1. MySQL查询慢是什么体验?
大多数互联网应用场景都是读多写少,业务逻辑更多分布在写上。对读的要求大概就是要快。那么都有什么原因会导致我们完成一次出色的慢查询呢?
1.1 索引
在数据量不是很大时,大多慢查询可以用索引解决,大多慢查询也因为索引不合理而产生。
MySQL 索引基于 B+ 树,这句话相信面试都背烂了,接着就可以问最左前缀索引、 B+ 树和各种树了。
说到最左前缀,实际就是组合索引的使用规则,使用合理组合索引可以有效的提高查询速度,为什么呢?
因为索引下推。如果查询条件包含在了组合索引中,比如存在组合索引(a,b),查询到满足 a 的记录后会直接在索引内部判断 b 是否满足,减少回表次数。同时,如果查询的列恰好包含在组合索引中,即为覆盖索引,无需回表。索引规则估计都知道,实际开发中也会创建和使用。问题可能更多的是:为什么建了索引还慢?
1.1.1 什么原因导致索引失效
建了索引还慢,多半是索引失效(未使用),可用 explain 分析。索引失效常见原因有 :
where 中使用 !&#61; 或 <> 或 or 或表达式或函数&#xff08;左侧&#xff09;
like 语句 % 开头
字符串未加’’
索引字段区分度过低&#xff0c;如性别
未匹配最左前缀
(一张嘴就知道老面试题了) 为什么这些做法会导致失效&#xff0c;成熟的 MySQL 也有自己的想法。
如果要 MySQL 给一个理由&#xff0c;还是那棵 B&#43; 树。
当在 查询 where &#61; 左侧使用表达式或函数时&#xff0c;如字段 A 为字符串型且有索引, 有 where length(a) &#61; 6查询&#xff0c;这时传递一个 6 到 A 的索引树&#xff0c;不难想象在树的第一层就迷路了。
隐式类型转换和隐式字符编码转换也会导致这个问题。
隐式类型转换对于 JOOQ 这种框架来说一般倒不会出现。
隐式字符编码转换在连表查询时倒可能出现&#xff0c;即连表字段的类型相同但字符编码不同。
至于 Like 语句 % 开头、字符串未加 ’’ 原因基本一致&#xff0c;MySQL 认为对索引字段的操作可能会破坏索引有序性就机智的优化掉了。
不过&#xff0c;对于如性别这种区分度过低的字段&#xff0c;索引失效就不是因为这个原因。
为什么索引区分度低的字段不要加索引。盲猜效率低&#xff0c;效率的确低&#xff0c;有时甚至会等于没加。
对于非聚簇索引&#xff0c;是要回表的。假如有 100 条数据&#xff0c;在 sex 字段建立索引&#xff0c;扫描到 51 个 male&#xff0c;需要再回表扫描 51 行。还不如直接来一次全表扫描呢。
所以&#xff0c;InnoDB 引擎对于这种场景就会放弃使用索引&#xff0c;至于区分度多低多少会放弃&#xff0c;大致是某类型的数据占到总的 30% 左右时&#xff0c;就会放弃使用该字段的索引&#xff0c;有兴趣可以试一下。
前面说到大多慢查询都源于索引&#xff0c;怎么建立并用好索引。这里有一些简单的规则。
索引下推&#xff1a;性别字段不适合建索引&#xff0c;但确实存在查询场景怎么办&#xff1f;如果是多条件查询&#xff0c;可以建立联合索引利用该特性优化。
覆盖索引&#xff1a;也是联合索引&#xff0c;查询需要的信息在索引里已经包含了&#xff0c;就不会再回表了。
前缀索引&#xff1a;对于字符串&#xff0c;可以只在前 N 位添加索引&#xff0c;避免不必要的开支。假如的确需要如关键字查询&#xff0c;那交给更合适的如 ES 或许更好。
不要对索引字段做函数操作
对于确定的、写多读少的表或者频繁更新的字段都应该考虑索引的维护成本。
有时&#xff0c;建立了猛一看挺正确的索引&#xff0c;但事情却没按计划发展。就像“为啥 XXX 有索引&#xff0c;根据它查询还是慢查询”。
此刻没准要自信点&#xff1a;我的代码不可能有 BUG&#xff0c;肯定是 MySQL 出了问题。MySQL 的确可能有点问题。
这种情况常见于建了一大堆索引&#xff0c;查询条件一大堆。没使用你想让它用的那一个&#xff0c;而是选了个区分度低的&#xff0c;导致过多的扫描。造成的原因基本有两个&#xff1a;
信息统计不准确&#xff1a;可以使用 analyze table x重新分析。
优化器误判&#xff1a;可以 force index强制指定。或修改语句引导优化器&#xff0c;增加或删除索引绕过。
但根据我浅薄的经验来看&#xff0c;更可能是因为你建了些没必要的索引导致的。不会真有人以为 MySQL 没自己机灵吧&#xff1f;
除了上面这些索引原因外&#xff0c;还有下面这些不常见或者说不好判断的原因存在。
在 MySQL 5.5 版本中引入了 MDL&#xff0c;对一个表做 CRUD 操作时&#xff0c;自动加 MDL 读锁&#xff1b;对表结构做变更时&#xff0c;加 MDL 写锁。读写锁、写锁间互斥。
当某语句拿 MDL 写锁就会阻塞 MDL 读锁&#xff0c;可以使用show processlist命令查看处于Waiting for table metadata lock状态的语句。
flush 很快&#xff0c;大多是因为 flush 命令被别的语句堵住&#xff0c;它又堵住了 select 。通过show processlist命令查看时会发现处于Waiting for table flush状态。
某事物持有写锁未提交。
InnoDB 默认级别是可重复读。设想一个场景&#xff1a;事物 A 开始事务&#xff0c;事务 B 也开始执行大量更新。B 率先提交&#xff0c; A 是当前读&#xff0c;就要依次执行 undo log &#xff0c;直到找到事务 B 开始前的值。
在未二次开发的 MYSQL 中&#xff0c;上亿的表肯定算大表&#xff0c;这种情况即使在索引、查询层面做到了较好实现&#xff0c;面对频繁聚合操作也可能会出现 IO 或 CPU 瓶颈&#xff0c;即使是单纯查询&#xff0c;效率也会下降。
且 Innodb 每个 B&#43; 树节点存储容量是 16 KB&#xff0c;理论上可存储 2kw 行左右&#xff0c;这时树高为3层。我们知道&#xff0c;innodb_buffer_pool 用来缓存表及索引&#xff0c;如果索引数据较大&#xff0c;缓存命中率就堪忧&#xff0c;同时 innodb_buffer_pool 采用 LRU 算法进行页面淘汰&#xff0c;如果数据量过大&#xff0c;对老或非热点数据的查询可能就会把热点数据给挤出去。
所以对于大表常见优化即是分库分表和读写分离了。
是分库还是分表呢&#xff1f;这要具体分析。
如果磁盘或网络有 IO 瓶颈&#xff0c;那就要分库和垂直分表。
如果是 CPU 瓶颈&#xff0c;即查询效率偏低&#xff0c;水平分表。
水平即切分数据&#xff0c;分散原有数据到更多的库表中。
垂直即按照业务对库&#xff0c;按字段对表切分。
工具方面有 sharding-sphere、TDDL、Mycat。动起手来需要先评估分库、表数&#xff0c;制定分片规则选 key&#xff0c;再开发和数据迁移&#xff0c;还要考虑扩容问题。
实际运行中&#xff0c;写问题不大&#xff0c;主要问题在于唯一 ID 生成、非 partition key 查询、扩容。
唯一 ID 方法很多&#xff0c;DB 自增、Snowflake、号段、一大波GUID算法等。
非 partition key 查询常用映射法解决&#xff0c;映射表用到覆盖索引的话还是很快的。或者可以和其他 DB 组合。
扩容要根据分片时的策略确定&#xff0c;范围分片的话就很简单&#xff0c;而随机取模分片就要迁移数据了。也可以用范围 &#43; 取模的模式分片&#xff0c;先取模再范围&#xff0c;可以避免一定程度的数据迁移。
当然&#xff0c;如果分库还会面临事务一致性和跨库 join 等问题。
分表针对大表解决 CPU 瓶颈&#xff0c;分库解决 IO 瓶颈&#xff0c;二者将存储压力解决了。但查询还不一定。
如果落到 DB 的 QPS 还是很高&#xff0c;且读远大于写&#xff0c;就可以考虑读写分离&#xff0c;基于主从模式将读的压力分摊&#xff0c;避免单机负载过高&#xff0c;同时也保证了高可用&#xff0c;实现了负载均衡。
主要问题有过期读和分配机制。
过期读&#xff0c;也就是主从延时问题&#xff0c;这个对于。
分配机制&#xff0c;是走主还是从库。可以直接代码中根据语句类型切换或者使用中间件。
以上列举了 MySQL 常见慢查询原因和处理方法&#xff0c;介绍了应对较大数据场景的常用方法。
分库分表和读写分离是针对大数据或并发场景的&#xff0c;同时也为了提高系统的稳定和拓展性。但也不是所有的问题都最适合这么解决。
前文有提到对于关键字查询可以使用 ES。那接着聊聊 ES 。
2.1 可以干什么
ES 是基于 Lucene 的近实时分布式搜索引擎。使用场景有全文搜索、NoSQL Json 文档数据库、监控日志、数据采集分析等。
对非数据开发来说&#xff0c;常用的应该就是全文检索和日志了。ES 的使用中&#xff0c;常和 Logstash, Kibana 结合&#xff0c;也成为 ELK 。先来瞧瞧日志怎么用的。
下面是我司日志系统某检索操作&#xff1a;打开 Kibana 在 Discover 页面输入格式如 “xxx” 查询。
该操作可以在 Dev Tools 的控制台替换为&#xff1a;
GET yourIndex/_search
{ "from" : 0, "size" : 10, "query" : { "match_phrase" : { "log" : "xxx" } }
}
什么意思&#xff1f;Discover 中加上 “” 和 console 中的 match_phrase 都代表这是一个短语匹配&#xff0c;意味着只保留那些包含全部搜索词项&#xff0c;且位置与搜索词项相同的文档。
在 ES 7.0 之前存储结构是 Index -> Type -> Document&#xff0c;按 MySQL 对比就是 database - table - id(实际这种对比不那么合理)。7.0 之后 Type 被废弃了&#xff0c;就暂把 index 当做 table 吧。
在 Dev Tools 的 Console 可以通过以下命令查看一些基本信息。也可以替换为 crul 命令。
GET /_cat/health?v&pretty&#xff1a;查看集群健康状态
GET /_cat/shards?v &#xff1a;查看分片状态
GET yourindex/_mapping :index mapping结构
GET yourindex/_settings :index setting结构
GET /_cat/indices?v :查看当前节点所有索引信息
重点是 mapping 和 setting &#xff0c;mapping 可以理解为 MySQL 中表的结构定义&#xff0c;setting 负责控制如分片数量、副本数量。
以下是截取了某日志 index 下的部分 mapping 结构&#xff0c;ES 对字符串类型会默认定义成 text &#xff0c;同时为它定义一个叫做 keyword 的子字段。这两的区别是&#xff1a;text 类型会进行分词&#xff0c; keyword 类型不会进行分词。
"******": { "mappings": { "doc": { "properties": { "appname": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } }
2.3 ES 查询为什么快&#xff1f;
分词是什么意思&#xff1f;看完 ES 的索引原理你就 get 了。
ES 基于倒排索引。嘛意思&#xff1f;传统索引一般是以文档 ID 作索引&#xff0c;以内容作为记录。倒排索引相反&#xff0c;根据已有属性值&#xff0c;去找到相应的行所在的位置&#xff0c;也就是将单词或内容作为索引&#xff0c;将文档 ID 作为记录。
下图是 ES 倒排索引的示意图&#xff0c;由 Term index&#xff0c;Team Dictionary 和 Posting List 组成。
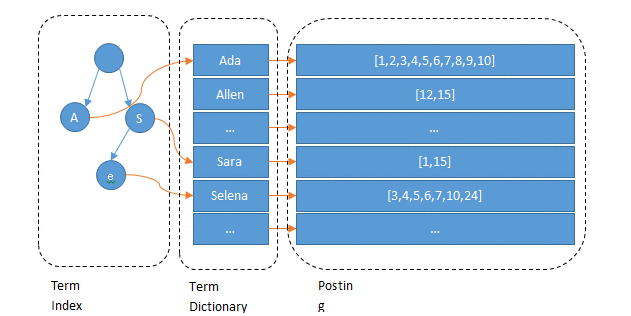
图中的 Ada、Sara 被称作 term&#xff0c;其实就是分词后的词了。如果把图中的 Term Index 去掉&#xff0c;是不是有点像 MySQL 了&#xff1f;Term Dictionary 就像二级索引&#xff0c;但 MySQL 是保存在磁盘上的&#xff0c;检索一个 term 需要若干次的 random access 磁盘操作。
而 ES 在 Term Dictionary 基础上多了层 Term Index &#xff0c;它以 FST 形式保存在内存中&#xff0c;保存着 term 的前缀&#xff0c;借此可以快速的定位到 Term dictionary 的本 term 的 offset 。而且 FST 形式和 Term dictionary 的 block 存储方式都很节省内存和磁盘空间。
到这就知道为啥快了&#xff0c;就是因为有了内存中的 Term Index , 它为 term 的索引 Term Dictionary 又做了一层索引。
不过&#xff0c;也不是说 ES 什么查询都比 MySQL 快。检索大致分为两类。
ES 的索引存储的就是分词排序后的结果。比如图中的 Ada&#xff0c;在 MySQL 中 %da% 就扫全表了&#xff0c;但对 ES 来说可以快速定位
2.3.2 精确检索
该情况其实相差是不大的&#xff0c;因为 Term Index 的优势没了&#xff0c;却还要借此找到在 term dictionary 中的位置。也许由于 MySQL 覆盖索引无需回表会更快一点。
2.4 什么时候用 ES
如前所述&#xff0c;对于业务中的查询场景什么时候适合使用 ES &#xff1f;我觉得有两种。
2.4.1 全文检索
在 MySQL 中字符串类型根据关键字模糊查询就是一场灾难&#xff0c;对 ES 来说却是小菜一碟。具体场景&#xff0c;比如消息表对消息内容的模糊查询&#xff0c;即聊天记录查询。
但要注意&#xff0c;如果需要的是类似广大搜索引擎的关键字查询而非日志的短语匹配查询&#xff0c;就需要对中文进行分词处理&#xff0c;最广泛使用的是 ik 。Ik 分词器的安装这里不再细说。
什么意思呢&#xff1f;
分词
开头对日志的查询&#xff0c;键入 “我可真是个机灵鬼” 时&#xff0c;只会得到完全匹配的信息。
而倘若去掉 “”&#xff0c;又会得到按照 “我”、“可”&#xff0c;“真”….分词匹配到的所有信息&#xff0c;这明显会返回很多信息&#xff0c;也是不符合中文语义的。实际期望的分词效果大概是“我”、“可”、“真是”&#xff0c;“机灵鬼”&#xff0c;之后再按照这种分词结果去匹配查询。
这是 ES 默认的分词策略对中文的支持不友善导致的&#xff0c;按照英语单词字母来了&#xff0c;可英语单词间是带有空格的。这也是不少国外软件中文搜索效果不 nice 的原因之一。
对于该问题&#xff0c;你可以在 console 使用下方命令&#xff0c;测试当前 index 的分词效果。
POST yourindex/_analyze { "field":"yourfield", "text":"我可真是个机灵鬼"
}
如果数据量够大&#xff0c;表字段又够多。把所有字段信息丢到 ES 里创建索引是不合理的。使用 MySQL 的话那就只能按前文提到的分库分表、读写分离来了。何不组合下。
将要参与查询的字段信息加上 id&#xff0c;放入 ES&#xff0c;做好分词。将全量信息放入 MySQL&#xff0c;通过 id 快速检索。
如果要省去分库分表什么的&#xff0c;或许可以抛弃 MySQL &#xff0c;选择分布式数据库&#xff0c;比如 HBASE , 对于这种 NOSQL 来说&#xff0c;存储能力海量&#xff0c;扩容 easy &#xff0c;根据 rowkey 查询也很快。
以上思路都是经典的索引与数据存储隔离的方案了。
当然&#xff0c;摊子越大越容易出事&#xff0c;也会面临更多的问题。使用 ES 作索引层&#xff0c;数据同步、时序性、mapping 设计、高可用等都需要考虑。
毕竟和单纯做日志系统对比&#xff0c;日志可以等待&#xff0c;用户不能。
2.5 小结
本节简单介绍了 ES 为啥快&#xff0c;和这个快能用在哪。现在你可以打开 Kibana 的控制台试一试了。
如果想在 Java 项目中接入的话&#xff0c;有 SpringBoot 加持&#xff0c;在 ES 环境 OK 的前提下&#xff0c;完全是开箱即用&#xff0c;就差一个依赖了。基本的 CRUD 支持都是完全 OK 的。
前面有提到 HBASE , 什么是 HBASE &#xff0c;鉴于篇幅这里简单说说。
3.1 存储结构
关系型数据库如 MySQL 是按行来的。

HBASE 是按列的&#xff08;实际是列族&#xff09;。列式存储上表就会变成&#xff1a;

下图是一个 HBASE 实际的表模型结构。

Row key 是主键&#xff0c;按照字典序排序。TimeStamp 是版本号。info 和 area 都是列簇&#xff08;column Family&#xff09;&#xff0c;列簇将表进行横向切割。name、age 叫做列&#xff0c;属于某一个列簇&#xff0c;可进行动态添加。Cell 是具体的 Value 。
3.2 OLTP 和 OLAP
数据处理大致可分成两大类&#xff1a;联机事务处理OLTP&#xff08;on-line transaction processing&#xff09;、联机分析处理OLAP&#xff08;On-Line Analytical Processing&#xff09;。
OLTP是传统的关系型数据库的主要应用&#xff0c;主要是基本的、日常的事务处理。
OLAP是数据仓库系统的主要应用&#xff0c;支持复杂分析&#xff0c;侧重决策支持&#xff0c;提供直观易懂的查询结果。
面向列的适合做 OLAP&#xff0c;面向行的适用于联机事务处理(OLTP)。不过 HBASE 并不是 OLAP &#xff0c;他没有 transaction&#xff0c;实际上也是面向 CF 的。一般也没多少人用 HBASE 做 OLAP 。
3.3 RowKey
HBASE 表设计的好不好&#xff0c;就看 RowKey 设计。这是因为 HBASE 只支持三种查询方式
1、基于 Rowkey 的单行查询 2、基于 Rowkey 的范围扫描 3、全表扫描
可见 HBASE 并不支持复杂查询。
3.4 使用场景
HBASE 并非适用于实时快速查询。它更适合写密集型场景&#xff0c;它拥用快速写入能力&#xff0c;而查询对于单条或小面积查询是 OK 的&#xff0c;当然也只能根据 rowkey。但它的性能和可靠性非常高&#xff0c;不存在单点故障。
个人觉得软件开发是循序渐进的&#xff0c;技术服务于项目&#xff0c;合适比新颖复杂更重要。
如何完成一次快速的查询&#xff1f;最该做的还是先找找自己的 Bug&#xff0c;解决了当前问题再创造新问题。
本文列举到的部分方案对于具体实现大多一笔带过&#xff0c;实际无论是 MySQL 的分表还是 ES 的业务融合都会面临很多细节和困难的问题&#xff0c;搞工程的总要绝知此事要躬行。
作者&#xff1a;llc687
https://llc687.top/post/如何完成一次快速的查询
https://juejin.im/post/5bfe771251882509a7681b3a
https://wsgzao.github.io/post/elk/)https://wsgzao.github.io/post/elk/
https://www.cnblogs.com/luxiaoxun/p/5452502.html
https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-bigdata-hbase/index.html







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有