作者:myldd | 来源:互联网 | 2023-01-28 11:42
上周在旧金山举行的2019英特尔人工智能峰会上(IntelAISUMMIT2019),英特尔公司副总裁兼人工智能产品事业部总经理NaveenRao表示今年英特尔的AI收入预计将达到
上周在旧金山举行的2019英特尔人工智能峰会上(Intel AI SUMMIT 2019),英特尔公司副总裁兼人工智能产品事业部总经理Naveen Rao表示今年英特尔的AI收入预计将达到35亿美元(约为245亿元)。这个数据有两方面的意义,一方面是英特尔2017年的AI收入为10亿美元,2019年的AI收入如果符合预期意味着英特尔的AI营收两年增长了250%。另一方面,在业界都在探索AI落地的当下,英特尔AI营收的快速增长将给业界一些参考意义。

市场需要什么样的AI芯片?
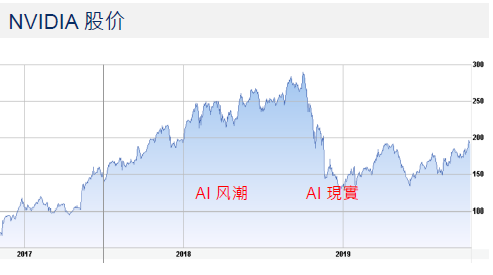
这一次AI的热潮,英特尔的CPU和英伟达的GPU最先受益,有意思的是,如果用以GPU为主要营收的英伟达的股价来看AI的发展,可以看到从2016年左右AI芯片火热开始,英伟达的股价一路上升,这也是AI持续火热的几年。2018年底,英伟达股价开始大跌,经历了几次涨跌至今仍未回到2018年的高点,这一时期伴随的是AI大规模落地的探索,我们可以将这视为AI的现实。
AI专用芯片
与英伟达一样,英特尔在这几年也享受到了AI带来的收入,股价几经涨跌,也在探索AI的落地好的途径。Naveen Rao在2019英特尔人工智能峰会上演讲时表示,在AI的领域里,很难靠一个单一的技术和一种方式或者一个系统支撑,而是需要ABCS (Approach, Budget,Chip, System),即途径、预算、芯片和系统。并且,企业在AI发展的过程中,所处的位置是不一样的。
Naveen Rao意思很明确,企业对于AI的需求不同,需要不同的产品以及产品组合去满足。英特尔的AI收入也反应出了多种AI芯片的价值,2017年英特尔超过10亿美元的AI收入来自于在数据中心使用英特尔至强处理器运行AI应用,而2019年35亿美元的AI收入则来自多个AI产品,其中就包括上周宣布商用的NNP。
今年8月,英特尔公布了两款新一代 AI 芯片,Nervana NNP-T 和 Nervana NNP-I。Nervana NNP-T主要用于深度学习训练,采用了台积电16nm FF+ 制程工艺,集成270 亿个晶体管,硅片面积 680 平方毫米,支持 TensorFlow、PaddlePaddle、PYTORCH 训练框架,也支持 C++ 深度学习软件库和编译器 nGraph。

Nervana NNP-I用于大型数据中心的推理芯片,基于10nm工艺和 Ice Lake 内核打造, 英特尔表示它在 ResNet50 的效率可达 4.8TOPs/W,功率范围在 10W 到 50W 之间。
上周的峰会上,Naveen Rao公布了NNP的性能,NNP-I1000对比英伟达T4有3.7倍的性能优势。
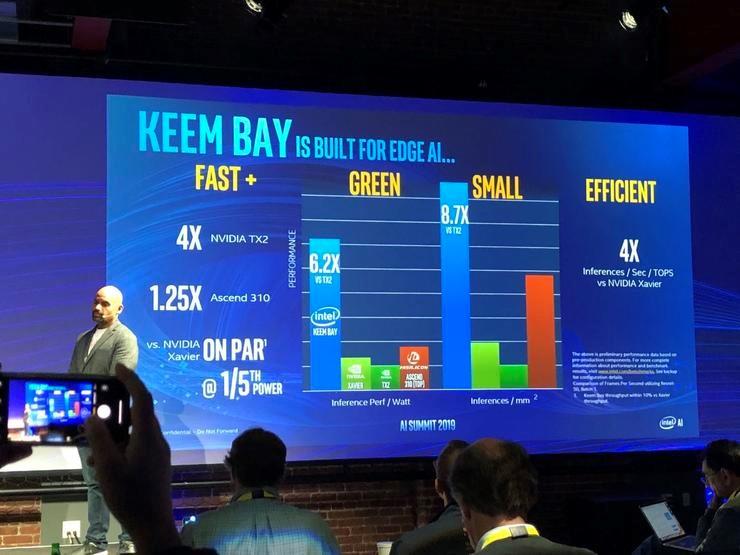
除了应用于云端NNP,上周英特尔还发布了新一代Movidius VPU,代号是Keem Bay,面向边缘端AI市场。新一代VPU采用全新的高效能架构,并且通过英特尔的 OpenVINO 来加速。与上一代VPU相比,其推理性能有10倍提升。英特尔公司物联网事业部副总裁、视觉市场和渠道部门总经理Jonathan Ballon表示,在早期的试验中,新一代VPU性能是英伟达 TX2 的 4 倍,是华为海思 Ascend 310 的 1.25 倍。能效方面,对英伟达TX2有6.2倍优势,比英伟达Xavier和华为昇腾310也优势明显。
据悉,Nervana神经网络处理器现已投入生产并完成客户交付,新一代的VPU计划在2020年上半年上市。百度人工智能研究员Kenneth Church表示,NNP-T用在了X-Man 4.0(百度的超级计算机)上,用了32个NNP-T每机架的产品。下一代的AI,我们会使用更多英特尔的产品,配合百度在AI方面的想法,包括OAI(Open Accelerator Infrastructure)开放加速器架构。
NNP-I则获得了Facebook的采用,Facebook人工智能系统协同设计总监Misha Smelyanskiy表示,“在我看来,NNP-I和GLOW之间的配合,可以确保可以让计算机视觉等等的工作负载,能够更加的更加节约能源,更加高性能和更加优化的方式来加以处理。”
显然,走在AI前沿的科技公司们需要专为AI设计的云端和边缘端芯片。但英特尔和英伟达在新一轮AI浪潮中率先获得的收入证明成熟的CPU和GPU同样能够在AI时代继续发挥作用。
传统芯片的AI价值
英特尔的AI收入从CPU开始,并在不断提升至强可扩展处理器的AI性能,比如通过VNNI(英特尔矢量神经网络指令)可以将推理性能提升三倍。Naveen Rao透露,下一代至强可扩展处理器Cooper Lake,增加了对bfloat16的支持,可以用来做一些非常复杂的深度学习的这种模型的训练和推理,而且在这样的模式之下可以跨CPU、加速器等接触到使用到更多的工具包,训练的性能有很大的提高。
CPU在AI推理中能够体现优势,但并不擅长AI训练,擅长并行计算的GPU则优势明显。英特尔明年要发布独立GPU已经不是什么秘密,在2019年超级计算大会上,英特尔宣布专为高性能计算和人工智能融合优化的全新独立通用GPU。

雷锋网(公众号:雷锋网)了解到,此次展示的是基于英特尔Xe架构的新类别通用GPU,代号Ponte Vecchio,将采用英特尔7纳米工艺进行制造,使用Foveros 3D和嵌入式多芯片互连桥接(EMIB)创新封装技术,以及多种其它技术,如高带宽存储器、CXL互连技术以及其它专利技术。
英特尔高级副总裁、首席架构师,兼架构、图形与软件部门总经理Raja M. Koduri在展前发布会上表示,Xe图形架构非常灵活,可以做到从低功耗领域到高性能计算领域的全覆盖,一种架构,多种微架构,通用编程模型。
当然,类型齐全的AI处理器还少不了FPGA。本月,英特尔发布了目前全球密度最高的FPGA,全新Stratix 10 GX 10M,拥有1020万个逻辑单元,433亿颗晶体管,现已量产,即日出货。全新FPGA针对ASIC原型设计与仿真市场,可加快下一代5G、AI、网络ASIC验证与创新。
如何实现AI收入的快速增长?
显然,英特尔AI收入的增加很重要的一个原因就是齐全的AI芯片类型,这能够让其更大程度的满足市场对AI芯片的需求。不过,更为关键的还是在于软件。这不仅是因为软件离用户最近,能够决定用户的使用门槛。还因为在AI时代,业界都意识到异构多核架构对于AI落地的意义,如何降低异构系统的编程复杂度并提升异构硬件系统的效率非常关键。
英特尔所做的是提供统一的软件平台,其称为oneAPI。同样是在2019年超级计算大会上,英特尔发布了全新软件行业计划oneAPI,这个行业计划是为跨多种包括CPU、GPU、FPGA和其他加速器在内的异构计算,提供了一个统一和简化的应用程序开发编程模型。oneAPI包括了一项基于开放规范的行业计划和一款beta产品,oneAPI beta产品为开发者提供了全套的开发工具,包括编译器、编程库、分析器等,并把这些工具封装为特定领域的工具包。

Raja M. Koduri表示,高性能计算和人工智能工作负载需要包括CPU、通用GPU、FPGA,到本月初英特尔展示的更加专用的深度学习芯片NNP在内的多种架构。帮助客户更简便地释放不同计算环境的潜力至关重要,英特尔致力于采取软件先行的策略,为多架构提供统一可扩展的功能加速异构创新。
随着oneAPI计划的发布以及拥有了完整的AI芯片组合,雷锋网认为英特尔的AI收入将会快速增长。在透露更多关于GPU消息的同时,英特尔就表示其以数据为中心的芯片产品组合和oneAPI计划,为阿贡国家实验室“极光”(Aurora)系统中百亿亿次级计算的高性能计算和人工智能工作负载奠定了基础。

具体而言,“极光”的计算节点架构将由两个10纳米英特尔至强可扩展处理器(代号“Sapphire Rapids”)和六个Ponte Vecchio GPU共同组成。该系统同时还将支持超过10PB的内存和超过230PB的存储容量,并能通过Cray Slingshot技术连接超过200个机架的节点。
这也就意味着,英特尔参与AI竞争的时候的优势在于其拥有类型全面的AI芯片,并且,通过统一的软件平台oneAPI,尽可能降低AI应用的门槛,来加速AI的发展。更进一步,通过制程、封装、架构、存储、互连、安全、软件的六大技术战略,英特尔将不仅会局限于AI,而是构建在更大范围内的以数据为中心时代的竞争力。
相关文章:
解读英特尔边缘大计及物联网生态第四阶段部署重点
英特尔首席架构师Raja:未来10年计算架构的优化和提升将比过去50年还多
。




 京公网安备 11010802041100号
京公网安备 11010802041100号