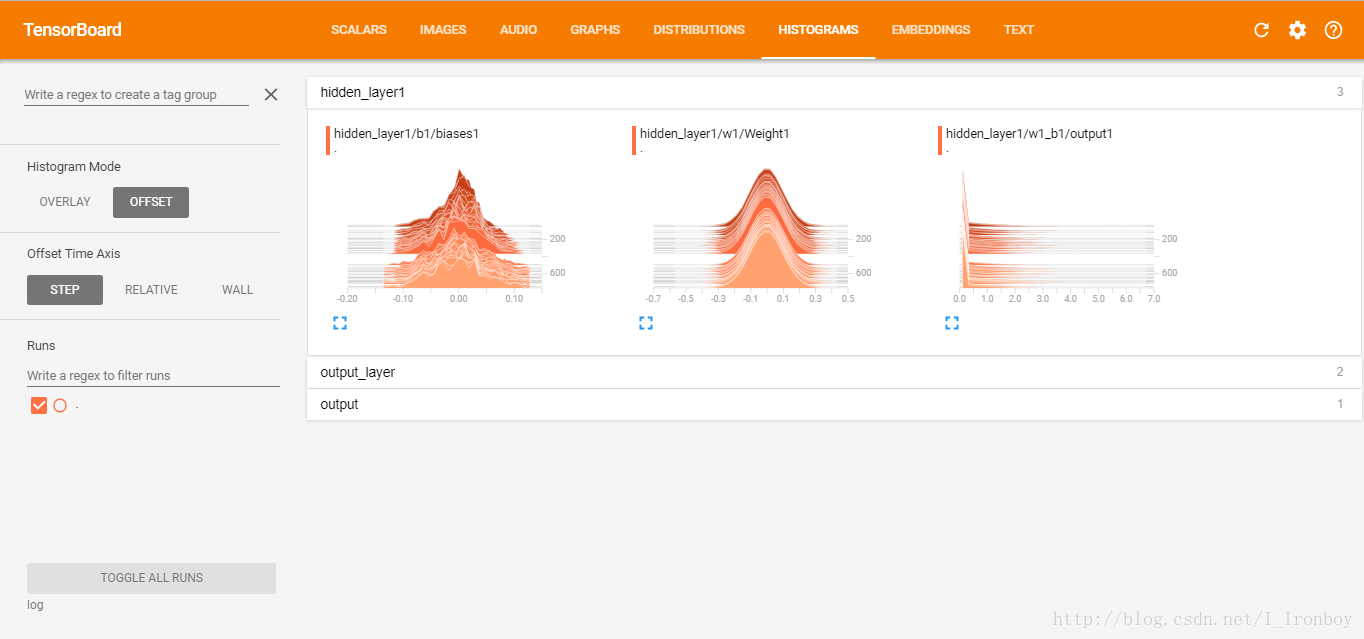
6. TensorBoard可视化:
① 在MLP.py程序的所在文件夹下打开cmd窗口(针对Windows)
方法一:打开cmd,然后用“cd + 路径”的方式找到该位置
方法二:定位到MLP.py所在文件的位置,点击左上角的“文件”,然后点击“打开命令提示符”
② 输入: tensorboard - -logdir=log ,回车
③ 复制上面的地址到浏览器,如我这上面的地址是:http://Ironboy:6006 ④ 可视化结果:
本文对比了杜甫《喜晴》的两种英文翻译版本:a. Pleased with Sunny Weather 和 b. Rejoicing in Clearing Weather。a 版由 alexcwlin 翻译并经 Adam Lam 编辑,b 版则由哈佛大学的宇文所安教授 (Prof. Stephen Owen) 翻译。 ...
[详细]








 京公网安备 11010802041100号
京公网安备 11010802041100号