参考资料
《Natural Language Processing: A Machine Learning Perspective 》
csdn大佬笔记
The oldest approaches to NLP
Based on human-developed rules and lexicons (基于人类制定的语言规则)
lexicon
also the lexicon
n.[sing.] (linguistics 语言) (某语言或学科、某人或群体使用的)全部词汇
Challenges in resolving ambiguities
语言的歧义性,一词多义给语言学家制定的规则提出了很大的挑战
a well-quoted example:上世纪60年代一个著名案例的例子
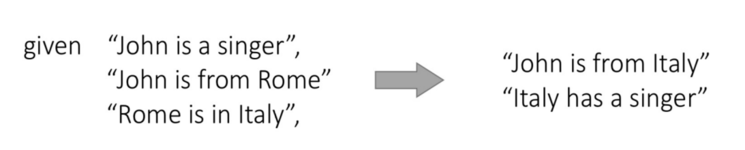
在机器翻译研究的初期,人们经常举一个例子来说明机器翻译任务的艰巨性。在英语中“The spirit is willing but the flesh is weak.”,意思是“心有余而力不足”。但是当时的某个机器翻译系统将这句英文翻译到俄语,然后再翻译回英语的时候,却变成了“The Voltka is strong but the meat is rotten.”,意思是“伏特加酒是浓的,但肉却腐烂了”。从字面意义上看,“spirit”(烈性酒)与“Voltka”(伏特加)对译似无问题,而“flesh”和“meat”也都有肉的意思。
基于统计的机器学习方法,从语言学家手工标注的数据中学到重要的统计意义的特征,并把这些特征作为知识来估算一个输入对应的不同输出的概率,这样就可以把最可能的输出作为统计的结果来反映给客户,语言学家的工作从设计规则参与算法编写变成了对数据集进行标注
计算能力提升, 大量数据训练参数很多的神经网络,输入输出的结构进行端到端关联
自然语言处理的神经网络可以在大规模的未标注的互联网语言文本进行预训练,再用少量语言学家标注的语料进行参数微调,神经网路表达能力非常强, 性能强大
Deep learning surpasses statistical methods( 优于,超过统计方法) as the domain approach
free from linguistic features (不需要语言特征)
very large neural models
pre-training over large raw text
(可以在庞大的原始文本上进行预训练)
We give an overview of NLP tasks in this section, which provides a background for discussing machine learning algorithms in the remaining chapters.
Note that our introduction of linguistic and task-specific concepts is brief, as this is not the main goal of the book. Interested readers can refer to dedicated materials listed in the chapter notes at the end of the chapter for further reading.
Syntactic Tasks investigate the composition structures of languages, ranging from the word level to the sentence level
词的形态划分 morphological analysis
the task of morphological analysis studies automatic prediction of morphological features of input words, such as morphemes.
词根 词缀 提取出来

分词 word segmentation
分词任务歧义性较强

符号化 tokenization

词性标注,语法标注,词类消疑 POS Tagging (part-of-speech tagging)

Part-of-speech(POS)
Basic syntactic role that words play in a sentence

前面的can是情态动词 , 后面的can是名词 罐子
一些常用的句法范式 Grammar formalisms for syntactic parsing
Tree adjoining grammars(TAG) 树邻接文法
constituent parsing 成分句法分析(也叫短语结构句法分析)
Constituent parsers assign phrase labels to constituent, also referred to as phrase-structure grammars.
通过层次化短语结构来表达一句话

a book 名词短语
bought a book for Mary 动词短语
Tim bought a book for Mary. 句子结构
成分句法分析就是通过算法自动找到一句话里面的层次短语结构
dependency parsing 依存句法分析
Dependency parsers analyze a sentence in head words and dependent words.
依存句法通过两个词之间的关系来组成一句话的结构

上例中有主语宾语修饰语等等关系,
CCG parsing 组合范畴句法分析
组合范畴句法是高度词汇化的句法

supertagging 浅层句法分析任务
Also called shallow parsing, a pre-processing step before parsing.
在组合范畴句法分析中,给每个单词打标签的这一步称为CCG supertagging
和成分句法相关的浅层句法分析任务叫 syntactic chunking
identify basic syntactic phrases from a given sentence
把一句话切成比较大的短语块

Word sense disambiguation (WSD) 词义消歧
The NLP task that disambiguates the sense of a word given a certain context, such as a sentence, is called word sense disambiguation (WSD).
Never trouble troubles till trouble troubles you.
I saw a man saw a saw with a saw.
我看见一个男人用锯子锯另一把锯子
Metaphor detection 隐喻检测
Metaphor detection is an NLP task to discover metaphoric uses of words in texts.
Sense relations between words
Synonyms :pairs of words with similar senses 同义词 /sɪnənɪmz/
Antonyms :pairs of words with opposite relations 反义词 /ˈæntəʊnɪmz/
Hyponyms :pairs of words in subtype–type relations 上下位词

Meronyms : pairs of words in part–whole relations. 组成部分
Analogy 类比
判断词对和词对之间的语义关系
Predicate-argument relations 谓词-论元结构
On the sentence level, the semantic relation between verbs and their syntactic subjects and objects belongs to predicate–argument relations, which denote meaning of events.
谓词:动词,事件
论元:事件的参与者或属性
A typical NLP task on predicate-argument structures is semantic role labelling (SRL,语义角色标注),

form of semantic representation
predicate–argument
frame structure
logic 逻辑表达式

lambda calculus λ表达式

semantic graphs 语义图
一个表达能力丰富的语义表示框架:Semantic graphs 语义图

text entailment(文本蕴含)是判断两句话之间语义关系的任务
也叫自然语言推理 natural language inference (NLI)
需要一个前提和一个假设

A discourse refers to a piece of text with multiple sub-topics and coherence relations between them.
Discourse parsing:Analyze the coherence relations between sub-topics in a discourse.
There are many different discourse structure formalisms. Rhetoric structure theory (RST) is a representative formalism which we use for discussion.
例
四个篇章单元, 电影有趣和Tim想看是并列关系, 这两句话和他这周不能去看 组成了反义、转折关系, 前三句话和他下周期末考试组成了解释关系
RST篇章分析的基本步骤叫 Discourse segmentation(篇章切分)
把一段长的文本切分为基本单元
前面四句话可以用一个长句子表达👇

篇章切分任务可以针对一句话或多句话
and but because这种关键词(discourse markers)可以在篇章切分中有帮助
上世纪90年代末为捕获网络舆情产生的任务
/数据挖掘兴起后和语言文字相关的挖掘任务

To identify all named entity mentions from a given piece of text 从给定文本找出所有提到的命名实体

指代消解其实属于Fundamental NLP tasks
resolves what a pronoun or noun phrase refers to (判断一句话中名词短语和代词指代什么)

这句话He代表Tim , it 代表book
Zero-pronoun resolution :detects and interprets dropped pronouns (零指代:检测和解释省略的代词)

检测省略的代词,并且判断它属于哪一个具体的对象
高中做语法单选题的回忆来了啊哈哈哈
Co-reference resolution:finds all expressions that refer to the same entities in a text

Relations between entities represent knowledge
common relations

hierarchical 可分层的
domain-specific 特定领域
identify relations between entity under a set of prespecified relation categories

图中的节点代表实体,节点之间的边代表实体之间的关系知识
是entity linking的related task
finds a canonical term for named entity mentions (为提到的命名实体找到一个规范术语)

Knowledge graphs allow knowledge inference
知识推理
Here events can be defined as open-domain semantic frames, or a set of specific frames of concern in a certain domain, such as “cooking”. Event mentions contain trigger words, which can be both verb phrases and noun phrases. The detection of event trigger words can be more challenging compared to detecting entity mentions since trigger words can take different parts of speech.
- 命名实体识别相关论文中常出现的mention该如何理解? - Sussurro的回答 - 知乎 https://www.zhihu.com/question/53590576/answer/2281734586
to identify mentions of events from texts
从文本中检测出触发词

Events have timing. While some events have happened, others are yet to happen or expected to happen. Several NLP tasks are related to event times. 👇
比如从互联网帖子里发现一些地区有人说的自然灾害等

事件之间也存在相互指代👇

Here a script refers to a set of partially ordered events in a stereotypical scenario, together with their participant roles.
aims to extract such commonsense knowledge automatically from narrative texts
从大量文本抽取脚本知识
订餐包含就坐、点餐、用餐、付款等小事件,这些小的事件有时候会部分出现,有时候会以不同的顺序出现
在语义学范畴,这种整体的事件框架叫script
Sentiment analysis, or opinion mining is an NLP task that extracts sentiment signals from texts.
There are numerous task variations.
sentiment classification
to predict the subjectivity and sentiment polarity(极性) of a given text, which can be a sentence or a full document.
The output can be a binary subjective/objective class, or a ternary(三元的) positive/negative/neutral class. More fine-grained(细粒度) output labels can be defined, such as a scale of [ −2, −1, 0, 1, 2], which corresponds to [very negative, negative, neutral, positive, very positive], respectively.
There are also tasks that offer more fine-grained details in sentiments.
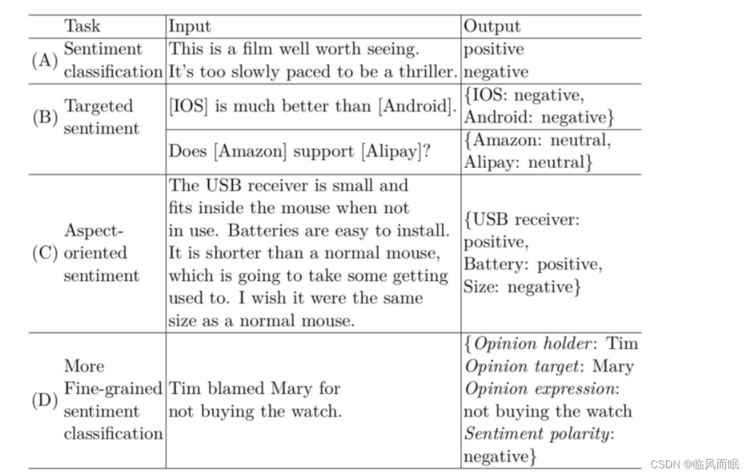
Sentiment analysis is also related to stance detection(立场检测), which is to detect the stance of a text towards a certain subject (i.e., “for” or “against”)
一个基础性的文本生成任务是语义分析任务的逆运算
The generation of natural language text from syntactic/semantic representations
给定一个语义图,任务的输出是表达其中语义的文字
语义到文字的生成也可以看作是图到文字的生成(graph-to-text generation)
Semantic dependency graphs (logical forms) example:

The generation of natural language text from syntactic/semantic representations
例

长文本→短文本 ,提取重要内容;可总结单篇文档,多篇文档(如报道同一事件的新闻)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rN7lOD6o-1670488706830)(https://cdn.jsdelivr.net/gh/xin007-kong/picture_new/img/20221208151004.png)]
从一种语言到另一种语言的生成任务

将带有语病文本自动纠正为正确文本的生成任务,可用于英语学习,文档编辑系统等
related tasks


综合性,不限定答案来源(知识库/网上文本),经常组合知识问答、阅读理解等各种方法
老师提到:一个应用场景就是 用户对下一代搜索引擎提出任何问题,引擎可以直接给出答案
最近的chatGpt应该就是吧哈哈哈 ,还可以对chatGpt指定回答的简洁程度
其实不是NLP的子问题 ,除了文字外,视频 图像等 也是 Information retrieval关心的对象,但语言文字是信息重要载体,所以信息检索和NLP有很大的交叉
也不是NLP的子任务,但是和NLP有密切联系
leverage text reviews for recommending(利用文字评论来推荐)
leverage 借助,利用;杠杆

通过文字进行数据分析从而寻找到重要信息和决策依据
derive high-quality information from text
如:
从机器学习的角度来看,NLP任务可以被分为少数类型)
NLP目前最主流最有效的是基于ML尤其是DL的方法,对于一个新的自然语言处理任务进行建模的时候,我们需要考虑任务的语言属性、机器学习属性、数据属性。
以命名实体识别为例
从机器学习角度来看这是一个序列标注的问题。
给定一段文本,我们需要看文本中哪些片段属于命名实体,并给这些片段打上标签。(决定作用)
从语言学角度来看,解决命名实体识别往往需要判断命名实体本身的拼写特点以及它上下文的特点,比如一个以大写字母为开头的英文单词,很可能是命名实体的一部分,比如United States
如果上下文是总统出访了某地,无论词的拼写是什么,它是一个地点命名实体的概率都很大,这些是语言学的特点
从数据角度看
如果我们有一套人工标注好的训练数据用来进行机器学习的训练,那么这套数据的标注规范(人是怎么标注命名实体的)、被标注的数据量的大小、不同类型的命名实体的分布是怎样的(统计概率是怎样的) 都会影响我们对方法的设计和选择
这三个角度里面,机器学习性质是起到最主要的决定作用的,数据特性也起到很大作用,机器学习性质相比于语言学特性在不同任务之间更通用,学习起来更方便
Although there is a plethora of NLP tasks in the linguistic or application perspective, NLP tasks
can be categorised into much fewer types when viewed from a machine learning perspective.(尽管从语言学或应用的角度来看,NLP任务非常多,但从机器学习的角度来看,NLP任务的类型要少得多。
NLP tasks are many and dynamically evolving, but fewer according to machine learning nature (NLP任务很多,而且是动态发展的,但根据机器学习的性质来划分,可以归为少数几类)
How can we categorise NLP tasks according to their machine learning nature? There are different perspectives.
Output is a distinct label from a set 输入是文本,输出是类别标签
e.g. 情感分类、主题分类、垃圾邮件分类、rumour detection 谣言检测等等
Outputs are structures with inter-related sub structures

e.g. POS-tagging and dependency parsing
Many NLP tasks are structured prediction tasks, As a result, how to deal with structures is a highly important problem for NLP.
(在NLP研究的相对较少)
In some cases, the output is neither a class label nor a structure, but a real-valued number.
When the set of training data does not contain gold-standard outputs (i.e., manually labelled POS-tags for POS-tagging and manually labelled syntactic trees for parsing), the task setting is unsupervised learning.
In contrast, when the set of training data consists of gold-standard outputs the task setting is supervised learning.
In between the two settings, semi-supervised learning uses both data with gold-standard labels and data without annotation.
For semi-supervised learning, a relatively small set of data with human labels and a relatively large amount of raw text can be used simultaneously(同时地).
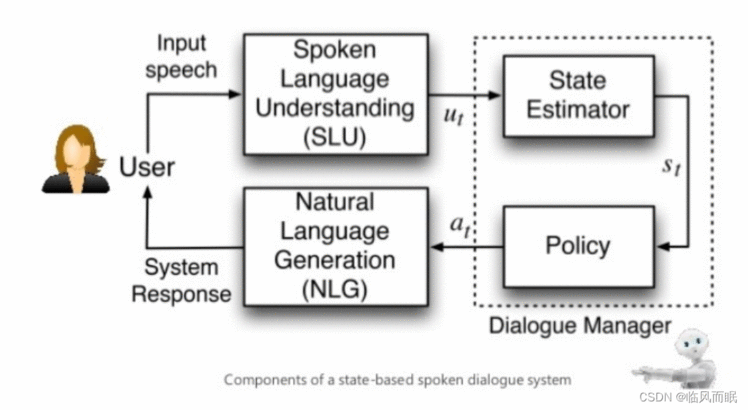
NLP toolkits
Word level syntax
Syntax
Lexical semantics
Semantic roles
Logic
AMR
Segrada - semantic graph database https://segrada.org/
Text entailment
Discourse segmentation
NER
Co-reference
Relation extraction
Knowledge graph
Events
Sentiment
Machine translation
Summarization
Grammar error correction
QA
Dialogue system
Recommendation system
Text mining and text analytics
![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有