这里是Z哥的个人公众号
每周五11:45 按时送达
当然了,也会时不时加个餐~
我的第「178」篇原创敬上
大家好,我是Z哥。
物理学中有一个概念,叫「熵」。最近两年在网上提到这个词的文章越来越多了,Z哥我第一次看到这个词是在吴军老师的《数学之美》一书中。
这个概念在IT领域里可能知道的人不多,但是香农在信息论里借鉴它后所提出的「信息熵」,知道的人就多了。
薛定谔曾说过:
“人活着就是在对抗熵增定律,生命以负熵为生。”
《生命是什么》
所以,如果你还对这个概念不了解,而且并未意识到生活中到处可见的熵增问题,那么我觉得你有必要来看看我这篇文章。
我们不讲晦涩的科学公式,以一些生活中常见的简单案例来告诉你这是一种什么现象,相信会让你有一种恍然大悟的感觉。
对「熵」的简单理解,你可以记住一句话:越高越无序,越低越有序。
就拿我现在写的这篇文章来说,在文字层面,「熵」从高到低分别是,一个字 > 一个词 > 一句话 > 一段话 > 一篇文章。
比如,「我」「妈」「给」「你」「100」「元」这几个字,有很多种组合情况。
我妈给你100元
我给你妈100元
你给我妈100元
你妈给我100元
……
如果我单独向你传达这几个字,其实对你来说是混乱的。但是我在文章里如果直接写“我妈给你100元”,那么表达的意思就很明确了,此时的熵是低的。而我将这几个单独的字组成语句的过程就叫做「熵减」。
怎么样,到这里对「熵」有了一个初步的理解了吧。
我们再来举一个「熵增」的例子。
不知道你有没有定期整理衣柜的习惯。你有没有发现,当你不去花时间整理衣柜的话,慢慢地,你的衣柜会越来越乱,找衣服的难度越来越大。然后你痛定思痛,打算抽个周末好好整理一番,但是过了半年或者几个月,找不到衣服的情况又开始发生。
这里面,衣柜慢慢变乱的过程就是「熵增」,你下定决定去整理的过程就是「熵减」,在不断的反复。
脑子灵活的小伙伴可能会想,我每天都整理是不是就没有产生「熵增」了?从宏观上你可以这么来看,但是从微观上并非如此,你勤快的每天整理,其实只是缩小了「熵增」的空间而已,在它还没有让你觉得乱的时候就被重新减下去了。
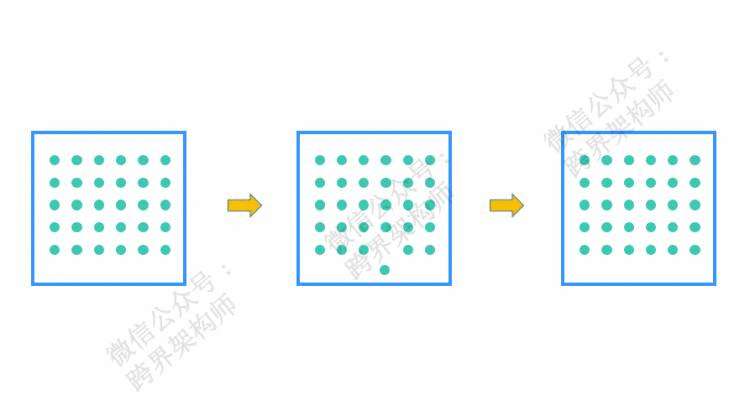
我今天之所以在这里分享这个概念给你,是因为我觉得这在我们这个信息爆炸的时代特别有价值。我们每天从外界摄入大量的碎片化信息,如果不加以整理,做「熵减」,会使得我们的大脑像前面提到的衣柜一样,学得越多,越乱,越找不到能为自己所用的东西。
回想一下,自己过去半年知识库有哪些扩充?学到了哪些东西?能说出来嘛?
其实我们与那些专家、大牛之间的差别,有很大部分原因就在这里,大牛们一直在做「熵减」的事情,通过思考、整理把零散的知识转换成体系化的知识结构,以在未来复用到类似的问题和事物上,而我们大多数人则是想到哪算哪,脑海里留下的仅仅是一段段碎片化的记忆。
那么如何为自己的大脑做「熵减」呢?分享几个我自己在用的方法。
/01 思考的时候,框架先行/
当你了解到一个知识点,如果你想为己所用,那么首先你得把它先纳入到一个「知识框架」里面。这也是你做「熵减」的基础。
什么叫「知识框架」?简单来说就是对知识进行分类,将每一个知识点归纳到对应的分类上去。当然,只是分类的话,无法体现多个知识点在多个维度上的关系,但是大多数情况下够用了。
很多人会纠结自己的分类对不对,其实完全没关系。「框架」也是需要迭代的,当你遇到一个新的知识点,无法归纳到任何一个分类中的时候,说明你的框架需要更新了,这也意味着你的认知能力在升级。
借助一些工具,你可以很容易地对知识点进行分类。并且,最终形成的图就是你的知识框架。
大部分情况下,思维导图就够用了,但如果你面对的是一个非常复杂的概念,那么可以尝试用结构图、象限图等等。甚至是一张白纸,这样你就可以用最贴近大脑所思考的形式将它们呈现出来。
/02 拥抱变化,保持开放/
「熵减」是通过外力做功才有机会形成的,所以你不能固化你的已有知识,认为这是真理。相反,只有更加地开放接纳新知识才能有机会产生更多的外力来加工你的知识体系,形成熵减,让你的知识框架更加的稳固、健康。
因为「熵」还有一个可怕之处,它越高,虽然越混乱无序,但是它的状态却是稳定的、平衡的。这会让我们形成一种错觉,并不觉得当前的状态有什么问题。
很多组织机构随着规模的壮大,流程的规范,反而变得越来越官僚化、臃肿、效率低下,也是一样的道理。因为内部结构一直没有发生变化,但是外部世界在不断的变化,以陈旧的组织结构面对新的世界自然会显得低效、臃肿,充斥着各种推诿、勾心斗角。
因此很多大公司都是“熵”这个概念的践行者,定期的末尾淘汰,组织架构调整等等动作,就是不断地在给组织注入“外力做功”,将“熵员工”淘汰出去。
如果可以的话,除了保持开放的姿态外,你还可以逼自己主动寻求变化,比如每个季度、每年接触一个陌生的领域。总之,不要让自己“稳定”下来。
/03 持续对外输出/
之前发的文章里也提到过很多「对外输出」的好处。用来做「熵减」也是有效的。因为当你整理需要输出的内容的同时,就是你在做功,梳理你大脑中信息的过程。
比如写作就是把大脑中零散的、无序的思维碎片,整合成一篇高度有序的文章,从而把你的想法提炼、浓缩,形成一个有序的整体。
这个过程是很痛苦的,因为它会消耗你的脑力(熵减需要消耗能量)。但是,也正是因为这个过程,我们才得以把摄入的信息碎片和思维碎片,整合成一个整体,构建起框架和模型。
好了,就这么多。其实这篇文章与其说是在分享一些能「熵减」的技巧给你,不如说是在给你阐述「熵减」的重要性。
惯例总结一下。
这篇呢,Z哥先简单向你解释了什么是「熵」,并建议你在当前这个信息爆炸的时代对你的大脑做「熵减」。
具体的做法可以参考以下3个思路:
思考的时候,框架先行
拥抱变化,保持开放
持续对外输出
希望对你有所启发。
很多人都说,自我学习、自我提升是一件痛苦的事情。没错,因为你在逆势而为,你啥都不干的话,「熵增」一直在那里。你选择自我提升,就是顶着“膨胀”的压力将它压下去。共勉。
推荐阅读:
原创不易,如果你觉得这篇文章还不错,就「在看」或者「分享」一下吧。鼓励我的创作 :)

如果你有关于软件架构、分布式系统、产品、运营的困惑
可以试试点击「阅读原文」








 京公网安备 11010802041100号
京公网安备 11010802041100号