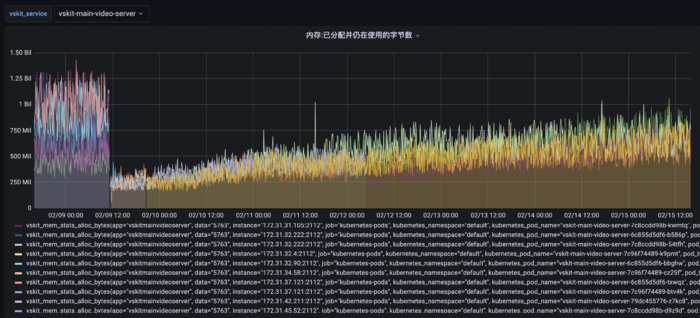
服务部署后内存总体呈上升趋势
二、排查过程
通过go tool pprof收集了三天内存数据
2月11号数据:
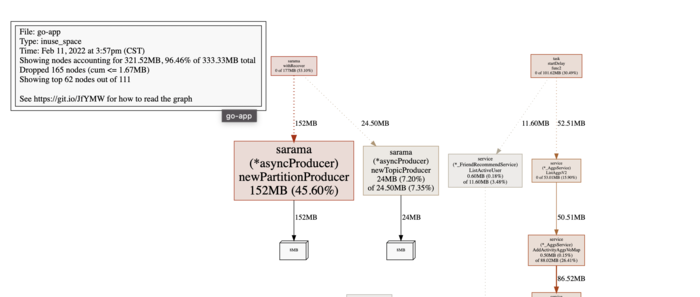
2月14号数据:
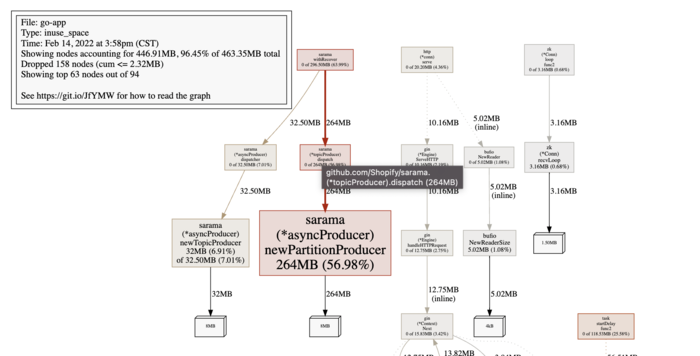
2月15号数据:
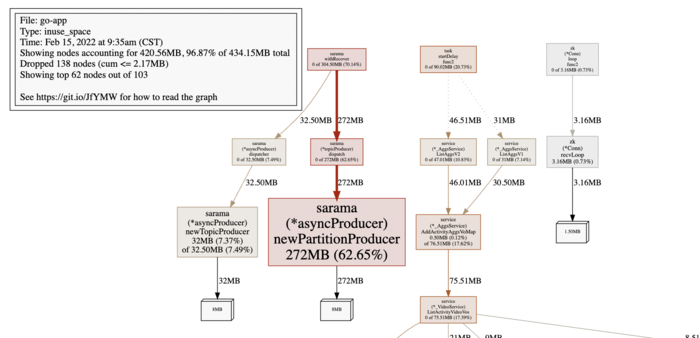
可以看到newPartitionProducer持续增长,可定位到是kafka的问题。而newPartitionProducer是分区生产者,因此查看分区相关的数据。
最近增加的topic:ai_face_process_topic,这个是AI换脸的,每生成一个视频都要通过Kafka中转消息到视频处理服务器。
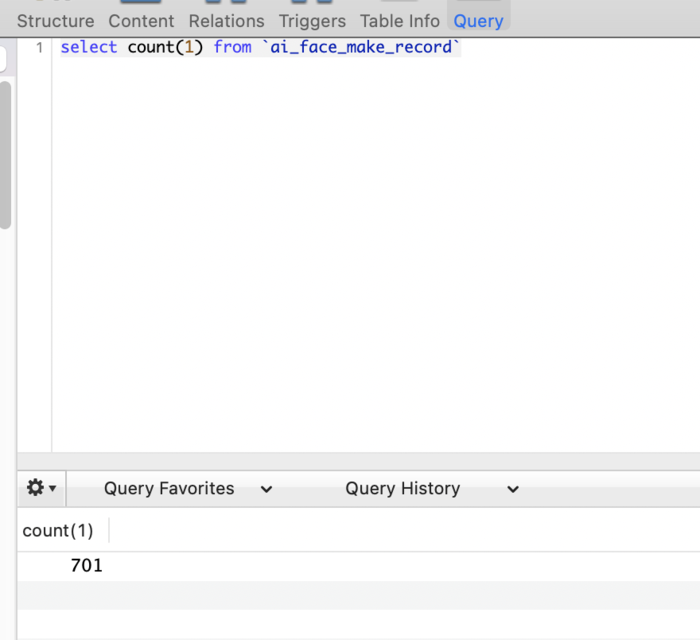
查阅数据库看视频生成记录。2022.1.25上线到今天2022.2.15一共20天,只增长了701个视频,平均每天35个视频。
但这个topic有64个分区。这是因为视频生成过程比较耗时,当时考虑到需要提高并发量,所以需要分区数比较多。
查看sarama客户端的API代码,给每个分区发消息时会判断这个分区的handler是否存在,不存在则创建。
sarama创建partition handler的关键代码:
handler := tp.handlers[msg.Partition] if handler == nil {
handler = tp.parent.newPartitionProducer(msg.Topic, msg.Partition)
tp.handlers[msg.Partition] = handler
}
|
且创建后需要手动close,否则内存一直占用,这是官方说明:
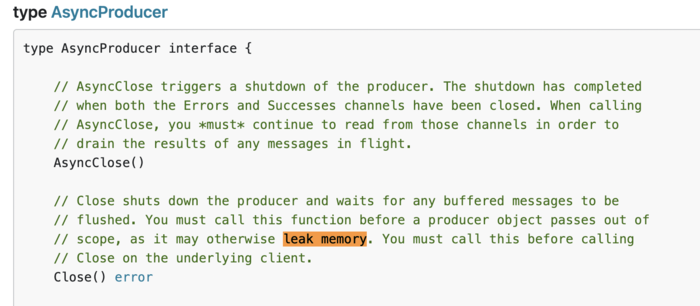
而我们使用sarama客户端的producer是全局的,一直不会close,所以会一直占用内存。
再看看我们使用sarama的partitioner是NewRandomPartitioner,即每条消息随机匹配到partition。
这样,按照每天三十多的视频生成量,出现前几天新增分配二三十个handler,逐渐减少,直到分配完64个handler。
每个handler会分配8MB内存,也就出现了上面的内存数据:152MB,264MB,172MB。
三、结论与优化
内存增长几天稳定后则不会继续增长。
其他分区数比较多的topic没有观察到内存持续增长情况是因为数据量比较大,服务启动没多久就分配完了每个分区的handler。
优化:
单个AI换脸视频处理服务耗时较长,决定了我们需要比较大的并发量,所以后面分区数还可能增加。而64个分区已经使每个服务占用64*8=504MB内存,严重影响扩展性。
因此后面ai_face_process_topic考虑迁移到redis做消息中转。
四、参考链接:
sarama API
githup sarama memory leak问题
kafka memory leak问题






 京公网安备 11010802041100号
京公网安备 11010802041100号