《CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention》
github代码链接
Transformers在处理视觉任务方面取得了很大进展,但不具备一种对视觉输入很重要的能力:在不同尺度的特征之间建立注意力。造成这一问题的原因有两方面:
(1)各层的输入嵌入是等尺度的,没有跨尺度特征
(2)一些vision transformers牺牲了嵌入的小尺度特征,以降低自我注意模块的成本
为了弥补这一缺陷,本文提出了跨尺度嵌入层(CEL)和长短距离注意(LSDA)。
CEL将每个嵌入与不同尺度的多个patch混合在一起,为模型提供了跨尺度嵌入。
LSDA将自我注意模块分成短距离和长距离两个模块,既降低了成本,又保留了小尺度和大尺度的嵌入特征。通过这两个设计实现跨尺度的关注。
此外,本文还提出了vision transformer的动态位置偏差,使流行的相对位置偏差适用于可变尺寸的图像。
在这些模块的基础上构建了视觉架构CrossFormer。实验表明,CrossFormer在几个典型的视觉任务,特别是目标检测和分割方面优于其他转换器。
Transformer在NLP上取得了巨大成功,得益于它的自我注意模块,Transformer天生就具有建立远程依赖的能力,这对许多视觉任务也很重要。因此,已经进行了大量的研究来探索基于transformer的视觉体系结构。
transformers需要一系列嵌入作为输入。为了使其适应视觉任务,大多数现有的vision transformers通过将图像分割成相等大小的块来产生嵌入。例如,一幅224×224的图像可以被分割成大小为4×4的56×56块,然后这些块通过线性层投影成为嵌入序列。在transformer内部,自我关注模块可以在任何两个嵌入之间建立依赖关系。这样的成本对于视觉输入来说太大了,因为它的嵌入序列比NLP的嵌入序列要长得多。因此,最近提出的视觉转换器开发了多种替代品,以更低的成本近似香草模型(vanilla)的自我注意模块。
虽然上述工作取得了一定的进展,但现有的vision transformers仍然存在一个制约其性能的问题–未能在不同尺度的特征之间建立关注度,而这种能力对于视觉任务来说是非常重要的。例如,一幅图像通常包含许多不同尺度的对象,建立它们之间的关系需要跨尺度的注意机制。此外,一些任务,如实例分割,需要大规模(粗粒度)特征和小规模(细粒度)特征之间的交互。现有的vision transformers无法处理这些情况的原因有两个:(1)嵌入序列是由大小相等的块生成的,因此同一层中的嵌入只具有单一尺度的特征。(2)在自我注意模块内部,相邻嵌入的键/值经常被合并,以降低成本。因此,即使嵌入同时具有小尺度和大尺度特征,合并操作也会丢失每个单个嵌入的小尺度(细粒度)特征,从而使跨尺度注意力失效。
为了解决这个问题,我们共同设计了嵌入层和自我注意模块如下:(1)跨尺度嵌入层(CEL)-采用了金字塔结构,这自然会将模型分成多个阶段。CEL出现在每个阶段的开始处。它接收上一阶段的输出(或图像)作为输入,采样具有不同尺度(如4×4、8×8等)的多个核的patch。然后,每个嵌入都是通过投影和连接这些patch来构建的,而不是只使用一个单一比例的。(2)长短距离注意(LSDA)-提出了一种替代原始的香草模型自我注意的方法,但为了保留小尺度特征,嵌入(以及它们的键/值)不会合并。相反,我们将自我注意模块分为短距离注意(SDA)和长距离注意(LDA)。SDA建立相邻嵌入之间的依赖关系,而LDA负责远离彼此的嵌入之间的依赖关系。LSDA还降低了自我注意模块的成本,但与其他模块不同的是,LSDA既不损害小规模的特征,也不损害大规模的特征,因此可以关注跨尺度的交互。
此外,相对位置偏差(RPB)是vision transformer的一种有效位置表征。然而,它仅适用于输入图像/组大小固定的情况,这不适用于像物体检测这样的多任务。为了使算法更加灵活,我们引入了动态位置偏置(DPB)训练模块,它接受两个嵌入的距离作为输入,并输出它们的位置偏差。该模块在训练阶段进行了端到端的优化,代价可以忽略不计,但使RPB适用于不同的图像/组大小。
我们建议的每个模块都可以用大约十行代码来实现。在此基础上,我们构造了四种大小不一的多功能视觉转换器CrossFormer。在四个典型的视觉任务(即图像分类、对象检测和实例/语义分割)上的实验表明,CrossFormers在所有这些任务上都优于以往的视觉转换器,特别是密集预测任务(对象检测和实例/语义分割)。我们认为这是因为图像分类只关注一个对象和大尺度特征,而密集预测任务更多地依赖于跨尺度关注。
受自然语言处理的transformers的启发,研究人员为视觉任务设计了vision transformer,以利用其巨大的注意机制。特别是ViT和DeiT,将原始transformer转移到视觉任务,实现了令人印象深刻的准确性。后来,PVT、HVT、Swin等将金字塔结构引入变压器,大大减少了模型后续层的patch数量。transformer还被扩展到其他任务,如对象检测和分割。
作为transformers的核心,自我注意模块的计算和存储开销为O(N2)O(N^2)O(N2),其中N为嵌入序列的长度。虽然这样的成本对于小型图像分类是可以接受的,但对于具有大图像的模型就不太好了。为了解决这个问题,Swin限制了对局部区域的注意,放弃了远程依赖。PVT和Twin使相邻嵌入共享相同的键/值,以降低成本。同样,其他vision transformer也采用分而治之的方法,以较低的成本近似普通的自我注意模块。
transformer是组合不变的,也就是说,打乱输入嵌入不会改变transformer的输出。然而,嵌入的位置也包含重要信息。为了使该模型意识到这一点,提出了许多不同的嵌入位置表示,其中相对位置偏差(RPB)就是其中之一。对于RPB,每对嵌入都会在它们的注意力上添加一个偏差,这表示它们之间的相对距离。在以前的工作中,RPB被证明比其他位置表征对视觉任务更有效。
(博主推荐:为什么要用LN不用BN)
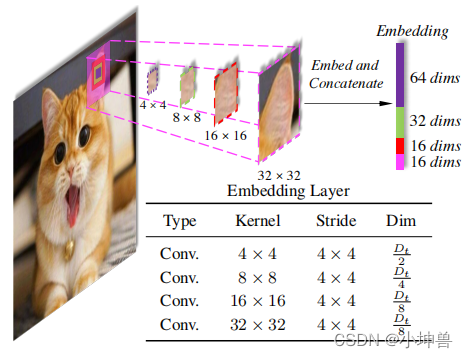
跨尺度嵌入层用于生成每个阶段的输入嵌入。如图2所示,以第一个CEL为例,它位于Stage-1之前。它接收一幅图像作为输入,使用四个不同大小的内核对patch进行采样。四个内核的步长保持相同,以便它们生成相同数量的嵌入。正如我们在图2中看到的,每四个相应的patch具有相同的中心但不同的比例。这四个patch将被投影并连接为一个嵌入。在实际应用中,采样和投影过程可以通过四层卷积来实现。
对于跨尺度嵌入,一个问题是如何设置每个尺度的投影尺寸。考虑到较大的核更容易导致较大的计算量,我们对较大的核使用较低的维数,而对较小的核使用较高的维数。图2在其子表中提供了具体的分配规则,并给出了一个128维的示例。与平均分配维数相比,我们的方案节省了大量的计算开销,但不会明显影响模型的性能。其他阶段中的跨比例嵌入层的工作方式与此类似。如图1所示,阶段2/3/4中的CEL使用两个内核(2×2和4×4)。步长设置为2×2,以将嵌入次数减少到四分之一(相较于步长为1x1来说)。
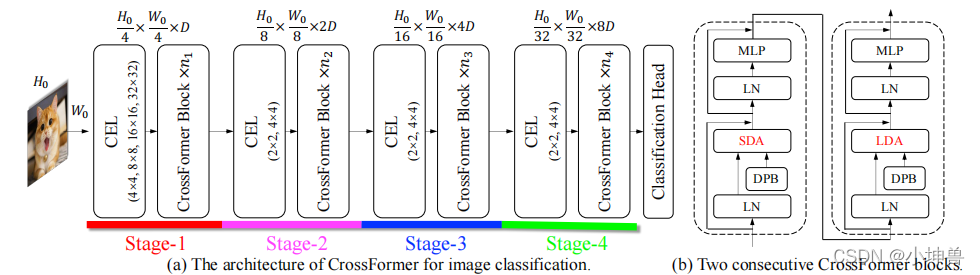
每个CrossFormer模块由短距离注意(SDA)或长距离注意(LDA)模块和多层感知器(MLP)组成。特别是,如图1(b)所示,SDA和LDA交替出现在不同的块中,动态位置偏置(DPB)在SDA和LDA中都适用于嵌入的位置表示。此外,在块中使用残差连接。
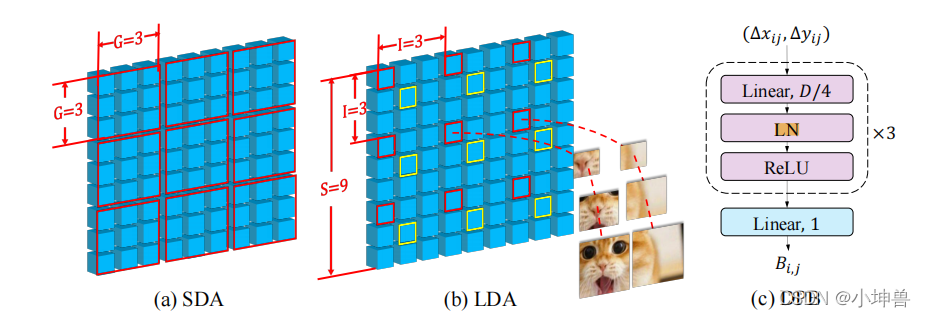
我们将自我注意模块分为两部分:短距离注意(SDA)和长距离注意(LDA)。对于SDA,每个G×G相邻嵌入被分组在一起。图3(a)给出了当G=3时的例子。对于输入大小为S×S的LDA,以固定间隔I对嵌入进行采样。例如,在图3(b)(I=3)中,所有具有红边的嵌入属于一组,而具有黄色边框的嵌入属于另一组。LDA的组高度/宽度计算为G=S/I,在本例中为G=3。在对嵌入进行分组后,SDA和LDA都在每个组中使用了普通的自我注意模块。结果,自我注意模块的存储和计算成本从O(S4)O(S^4)O(S4)降低到O(S2G2)O(S^2 G^2)O(S2G2)。
在图3(b)中,我们绘制了两个嵌入的组件patch。由此可见,两个嵌入体的小比例patch是不相邻的,没有大比例patch的帮助很难判断它们之间的关系。因此,如果这两个嵌入仅由小规模的patch构建,将很难在它们之间建立依赖关系。相反,相邻的大型patch提供了足够的上下文来链接这两个嵌入。因此,在大规模patch的引导下,远程跨尺度的关注变得更容易、更有意义。
相对位置偏差(Relative Position Bias,RPB)通过增加嵌入对象注意力的偏差来表示嵌入对象的相对位置。正式地说,LSDA与RPB的注意力图变成了:
Attention=Softmax(QKT/d+B)VAttention = Softmax(QK^T/\sqrt d+B)VAttention=Softmax(QKT/d+B)V
其中Q、K、V∈RG2×DQ、K、V\in R^{G^2×D}Q、K、V∈RG2×D分别表示自我注意模块中的query、key、value,d\sqrt dd是常量归一化子。B∈RG2×G2B∈R^{G^2×G^2}B∈RG2×G2是RPB矩阵。在前人的工作中,Bi,j=B^∆xij,∆yijB_{i,j}=\hat B_{∆x_{ij},∆y_{ij}}Bi,j=B^∆xij,∆yij,其中B^\hat BB^是一个固定大小的矩阵,(∆xij,∆yij)(∆x_{ij},∆y_{ij})(∆xij,∆yij)是第i个和第j个嵌入之间的坐标距离。很明显,在(∆xij,∆yij)(∆x_{ij},∆y_{ij})(∆xij,∆yij)超过B^\hat BB^的大小的情况下,图像/组的大小受到限制(也就是说,图像/组的大小不能超过B^\hat BB^的大小)。相反,我们提出了一种称为DPB的基于mlp的模块来动态地产生相对位置偏差,即
Bi,j=DPB(∆xij,∆yij)B_{i,j}=DPB(∆x_{ij},∆y_{ij})Bi,j=DPB(∆xij,∆yij)
DPB的结构如图3(c)所示。其非线性变换由三个带有层归一化和ReLU的完全连通的层组成。DPB的输入维度为2,即(∆xij,∆yij)(∆x_{ij},∆y_{ij})(∆xij,∆yij),中间层的维度设置为D/4,其中D是嵌入的维度。DPB是一个与整个模型一起优化的可培训模块。它可以处理任何图像/组大小,而无需担心(∆xij,∆yij)(∆x_{ij},∆y_{ij})(∆xij,∆yij)的界限。
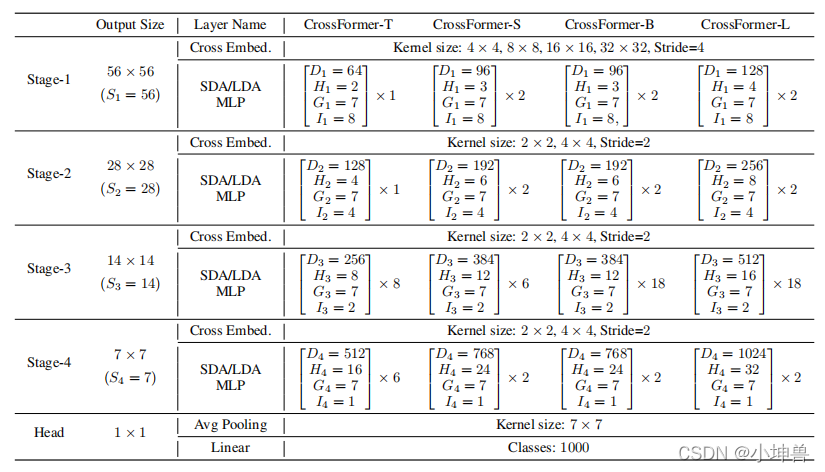
表1列出了CrossFormer用于图像分类的四个变体(-T、-S、-B和-L,分别代表极小、小、基础和大,对应本博客下面的部分中提到的yaml)的详细配置。为了重用预先训练的权重,用于其他任务的模型使用与分类相同的主干,除了它们可能使用不同的G和I。具体地说,除了与分类相同的配置外,我们还使用G1=G2=14、I1=16和I2=8测试检测/分割模型的前两个阶段,以适应更大的图像。具体架构载于附录(A.3)。值得注意的是,组大小(即G和I)不影响权重张量的形状,因此在ImageNet上预先训练的主干可以直接在其他任务上进行微调,即使它们使用不同的(G,I)。
实验在图像分类、目标检测、实例分割和语义分割四个具有挑战性的任务上进行。为了进行公平的比较,我们尽可能保持与其他视觉转换器相同的数据增强和训练设置。竞争对手都是竞争激烈的视觉transformer,包括DeiT、PVT、T2T-ViT、TNT、CViT、Twin、Swin、NesT、CVT、TransCNN、Shuffle、BoTNet和RegionViT。(博主惊叹:全部都是2021年的新模型)
分类实验是使用ImageNet数据集进行的。模型在1.28M训练图像上进行训练,并在50K验证图像上进行测试。使用与其他vision transformer相同的训练设置。特别是,我们使用AdamW优化器训练300个epoch,使用余弦衰减学习率调度器,并使用20个epoch的线性预热。batch size为1024个,拆分在8个V100 GPU上。使用0.001的初始学习率和0.05%的权重衰减率。此外,对于CrossFormer-T、CrossFormer-S、CrossFormer-B、CrossFormer-L,我们分别使用0.1、0.2、0.3、0.5的dropout。此外,类似于Swin、RandAugment、Mixup、CutMix、随机擦除和随机深度被用于数据增强。
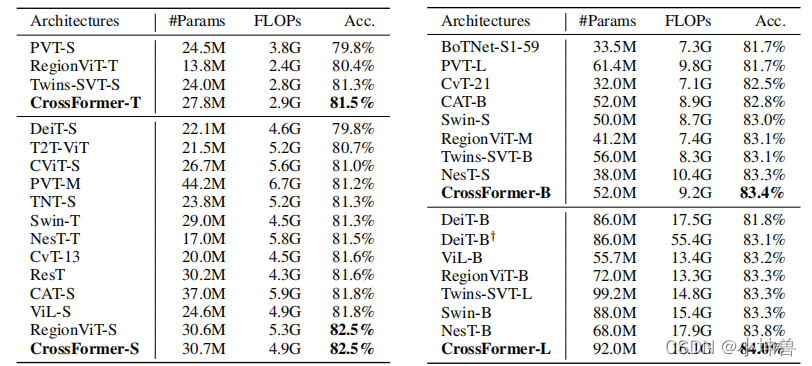
结果如表2所示。正如我们可以看到的那样,CrossFormer在相似的参数和FLOPs的情况下达到了最高的准确率。特别是,与流行的DeiT、PVT和Swin相比,我们在小模型上的准确率至少高出1.2%。此外,尽管RegionViT在小型模型上与我们达到了相同的准确率(82.5%),但在大型模型上比我们低0.7%(84.0%对83.3%)。
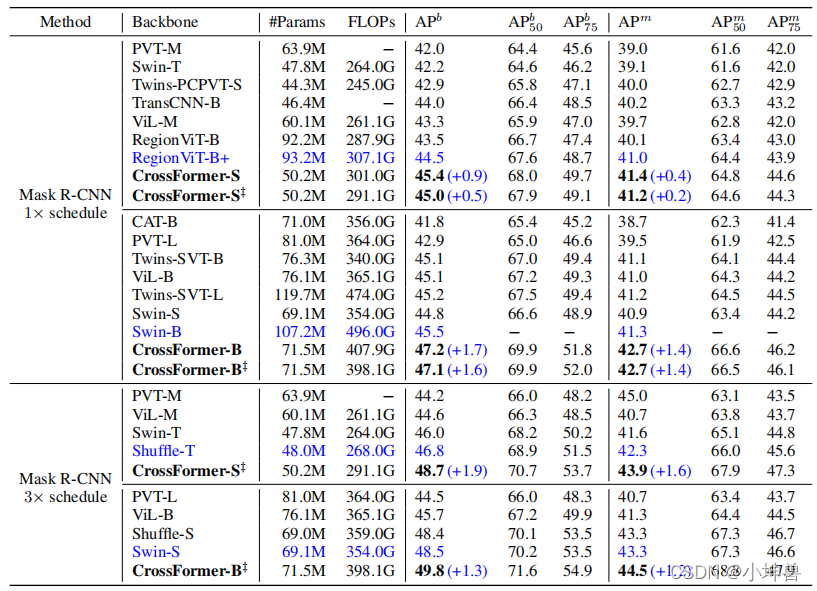
目标检测和实例分割的实验都是使用COCO 2017数据集进行的,该数据集包含118K训练图像和5K验证图像。我们使用基于MMDetect的RetinaNet和Mask-RCNN作为对象检测或实例分割的头部。对于这两个任务,主干都使用在ImageNet上预先训练的权重进行初始化。检测/分割模型在8个V100GPU上以batch size为16进行训练,并使用初始学习率为1×10−4的adamW优化器。在前人工作的基础上,我们采用了1×训练方案,即对模型进行12个epoch的训练,对图像的短边调整到800像素。
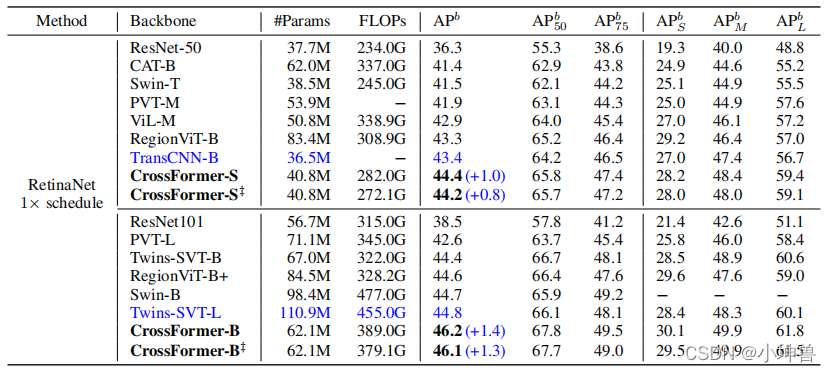
结果放在表3中。正如我们可以看到的那样,排在第二位的体系结构随着实验的进行而变化,也就是说,这些体系结构可能在一个任务中表现良好,但在另一个任务中表现不佳。相比之下,我们在任务(检测和分割)和两个模型大小(小的和基本的)上都优于所有其他人。此外,当扩展模型时,CrossFormer相对于其他体系结构的性能增益会增加,这表明CrossFormer具有更高的潜力。
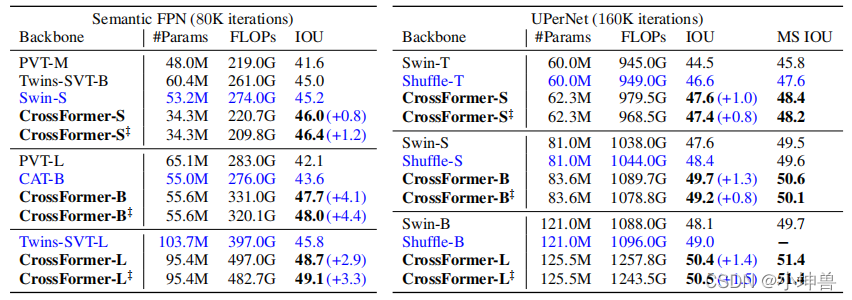
ADE20K被用作语义切分的基准。它涵盖了150个语义类别的广泛范围,包括用于训练的20K图像和用于验证的2K图像。与检测模型类似,我们用在ImageNet上预先训练的权重来初始化主干,并以基于MMS监管的语义FPN和UPerNet作为分割头。对于FPN,我们使用学习率和权重敏感度为1×10−4的AdamW优化器。模型被训练为80K迭代,batch size为16。对于UPernet,我们使用初始学习率为6×10−5,权重衰减为0.01的AdamW优化器,模型被训练为160K迭代。
结果如表4所示。与目标检测类似,CrossFormer在放大模型时表现出比其他算法更大的性能增益。例如,CrossFormer-T的IOU比TwinsSVT-B高1.4%,但CrossFormer-B的IOU比TwinsSVT-L高3.1%。此外,CrossFormer在密集预测任务(如检测和分割)上比在分类上表现出更显著的优势,这表明注意模块中的跨尺度交互对于密集预测任务比对分类更重要。
我们通过将所有跨尺度的嵌入层替换为单尺度的嵌入层来进行实验。单尺度嵌入意味着只有一个核(Stage1为4×4,其他Stage为2×2)用于模型中的四个CEL。表5a中的结果表明,跨尺度嵌入获得了很大的性能增益,即它比没有跨尺度嵌入的模型的准确率高0.9%。
比较了PVT和Swin中使用的两种自关注模块。具体地说,PVT在计算自我注意时牺牲了小范围的信息,而Swin将自我注意限制在局部区域,放弃了远程注意。如表5a所示,与PVT和Swin类自我注意机制相比,我们的准确率至少高出0.6%。结果表明,长短距离的自我注意最有利于提高模型的绩效。
我们比较了绝对位置嵌入(APE)、相对位置偏差(RPB)和DPB之间模型的参数、FLOP、吞吐量和精度,结果如表5b所示。DPB-residual表示具有残差连接的DPB。DPB和RPB均优于APE,准确率为0.4%。DPB实现了与RPB相同的精确度,但额外成本可以忽略不计,但是,正如我们在前面所描述的,它比RPB更灵活,并且适用于可变图像大小或组大小。此外,DPB中的剩余连接无助于提高模型的性能(82.5%比82.4%)。
我们提出了一种基于transformer的视觉架构,称为CrossFormer。其核心设计包括跨尺度嵌入层和长短距离注意(LSDA)模块。此外,我们提出了动态位置偏差(DPB),使相对位置偏差适用于任何输入大小。实验表明,CrossFormer在几个典型的视觉任务上取得了比其他vision transformer更好的性能。特别是CrossFormer算法在检测和分割方面有了较大幅度的提高,这表明跨尺度嵌入和LSDA对于密集预测视觉任务尤为重要。
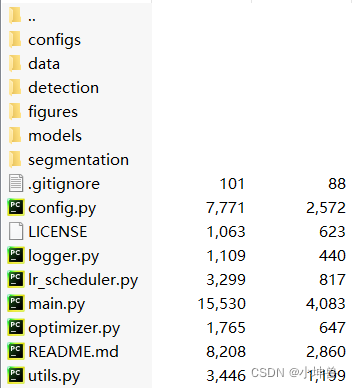
configs/: 内部包含四个yaml文件,在运行图像分类时可以使用,用来运行不同大小的网络
data/: 内部文件用于加载数据集
detection/: 目标检测相关代码
figures/: README文档用到的图片
models/: 图像分类的模型代码
segmentation/: 图像分割相关代码
其他py文件: 图像分类相关代码
数据集是imagenet,可在kaggle上下载
修改文件夹的结构和名称,该项目需要的数据集目录树为
images/train/n01443537/ # 每一个类别一个文件夹images/xxx.JPEGxxx.JPEGn01629819/images/xxx.JPEGxxx.JPEGval/n01443537/ # 每一个类别一个文件夹images/xxx.JPEGxxx.JPEGn01629819/images/xxx.JPEGxxx.JPEG
在CrossFormer文件夹(即最外层文件夹)下运行。
pip install numpy scipy Pillow pyyaml yacs torch==1.7.0 torchvision==0.8.1 timm==0.3.2
dist.get_rank()(进程编号/优先级)改成0,dist.get_world_size()(执行脚本的进程数)换成1。python main.py --cfg configs/tiny_patch4_group7_224.yaml --batch-size 128 --data-path path_to_imagenet --output ./output
可见成功的结果如下

在detection文件夹下运行
pip3 install mmcv-full==1.2.7 mmdet==2.8.0
问题一:安装报错 error: command ‘:/usr/local/cuda/bin/nvcc’ failed with exit status 1
解决方式:仔细观察发现nvcc的绝对路径前加了个“:”,说明是环境变量出了问题
修改~/.bashrc文件:将export CUDA_HOME=$CUDA_HOME:/usr/local/cuda修改为
export CUDA_HOME=/usr/local/cuda
随即就能安装啦!
问题二:安装mmdet时各种爆红
解决方式:无需解决,爆红的原因是缺少mmpycocotools等依赖,爆红之后会自动安装
import torch
ckpt = torch.load("crossformer-s.pth") ## load classification checkpoint
torch.save(ckpt["model"], "backbone-crossformer-s.pth") ## only model weights are needed
detection\configs\_base_\datasets\coco_detection.py和detection\configs\_base_\datasets\coco_instance.py第二行的data_root的值修改为自己的coco数据集所在目录~/.local/lib/python3.8/site-packages/mmdetmodel/crossformer_backbone.py和detection/crossformer_factory.py复制到~/.local/lib/python3.8/site-packages/mmdet/model/backbones目录下~/.local/lib/python3.8/site-packages/mmdet/model/backbones/crossformer_factory.py的前十一行from ..builder import BACKBONES
from .crossformer_backbone import CrossFormer# 删掉多余的行,保证“@BACKBONES.register_module()”之前只有这两行
~/.local/lib/python3.8/site-packages/mmdet/model/backbones/__init__.py# 新增一行
from .crossformer_factory import CrossFormer_S, CrossFormer_B
# 在__all__里加入'CrossFormer_S', 'CrossFormer_B'
__all__ = ['源码前面的东西......','CrossFormer_S', 'CrossFormer_B']
from mmcv.runner import get_dist_info, init_dist
注释或删掉
if args.launcher == 'none':distributed = Falseelse:distributed = Trueinit_dist(args.launcher, **cfg.dist_params)# re-set gpu_ids with distributed training mode_, world_size = get_dist_info()cfg.gpu_ids = range(world_size)
修改为
distributed = False
# 将python xxxxxx。。。那条命令改成
python3 train.py $CONFIG --cfg-options model.pretrained=$PRETRAIN --work-dir ./det-output --launcher pytorch ${@:4}
# 博主这里是选择直接在py文件的parser里添加了default参数,可以在运行train.py文件时没这么长的参数要写。
如果显存炸了的话,前往detection/configs/_base_/datasets将里面的两个文件中的samples_per_gpu和workers_per_gpu改成1。如果还不行,可以尝试将图像检测项目中的batch_size调小,重新训练模型再回来尝试,但不一定能成功。如果还不行,建议购买更好的显卡。如果还不行,建议放弃项目。
测试:直接运行指令
python3 test.py configs/mask_rcnn_crossformer_s_fpn_1x_coco.py det-output/epoch_12.pth --eval bbox
待更新





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有