:mans_shoe::mans_shoe::mans_shoe:
昨晚又把光头刮了一把,更光了,用疯子的刮眉刀刮头是给弄流血了,悲哀,以及谢特!
我一向喜欢对比两类相似的东西或者同类的两个版本,然后褒一个贬另一个,我不太喜欢中庸,也不太善于一分为二看问题,近期在做IPv6相关的事情,所以自然要和IPv4做对比,那么,哪怕一个细节上,我都忍不住要吐槽IPv4,但这并不意味着IPv4真的就那么挫,这只是我的特色而已。
还是以一个实际例子入手,先吐槽一顿IPv4,然后再说说IPv6怎么怎么好。
看以下的拓扑,一个有钱的用户从三大运营商同时接入互联网:
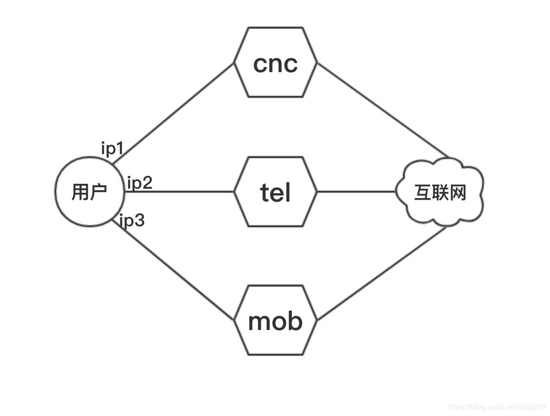
他要么是为了备份线路,要么是为了负载均衡,要么是为了实现访问联通的服务走联通的线路,访问电信的服务走电信的线路…无所谓,不管怎样,显然,它获得了三个IP地址。
此时它发起一个连接,想访问一个服务器,请问:
该连接的源IP地址如何选择?是ip1,ip2还是ip3?
无疑,这个服务器的IP地址肯定是接入三大运营商之一的,DNS会用发起请求的用户IP来给用户返回相同运营商的IP地址,答案似乎很简单,用相同运营商的呗。
是的,这是正确答案,走同运营商的线路可以避免冷土豆跨运营商转交,服务质量更能得到保证,走同运营商当然要用同运营商地址。
这一切都是在路由选择算法中完成的, 源地址选择和下一跳属于同一网段的地址!
我们只要知道了路由,就能决定选择哪个地址作为源IP地址。至于路由嘛,肯定是事先已经配置好的咯。或者说,随便用一个IP作为源地址,然后请求DNS解析域名,DNS返回的一般都是同运营商的目标地址,然后就用请求DNS解析时的IP作为源就得了。
所以,这件事并不难。
但是,路由和DNS是可信任的吗?路由配置就一定稳定可靠吗?如果说这个用户配置了三条等价的默认路由,怎么办呢?
# 联通默认路由
0.0.0.0/0 via $cnc metric 100
# 电信默认路由
0.0.0.0/0 via $tel metric 100
# 移动默认路由
0.0.0.0/0 via $mob metric 100
很多人都这么玩,最终所有上行流量都从cnc出去(取决于实现,要么是第一个配置的,要么是最后配置的),下行流量分布在三条线路,于是就造成了好多跨运营商传输。
你可能会说,可以配置Policy Routing啊,但是,哥,天下那么多服务器地址,你事先怎么知道哪些地址是联通的,哪些地址是电信的…
只要在你发起一条连接的第一个数据包时没有猜对下一跳,就意味着源地址会选错,源地址如果选择了不同运营商的,那么冷土豆转交将会伴随连接的整个生命周期。 所以说,路由一定要选对!
这又是一个先有鸡还是先有蛋的问题,好在我们能拿到一个条目非常全的地址库,或者DNS也能告诉我们这样一个东西,我们剩余的工作就是发挥愚公移山精卫填海铁杵磨成针的精神,去配置吧!
无论如何,这个事情对外部机制的依赖太多了,就选择一个源IP地址而已,却牵扯到了路由,DNS,Policy Routing…
等等!我最近就碰到配置上万条策略路由的!任何困难都难不倒勤劳的人民。
有没有更简单或者更复杂的方法呢?绝对有!我非常擅长解决这种问题。我用Policy Routing,IP Mark,conntrack就可以配置出这种效果,但是我在本文不说,反正非常复杂繁琐且易出错,说白了就是Trick。这种东西我能说一个礼拜,不然怎么能说自己靠着iptables,iproute2这些打通了内核协议栈任督二脉呢…
IPv6登场,事情起了变化,一切变得不一样!
先来看看IPv6地址的分配原则。
首先,IPv6的分配要遵循一个类似身份证的分层的原则:

这就使得所有的提供商在自己所辖的辖区内的路由都是可聚合的!IPv6地址提供商的层级结构和IPv6地址空间本身的层级结构完全一致!
分配机构一般会给一个高级别的运营商一个前缀比较短的整个网段,可以容纳百万级的子网,对于外部而言,这么大个运营商网络,可以从一条通告聚合路由抵达,该大运营商在其次级运营商那里分配地址也是同样的原则。
我这里定义一个 “提供商距离” 的概念。全世界所有的提供商形成一个树形结构,所谓的提供商距离就是两个IPv6地址的直接提供商在这棵树纵向上的距离。
请阅读:
RFC3177: https://tools.ietf.org/html/rfc3177
RFC6177: https://tools.ietf.org/html/rfc6177
对于 “提供商距离” 不用说太多,一个例子足矣。
如果自己有一个IPv6地址,随便给定另一个IPv6地址,我们算一下它们共享前缀的长度,就能知道它们共享到几级提供商。比如给定一个地址 240e:8880:4448:1300::222/64 ,问下面3个地址谁跟它的 提供商距离 最近:
a1=240e:8880:4448:1334::123/64
a2=240e:8870:4448:1334::123/64
a3=240e:8880:4448:1000::123/64
非常简单,直接最长前缀匹配就好了嘛!
看着一个地址,就能算出在IPv6地址空间,它离我的IPv6地址有多亲近。
所以,RFC3484里面的源IP地址选择策略中,有个Rule 8:
Rule 8: Use longest matching prefix.
【为啥是Rule 8而不是优先级更高呢?仔细想想!】
If CommonPrefixLen(SA, D) > CommonPrefixLen(SB, D), then prefer SA.
Similarly, if CommonPrefixLen(SB, D) > CommonPrefixLen(SA, D), then
prefer SB.
IPv6的源地址选择,不再像IPv4一样以下一跳为基准执行最长前缀匹配,而是直接以目标地址为基准执行最长前缀匹配!因此,IPv6的源地址选择不再依赖路由!
我们看看,对于IPv6地址的使用者而言,这个分配原则意味着什么。
这意味着,如果你搬了家,或者你的公司搬了家,你大概率不能继续使用原来的IPv6地址了,甚至你必须更改服务提供商,除非你搬到了同一个被分配了相同64位前缀网段的地理范围内。
如果在IPv4的世界,更换一个家庭或者企业的外部IP地址并不是什么问题,因为NAT遍地都是,没人会为内网每一个主机都分配一个公共地址,也没人有这个财力…但是在IPv6世界,NAT不再被建议使用,甚至强烈建议不使用,那么这就意味着,内网有多少设备,就要改多少设备的IP地址!
天啊,这是一场灾难!在这一点上,IPv4+NAT完胜!
幸运的是,IPv6分层聚合+IPv6自动配置(更多的是指无状态自动配置,缩写为SLAAC)可以完美胜任这一艰巨的任务!顺着一溜下去,你几乎不用动手,事情就完了!
…
之所以IPv4会有本文一开始陈述的那个问题,就是因为IPv4分配机制的无规则且混乱。
你搬家甚至可以带着你的IPv4地址一起搬,你交点服务费,运营商为你添加一条路由即可。理论上讲,如果每个人都这么玩,核心路由表项将会有数亿条。如果我们假设D类,E类地址也能参与分配,且没有私有地址,那么将会有43亿条的路由表项充斥各大路由器!
我来写一个程序,看看在常规的现代计算机上仅仅遍历43亿次执行递增操作需要多久:
#include
#include
int main()
{
unsigned int i = 0;
for (i = 0; i <0xffffffff; i++) {
//i++;
}
printf("%0x\n", i);
}
看一下执行时间:
[root@localhost NetworkManager]# time ./a.out
ffffffff
real 0m6.644s
user 0m6.637s
sys 0m0.007s
如果换成数亿次的路由表项匹配,呵呵。
IPv4的问题在于它过于灵活,过于灵活在业务无关的底层并不是什么好事。地址随意飘,加路由即可,地址随便分配,不考虑聚合,以为算法总是可以解决效率问题,这便是问题。
IPv6靠强制措施,硬性规定了很多条条框框,从地址分配时就考虑路由表的聚合问题。
我经常在京东买东西,因为我喜欢京东本地没库存宁可不卖也不让顾客遥遥无期等待。但是另一方面,我是个双重标准的人,我吐槽盒马鲜生,因为就隔一条小路,它就是不给送!绝不通融。
浙江温州皮鞋湿,下雨进水不会胖!







 京公网安备 11010802041100号
京公网安备 11010802041100号