作者:Andyxiesz | 来源:互联网 | 2023-08-27 11:04
叶子圣-第二次作业这个作业属于哪个课程https:edu.cnblogs.comcampusfzzcxyZhichengSoftengineeringPracticeFclass这
叶子圣-第二次作业
这个作业属于哪个课程 |
https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/ |
|---|
这个作业要求在哪里 |
https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/homework/12532 |
这个作业的目标 |
<爬虫> |
Github 地址 |
https://gitee.com/yezisheng0614/zhicheng-soft/commits/master |
一、准备工作
- 安装python:https://www.python.org/ftp/python/3.10.2/python-3.10.2-amd64.exe
- 安装pycharm:http://www.jetbrains.com/pycharm/download/#section=windows
- 安装fiddle
二、爬虫实现思路
- 对访问的网页使用fiddle进行抓包
- 爬取到的数据使用python进行解析
三、项目开始
一、朴朴数据
1.使用fiddle抓取数据
2.在浏览器中查看所复制的链接
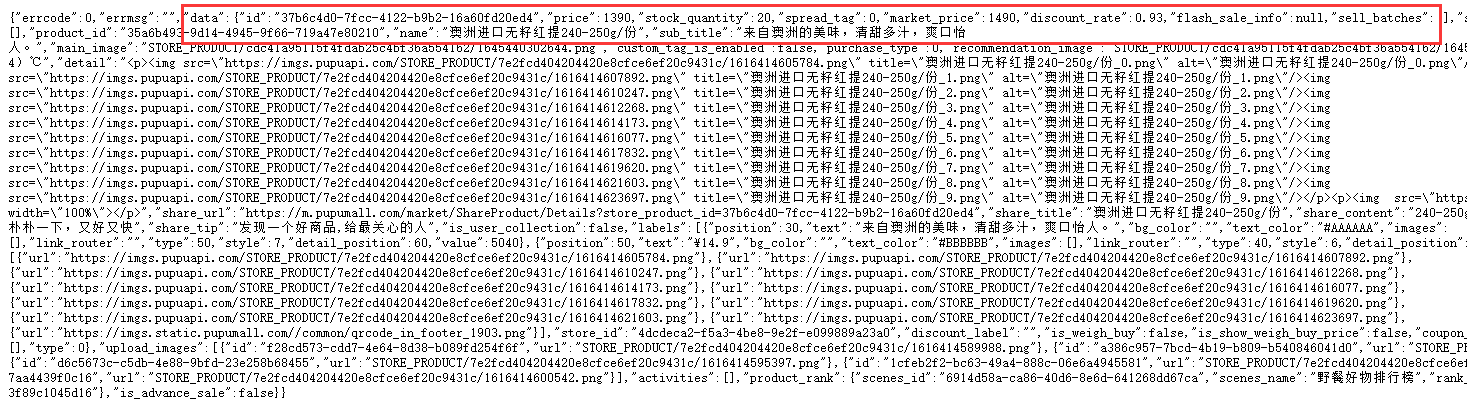
3、Python编程
使用python对我们挑选出的数据进行分析:
1)将j son的头文件(User-Agent)复制出来放在一个变量中,后面对其进行请求时有用
2)将请求的链接放在一个变量中,使用 requests.get() 对链接进行请求前需要导入requests包(第一次使用python没有导入对应的包,需要对其导包,我查阅了资料后才明白:pycharm导包)
3)根据刚才在网页中所需要挑选出来的数据(一组键值对),因为j son 内是使用字典进行数据存储,所以我使用键值对将所需数据取出存入变量中,之后以一定的格式打印输出
headers = {
# 浏览器类型
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 '
'Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat '
}
url = 'https://j1.pupuapi.com/client/product/storeproduct/detail/4dcdeca2-f5a3-4be8-9e2f-e099889a23a0/81435282-9e9e' \
'-4d08-afac-0da2adf73cf7 '
# 对URL地址发送请求
respOnse= requests.get(url, headers=headers).json()
data = response['data'] # 需要的数据
name = data['name'] # 名称
spec = data['spec'] # 规格
price = str(data['price'] / 100) # 价格
market_price = str(data['market_price'] / 100) # 原价
cOntent= data['share_content'] # 详细内容
print('---------------商品:' + name + '---------------')
print('规格:' + spec)
print('价格:' + price)
print('原价/折扣价:' + price + "/" + market_price)
print('详细内容:' + content + '\n')
print('---------------”' + name + '“价格波动---------------')
for priceFluctuation in range(1, 5): # 多次请求查看价格波动
respOnse= requests.get(url, headers=headers).json()
price = str(data['price'] / 100)
print('当前时间为' + datetime.datetime.now().strftime('%Y-%m-%d %H:%M') + ',价格为' + price)


它的data数组中有5个数组,每个数组都有固定的id值,每个收藏夹链接中间用id值来区分,这样就可以使用for循环对每个收藏夹进行抓包分析。抓了两个收藏夹的j son之后发现每个收藏夹的j son都有共同点:
https://www.zhihu.com/api/v4/collections/790324691/items?offset=0&limit=20
https://www.zhihu.com/api/v4/collections/790324691/items?offset=0&limit=20
发现了吗?区别在于中间,中间这个使用的不就是每个收藏夹的data数组中的id值吗?这就可以将id值作为变量进行解析。
解析出的j son 文件如下

这次的j son 比以往的相对繁杂,我在翻阅同学们提交的作业中,发现方晓佳同学使用的一个工具令我眼前一亮! 于是我上网随机选用一个软件进行解析。
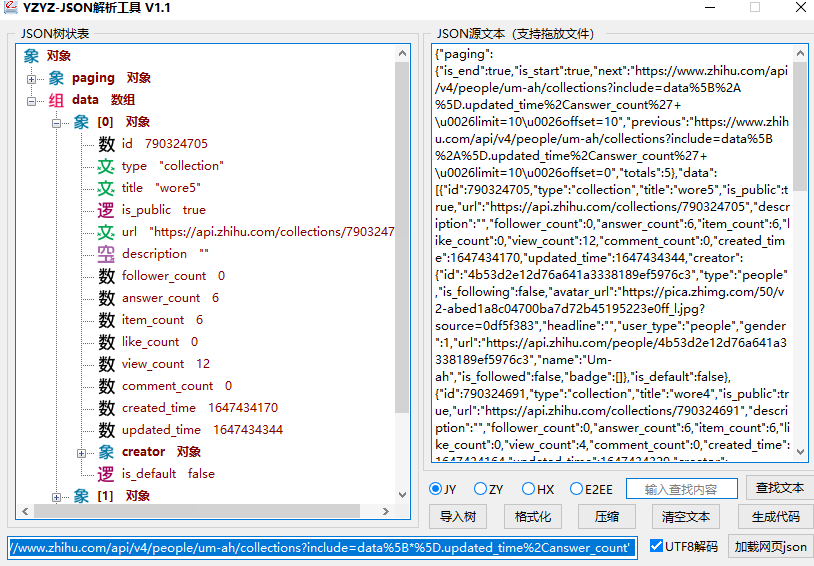
这个工具能够对j son 文件进行树状解析,这大大减轻了我的工作负担,解放了我的双眼!
编程
- 对爬来的收藏夹 j son 发送请求,然后将获得的数据进行循环得到每个收藏夹 id 和 title 保存在变量中
- 对每个收藏夹抓到的 j son 再次发送请求,将得到的内容的标题和链接保存在变量中
- 最后进行输出打印
代码如下:
#请求头
headers = {
# 浏览器类型
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/99.0.4844.51 Safari/537.36 '
}
#链接
url = 'https://www.zhihu.com/api/v4/people/um-ah/collections?include=data%5B*%5D.updated_time%2Canswer_count' \
'%2Cfollower_count%2Ccreator%2Cdescription%2Cis_following%2Ccomment_count%2Ccreated_time%3Bdata%5B*%5D.creator' \
'.vip_info&offset=0&limit=20 '
#返回请求的json
respOnse= requests.get(url=url, headers=headers).json()
#得到收藏夹数据
fav_data = response['data']
#循环数据内容
for i in range(0, len(fav_data)):
#收藏夹id
fav_id = str(fav_data[i]['id'])
#收藏夹标题
fav_title = str(fav_data[i]['title'])
print('--------------------------' + fav_id + ':' + fav_title + '--------------------------')
#请求每个收藏夹
url = 'https://www.zhihu.com/api/v4/collections/' + fav_id + '/items?offset=0&limit=20'
respOnse= requests.get(url=url, headers=headers).json()
#获取收藏夹内的数据
ques_data = response['data']
#循环打印收藏夹的内容
for j in range(0, len(ques_data)):
ques_title = ques_data[j]['content']['question']['title']
ques_url = ques_data[j]['content']['question']['url']
print(ques_title + ":" + ques_url)
三、git commit提交到gitee库中

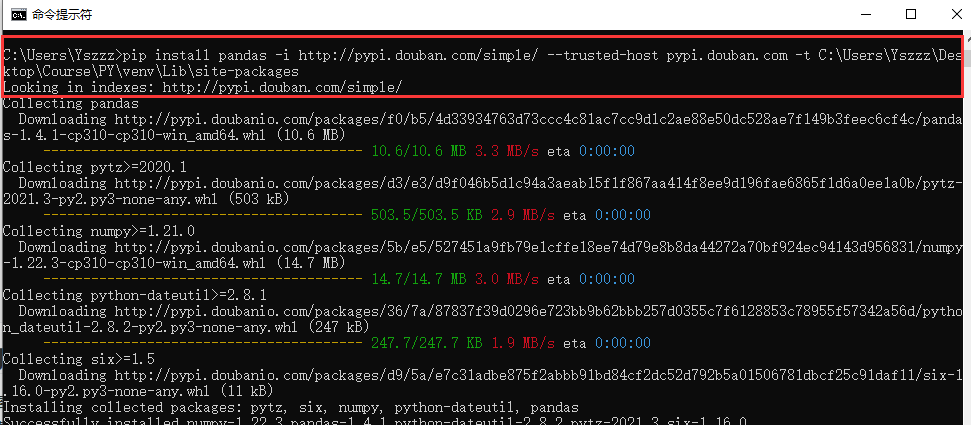
四、遇到的难题
五、总结
第一次使用python语言不懂的基础语法,于是我上网搜索了dalao的博客教学学习了基础语法之后对,因为我先前有学习java所以python这门语言很快有了初步理解。但是对于爬虫这一块还是比较陌生,跟着林伟强同学在学习群里发的b站教程学习,了解到了request请求和fiddle抓包结合使用可以有很奇妙的效果!通过这次学习我对于一门新的语言获得到的收获感到十分的兴奋,感受到了python的魅力,我今后会更加深入的学习、理解python!
另外傅老师说的很对,我对于这门课程的时间花费了不止一周2小时了,我估计最起码一周有4天了......0.o






 京公网安备 11010802041100号
京公网安备 11010802041100号