点击我爱计算机视觉标星,更快获取CVML新技术
Tengine 是OPEN AI LAB 针对前端智能设备开发的软件开发包,核心部分是一个轻量级,模块化,高性能的AI 推断引擎,并支持用DLA、GPU、xPU作为硬件加速计算资源异构加速。

本文为Open AI Lab 工作人员投稿,对深度学习的核心操作GEMM进行了详细的使用介绍,欢迎对模型部署AI推断感兴趣的朋友关注Tengine。
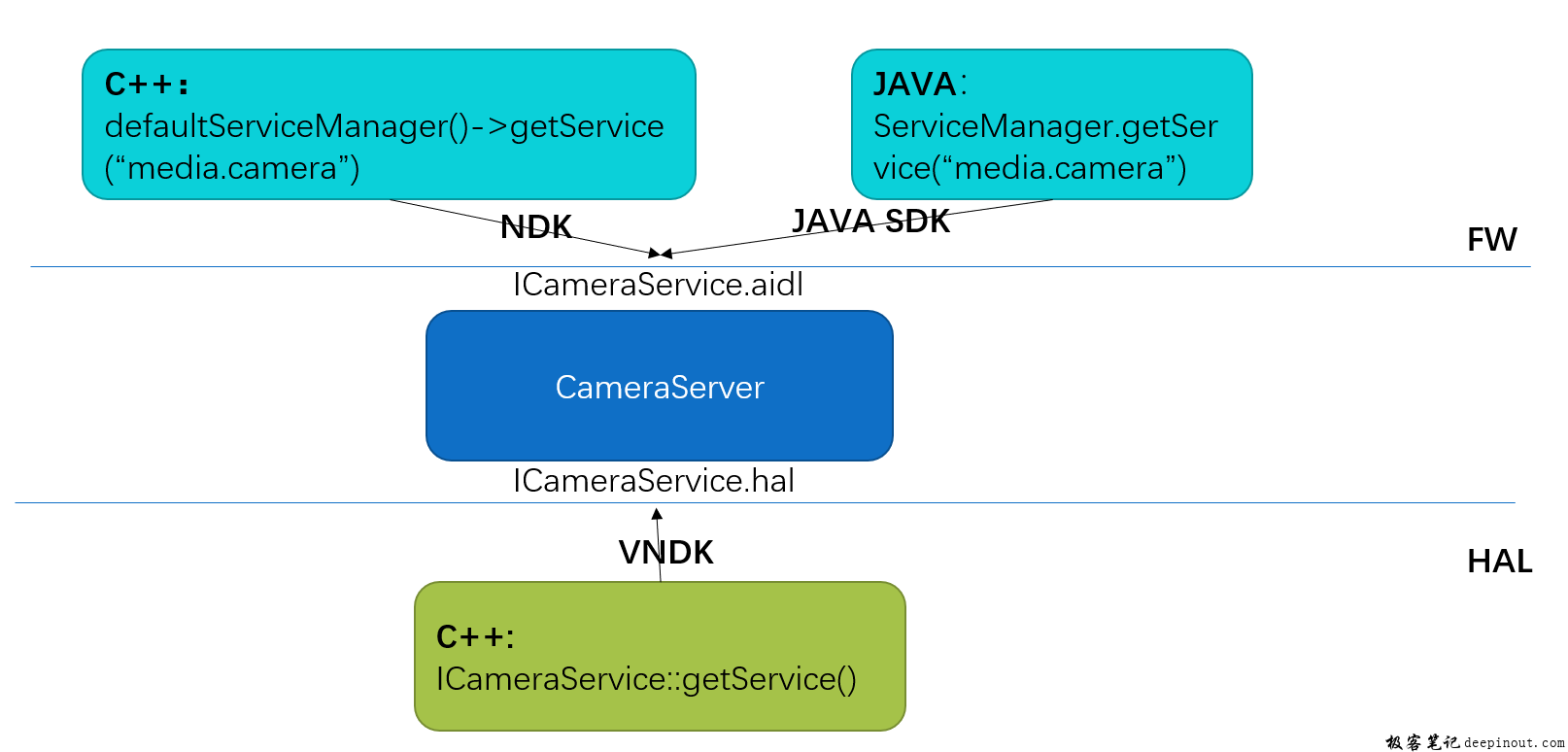
https://github.com/OAID/Tengine

很多刚入门Tengine的开发者想研读Tengine汇编代码,却苦于没有好的汇编入门教程,没有大神带入门,自己看又看不懂,怎么办?福利来了,Tengine带来了一份超详细的gemm汇编教程。

GEMM简介
什么是GEMM? 它的英文全称是 GEneral Matrix to Matrix Multiplication (通用矩阵的矩阵乘法),Gemm在神经网络的计算中占据很重要的位置。Why gemm is at the heart of deep learning[1]介绍了为什么GEMM在深度学习计算中如此重要,以及卷积计算中是如何使用GEMM。
教程大纲
教程分为三部分:
Step1: 纯C实现的gemm
Step2: 调用OpenBLAS的gemm
Step3: Tengine中的gemm
运行这个教程的代码,你需要:
可以执行armv8汇编的环境,比如RK3399
linux操作系统: 本教程的编译脚本使用的是Makefile
超简洁的教程源码

Step1: 纯C实现的gemm
step1部分的代码直接执行:
cd step1
make
./test
这个程序中我们计算的矩阵乘法是 A(m,k) * B(k,n) =C(m,n):
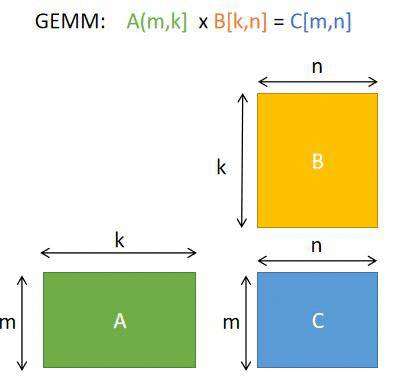
矩阵乘法的纯C简洁实现:
void gemm_pure_c(float* A, float* B, float* C,int m,int n,int k)
{for(int i=0;i}
Step2: 调用OpenBLAS的gemm
OpenBLAS[2]是一个开源的基础线性代数计算库,BLAS的英文全称Basic Linear Algebra Subprograms,它在不同的处理器上都做了优化。在Linux上,可以直接通过apt-get安装这个库:
sudo apt-get install libopenblas-dev
运行一下step2的代码
make
export OMP_NUM_THREADS=1
taskset 0x1 ./test
在RK3399上得到的结果是
[m n k]: 256 128 256
[openblas]: 4.68 ms
[pure c]: 32.22 ms
[blas VS pure_C]: maxerr=0.000076
可以看出,调用OpenBLAS库的性能明显优于纯C实现。
Step3:调用Tengine 16x4 kernel的gemm
这部分教程以 Tengine[3]源码中的 sgemm_4x16_interleave.S[4]为例子,对汇编代码做了一些简化,只支持k为4的倍数的情况。
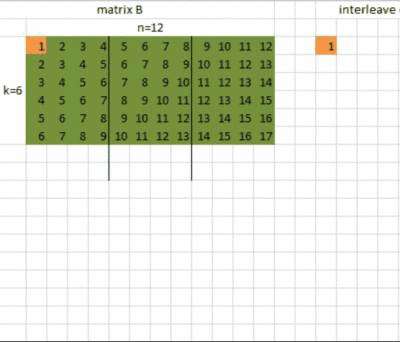
在使用Tengine的4x16 kernel之前, 首先要对矩阵A和矩阵B的数据进行interleave。什么是interleave呢?Interleave叫交错排布,表示对数据进行重新排布,为了计算的时候读取数据时能更好地利用缓存。这里我们对矩阵A的数据是对m中的每16个元素进行重排, 对矩阵B的数据是对n的每4个元素进行重排。
Tengine的4x16 kernel计算的n=4,m=16的情况,目前支持的k是4的倍数:
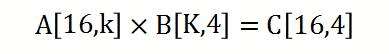
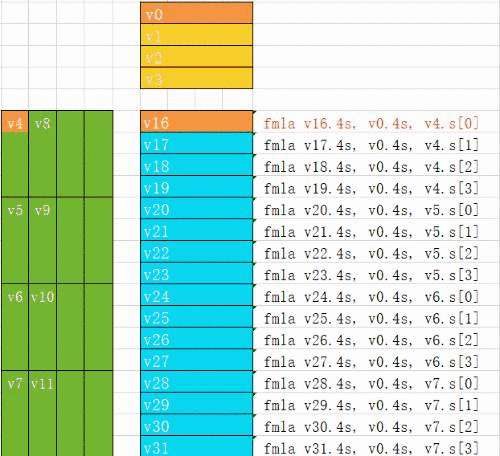
我们在汇编代码的loop4中计算k的每四个元素.
加载B的数据到寄存器 v0,v1,v2,v3
加载A的数据到寄存器 v4,v5,v6,v7,v8,v9,v10,v11
ldr q0,[x1] ldr q1, [x1,0x10] ldp q2, q3, [x1,0x20]ldp q4, q5, [x2]ldp q6, q7, [x2,0x20] ldp q8, q9, [x2,0x40]ldp q10,q11,[x2,0x60]
下面的动图演示了4x16的kernel的每条指令是如何进行计算的
最后的汇编对应的是把输出数据保存
stp q16, q17 ,[x0]stp q18, q19 ,[x0, #0x20]stp q20, q21 ,[x0, #0x40]stp q22, q23 ,[x0, #0x60]stp q24, q25 ,[x0, #0x80]stp q26, q27 ,[x0, #0xa0]stp q28, q29 ,[x0, #0xc0]stp q30, q31 ,[x0, #0xe0]
我们在RK3399上执行step3的代码:
cd step3
make
export OMP_NUM_THREADS=1
taskset 0x1 ./test
可以看出, Tengine的4x16 kernel性能在这三种实现中是最优的。
[m n k]: 256 256 256
[tengine 4x16]: 7.71 ms
[openblas]: 9.55 ms
[pure c]: 316.00 ms
[blas VS tengine]: maxerr=0.000061
What's more?
这个教程的代码只是一个示例,part3的代码只支持:
m 是16的倍数
n 是4的倍数
k 是4的倍数
看完这个教程,建议可以尝试以下的一些拓展工作:
你可以修改代码来支持任意数值的k,可参考[sgemm_4x16_interleave.S][4]这个汇编代码,添加 loop1.
你可以把 interleave_B4 函数替换成汇编,以优化性能。
你可以拓展代码,支持任意数值的 m and n
你可以尝试写一个 4x4_kernel.S 的armv8汇编
你可以尝试写一个 4x4_kernel.S 的armv7汇编
教程源码链接或点击阅读原文获取:
https://github.com/lyuchuny3/Tengine_gemm_tutorial
Reference:
[1] Why gemm is at the heart of deep learning (https://petewarden.com/2015/04/20/why-gemm-is-at-the-heart-of-deep-learning/)
[2]OpenBLAS (https://www.openblas.net/)
[3]Tengine (https://github.com/OAID/Tengine )
[4]sgemm_4x16_interleave.S(https://github.com/OAID/Tengine/blob/master/executor/operator/arm64/conv/sgemm_4x16_interleave.S )
模型压缩与应用部署交流群
关注最新最前沿的神经网络模型压缩、减枝、AI推断技术,扫码添加CV君拉你入群,(如已为CV君其他账号好友请直接私信)
(请务必注明:部署)

喜欢在QQ交流的童鞋,可以加52CV官方QQ群:805388940。
(不会时时在线,如果没能及时通过验证还请见谅)

长按关注我爱计算机视觉








 京公网安备 11010802041100号
京公网安备 11010802041100号