本文主要介绍关于线性回归,sklearn,机器学习的知识点,对【线性回归模型笔记(2)】和【多元线性回归模型spss】有兴趣的朋友可以看下由【羊咩咩咩咩咩】投稿的技术文章,希望该技术和经验能帮到你解决
本文主要介绍关于线性回归,sklearn,机器学习的知识点,对【线性回归模型笔记(2)】和【多元线性回归模型spss】有兴趣的朋友可以看下由【羊咩咩咩咩咩】投稿的技术文章,希望该技术和经验能帮到你解决你所遇的机器学习,python相关技术问题。
多元线性回归模型spss
多项式回归,处理非线性数据的方法:将高次方的特征值当做一个新的特征,使用sklearn包中的PolynomialFeatures()
##多项式回归(非线性模型)
m=100
X = 6*np.random.randn(m,1)-3
Y =0.5*X**2+2+X+np.random.randn(m,1)
##将x^2看做一个特征添加到列表中
from sklearn.preprocessing import PolynomialFeatures
poly_features =PolynomialFeatures(degree=2,interaction_Only=False,include_bias=False)
X_poly = poly_features.fit_transform(X)
##使用线性回归进行拟合
from sklearn.linear_model import LinearRegression
lin_reg =LinearRegression()
lin_reg.fit(X_poly,Y)
lin_reg.intercept_,lin_reg.coef_
对PolynomialFeatures中的参数进行解释,degree:维度,interaction_only:只有交叉相乘,include_bias:包含1这个数
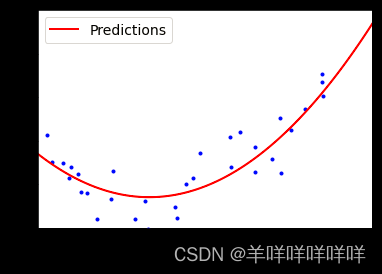
实例:
X_new=np.linspace(-3, 3, 100).reshape(100, 1)
X_new_poly = poly_features.transform(X_new)
y_new = lin_reg.predict(X_new_poly)
plt.plot(X, Y, "b.")
plt.plot(X_new, y_new, "r-", linePredictions")
plt.xlabel("$x_1$", fOntsize=18)
plt.ylabel("$y$", rotation=0, fOntsize=18)
plt.legend(loc="upper left", fOntsize=14)
plt.axis([-3, 3, 0, 10])
plt.show()
判断模型好坏的两种方式
(1)通过交叉验证来评估模型的泛化能力
(2)观察学习曲线
学习曲线是通过查看训练集与测试集的均方误差的图像来判断
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
##学习曲线的绘制
def plot_learning_curves(model,x,y):
x_train,x_val,y_train,y_val = train_test_split(x,y,test_size=0.2)
train_error,val_error=[],[]
for m in range(1,len(x_train)):
model.fit(x_train[:m],y_train[:m])
y_train_predict = model.predict(x_train[:m])
y_val_predict =model.predict(x_val[:m])
train_error.append(mean_squared_error(y_train[:m],y_train_predict))
val_error.append(mean_squared_error(y_val[:m],y_val_predict))
plt.plot(np.sqrt(train_error),"r-+",linetrain')
plt.plot(np.sqrt(val_error),"b-",lineval')
实例:
lin_reg = LinearRegression()
plot_learning_curves(lin_reg,X,Y)
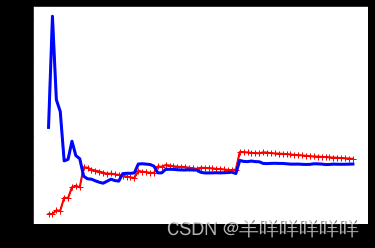
可以看出红色为训练误差,一开始样本很小时,误差较小,随着样本增大,误差逐渐增大,但是反观测试误差逐渐与训练误差相一致,所以结果是比较拟合的
正则化线性模型
目的:减少过拟合,降低了高次项的权重。
(1)岭回归
正则项由l2范数进行表示,且在进行岭回归之前需要对数据进行缩放
##利用标准方程求解
import numpy as np
np.random.seed(42)
m = 20
X = 3 * np.random.rand(m, 1)
Y = 1 + 0.5 * X + np.random.randn(m, 1) / 1.5
X_new = np.linspace(0, 3, 100).reshape(100, 1)
A = np.array([0,0,0,1]).reshape(2,2)##生成一个2X2的单位的矩阵,但是偏执项为0
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=1,include_bias=True)
X_poly = poly_features.fit_transform(X)
a=0.5##a为惩罚项
theta_new = np.linalg.inv(X_poly.T.dot(X_poly)+a*A).dot(X_poly.T).dot(Y)
theta_new
##使用sklearn的包
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha =0.5,solver="cholesky")
ridge_reg.fit(X,Y)
ridge_reg.intercept_,ridge_reg.coef_
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty='l2')
sgd_reg.fit(X,Y.ravel())
sgd_reg.intercept_,sgd_reg.coef_
(2)Lasso回归
这里采用的正则项为l1范数,特点为可以消除最不重要的特征的权重。
##使用sklearn实现lasso回归
from sklearn.linear_model import Lasso
lasso_reg =Lasso(alpha=0.1)
lasso_reg.fit(X,Y)
lasso_reg.intercept_,lasso_reg.coef_
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty='l1')
sgd_reg.fit(X,Y)
sgd_reg.intercept_,sgd_reg.coef_
(3)弹性网络
是岭回归与lasso回归的结合,其中包含两个正则项:l1范数与l2范数,通过调整比例来进行优化。
##用sklearn包实现弹性网络(ElasticNet)
from sklearn.linear_model import ElasticNet
elastic_net =ElasticNet(alpha=0.1,l1_ratio=0.5)##这里是混合了lasso与岭回归这两种方法
elastic_net.fit(X,Y)
elastic_net.intercept_,elastic_net.coef_
(4)对验证误差达到最小值时进行提前停止
from sklearn.model_selection import train_test_split
np.random.seed(42)
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 2 + X + 0.5 * X**2 + np.random.randn(m, 1)
X_train, X_val, y_train, y_val = train_test_split(X[:50], y[:50].ravel(), test_size=0.5, random_state=10)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.base import clone
from sklearn.metrics import mean_squared_error
poly_scaler = Pipeline([
("poly_features", PolynomialFeatures(degree=90, include_bias=False)),
("std_scaler", StandardScaler())
])
X_train_poly_scaler = poly_scaler.fit_transform(X_train)
X_val_poly_scaler =poly_scaler.fit_transform(X_val)
sgd_reg =SGDRegressor(max_iter=1,tol=-np.infty,warm_start=True,penalty=None,learning_rate="constant",eta0=0.00005)
minimun_val_error=float("inf")
best_epoch=None
best_model=None
for epoch in range(10000):
sgd_reg.fit(X_train_poly_scaler,y_train)
y_predict = sgd_reg.predict(X_val_poly_scaler)
val_error = mean_squared_error(y_predict,y_val)
if val_error
在大多是情况下使用岭回归,当实际用到的特征较少是可以考虑lasso回归与弹性网络。
逻辑回归
对于一个单元二分类器,可以使用sigmoid函数,使用sklearn.linear_model.LogisticRegression包
from sklearn import datasets
iris = datasets.load_iris()
list(iris.keys())
import matplotlib.pyplot as plt
X =iris['data'][:,3:]
Y=(iris['target']==2).astype(np.int)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X,Y)
X_new = np.linspace(0,3,1000).reshape(-1,1)
y_proba = log_reg.predict_proba(X_new)
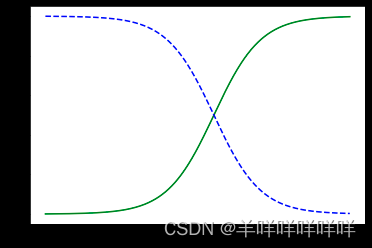
plt.plot(X_new,y_proba[:,1],'g-',label="iris virginica")
plt.plot(X_new,y_proba[:,0],'b--',label="not iris virginica")
多元分类器:Softmax回归
参数x为一个个实例,y为k个类别,通过计算x为某一个k类的分数,然后除以整个的分数可以得到概率值。使用sklearn.LogisticRegression但是参数multi_class 为multinomial。
##Softmax回归
X =iris['data'][:,(2,3)]
Y=iris['target']
softmax_reg =LogisticRegression(multi_class='multinomial',solver='lbfgs',C=10)
softmax_reg.fit(X,Y)
softmax_reg.predict_proba([[5,2]])
本文《线性回归模型笔记(2)》版权归羊咩咩咩咩咩所有,引用线性回归模型笔记(2)需遵循CC 4.0 BY-SA版权协议。








 京公网安备 11010802041100号
京公网安备 11010802041100号