当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
如果这个包含死信的队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机(Dead Letter Exchange,检查DLX)。
如图,一个消息被消费者拒绝了,变成了死信:
因为simple.queue绑定了死信交换机 dl.direct,因此死信会投递给这个交换机:
如果这个死信交换机也绑定了一个队列,则消息最终会进入这个存放死信的队列:
另外,队列将死信投递给死信交换机时,必须知道两个信息:
这样才能确保投递的消息能到达死信交换机,并且正确的路由到死信队列。
在失败重试策略中,默认的RejectAndDontRequeueRecoverer会在本地重试次数耗尽后,发送reject给RabbitMQ,消息变成死信,被丢弃。
我们可以给simple.queue添加一个死信交换机,给死信交换机绑定一个队列。这样消息变成死信后也不会丢弃,而是最终投递到死信交换机,路由到与死信交换机绑定的队列。
我们在consumer服务中,定义一组死信交换机、死信队列:
// 声明普通的 simple.queue队列,并且为其指定死信交换机:dl.direct
@Bean
public Queue simpleQueue2(){
return QueueBuilder.durable("simple.queue") // 指定队列名称,并持久化
.deadLetterExchange("dl.direct") // 指定死信交换机
.build();
}
// 声明死信交换机 dl.direct
@Bean
public DirectExchange dlExchange(){
return new DirectExchange("dl.direct", true, false);
}
// 声明存储死信的队列 dl.queue
@Bean
public Queue dlQueue(){
return new Queue("dl.queue", true);
}
// 将死信队列 与 死信交换机绑定
@Bean
public Binding dlBinding(){
return BindingBuilder.bind(dlQueue()).to(dlExchange()).with("simple");
}
什么样的消息会成为死信?
死信交换机的使用场景是什么?
一个队列中的消息如果超时未消费,则会变为死信,超时分为两种情况:
实现TTL
//编写ttl.direct、ttl.queue并绑定死信交换机
@Configuration
public class TTLMessageConf {
/**
* 创建了一个绑定了死信交换机的队列
* @return
*/
@Bean
public Queue ddlQueue(){
return QueueBuilder.durable("ttl.queue")
.ttl(10000)
.deadLetterExchange("dl.direct")
.deadLetterRoutingKey("dl")
.build();
}
/**
* 这是一个交换机
* @return
*/
@Bean
public DirectExchange directExchange(){
return new DirectExchange("ttl.direct");
}
/**
* 将队列和交换机绑定
* @return
*/
@Bean
public Binding ttlBinding(){
return BindingBuilder.bind(ddlQueue()).to(directExchange()).with("ttl");
}
}
//创建私信交换机、队列和消费者
@RabbitListener(bindings = {
@QueueBinding(
value = @Queue(name = "dl.queue",durable = "true"),
exchange = @Exchange(name = "dl.direct",durable = "true"),
key = "dl"
)
})
public void listenDlQueue(String msg){
log.info("消费者接收到simple.queue的消息:{}",msg);
}
在发送消息时,也可以指定TTL:
@Test
public void testTTLMsg() {
// 创建消息
Message message = MessageBuilder
.withBody("hello, ttl message".getBytes(StandardCharsets.UTF_8))
.setExpiration("5000")
.build();
// 消息ID,需要封装到CorrelationData中
CorrelationData correlatiOnData= new CorrelationData(UUID.randomUUID().toString());
// 发送消息
rabbitTemplate.convertAndSend("ttl.direct", "ttl", message, correlationData);
log.debug("发送消息成功");
}
利用TTL结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列(Delay Queue)模式。
延迟队列的使用场景包括:
DelayExchange需要将一个交换机声明为delayed类型。当我们发送消息到delayExchange时,流程如下:
//声明延迟交换机
//1.基于注解的方式声明延迟交换机
@RabbitListener(bindings = {
@QueueBinding(
value = @Queue(name = ""),
exchange = @Exchange(name = "",delayed = "true"),//这里选择delay属性为true
key = "hello"
)
})
public void listenDelay(){
}
//2.基于@Bean的方式声明延迟交换机
@Bean
public DirectExchange delayExchange(){
return ExchangeBuilder.directExchange("delay")
.delayed()//使用delayed
.durable(true)
.build();
}
发送消息
发送消息时,一定要携带x-delay属性,指定延迟的时间:
延迟队列插件的使用步骤包括哪些?
•声明一个交换机,添加delayed属性为true
•发送消息时,添加x-delay头,值为超时时间
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
解决消息堆积有两种思路:
要提升队列容积,把消息保存在内存中显然是不行的。
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的概念,也就是惰性队列。惰性队列的特征如下:
而要设置一个队列为惰性队列,只需要在声明队列时,指定x-queue-mode属性为lazy即可。可以通过命令行将一个运行中的队列修改为惰性队列:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
命令解读:
rabbitmqctl :RabbitMQ的命令行工具set_policy :添加一个策略Lazy :策略名称,可以自定义"^lazy-queue$" :用正则表达式匹配队列的名字'{"queue-mode":"lazy"}' :设置队列模式为lazy模式--apply-to queues :策略的作用对象,是所有的队列@Bean
public Queue lazyQueue(){
return QueueBuilder.durable("lazyQueue")
.lazy()
.build();
}
@RabbitListener(bindings = {
@QueueBinding(
value = @Queue(name=""),
exchange = @Exchange(name=""),
key = "hello",
arguments = @Argument(name = "x-queue-mode",value = "lazy")
)
})
public void lazyQueue(){
}
消息堆积问题的解决方案?
惰性队列的优点有哪些?
惰性队列的缺点有哪些?
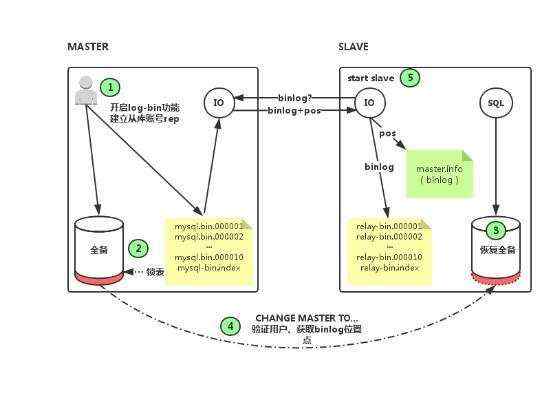
RabbitMQ的是基于Erlang语言编写,而Erlang又是一个面向并发的语言,天然支持集群模式。RabbitMQ的集群有两种模式:
•普通集群:是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力。
•镜像集群:是一种主从集群,普通集群的基础上,添加了主从备份功能,提高集群的数据可用性。
镜像集群虽然支持主从,但主从同步并不是强一致的,某些情况下可能有数据丢失的风险。因此在RabbitMQ的3.8版本以后,推出了新的功能:仲裁队列来代替镜像集群,底层采用Raft协议确保主从的数据一致性。
普通集群,或者叫标准集群(classic cluster),具备下列特征:
结构如图:
在RabbitMQ的官方文档中,讲述了两种集群的配置方式:
我们先来看普通模式集群,我们的计划部署3节点的mq集群:
| 主机名 | 控制台端口 | amqp通信端口 |
|---|---|---|
| mq1 | 8081 ---> 15672 | 8071 ---> 5672 |
| mq2 | 8082 ---> 15672 | 8072 ---> 5672 |
| mq3 | 8083 ---> 15672 | 8073 ---> 5672 |
集群中的节点标示默认都是:rabbit@[hostname],因此以上三个节点的名称分别为:
获取COOKIE
RabbitMQ底层依赖于Erlang,而Erlang虚拟机就是一个面向分布式的语言,默认就支持集群模式。集群模式中的每个RabbitMQ 节点使用 COOKIE 来确定它们是否被允许相互通信。
要使两个节点能够通信,它们必须具有相同的共享秘密,称为Erlang COOKIE。COOKIE 只是一串最多 255 个字符的字母数字字符。
每个集群节点必须具有相同的 COOKIE。实例之间也需要它来相互通信。
我们先在之前启动的mq容器中获取一个COOKIE值,作为集群的COOKIE。执行下面的命令:
docker exec -it mq cat /var/lib/rabbitmq/.erlang.COOKIE
可以看到COOKIE值如下:
ABSDWSBQLMYQZPLNPILH
接下来,停止并删除当前的mq容器,我们重新搭建集群。
docker rm -f mq
准备集群配置
在/tmp目录新建一个配置文件 rabbitmq.conf:
cd /tmp
# 创建文件
touch rabbitmq.conf
文件内容如下:
loopback_users.guest = false
listeners.tcp.default = 5672
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@mq1
cluster_formation.classic_config.nodes.2 = rabbit@mq2
cluster_formation.classic_config.nodes.3 = rabbit@mq3
再创建一个文件,记录COOKIE
cd /tmp
# 创建COOKIE文件
touch .erlang.COOKIE
# 写入COOKIE
echo "ABSDWSBQLMYQZPLNPILH" > .erlang.COOKIE
# 修改COOKIE文件的权限
chmod 600 .erlang.COOKIE
准备三个目录,mq1、mq2、mq3:
cd /tmp
# 创建目录
mkdir mq1 mq2 mq3
然后拷贝rabbitmq.conf、COOKIE文件到mq1、mq2、mq3:
# 进入/tmp
cd /tmp
# 拷贝
cp rabbitmq.conf mq1
cp rabbitmq.conf mq2
cp rabbitmq.conf mq3
cp .erlang.COOKIE mq1
cp .erlang.COOKIE mq2
cp .erlang.COOKIE mq3
启动集群
创建一个网络:
docker network create mq-net
运行命令
docker run -d --net mq-net \
-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.COOKIE:/var/lib/rabbitmq/.erlang.COOKIE \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq1 \
--hostname mq1 \
-p 8071:5672 \
-p 8081:15672 \
rabbitmq:3.8-management
docker run -d --net mq-net \
-v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.COOKIE:/var/lib/rabbitmq/.erlang.COOKIE \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq2 \
--hostname mq2 \
-p 8072:5672 \
-p 8082:15672 \
rabbitmq:3.8-management
docker run -d --net mq-net \
-v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.COOKIE:/var/lib/rabbitmq/.erlang.COOKIE \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq3 \
--hostname mq3 \
-p 8073:5672 \
-p 8083:15672 \
rabbitmq:3.8-management
在刚刚的案例中,一旦创建队列的主机宕机,队列就会不可用。不具备高可用能力。如果要解决这个问题,必须使用官方提供的镜像集群方案。
官方文档地址:https://www.rabbitmq.com/ha.html
默认情况下,队列只保存在创建该队列的节点上。而镜像模式下,创建队列的节点被称为该队列的主节点,队列还会拷贝到集群中的其它节点,也叫做该队列的镜像节点。
但是,不同队列可以在集群中的任意节点上创建,因此不同队列的主节点可以不同。甚至,一个队列的主节点可能是另一个队列的镜像节点。
用户发送给队列的一切请求,例如发送消息、消息回执默认都会在主节点完成,如果是从节点接收到请求,也会路由到主节点去完成。镜像节点仅仅起到备份数据作用。
当主节点接收到消费者的ACK时,所有镜像都会删除节点中的数据。
总结如下:
镜像模式的配置有3种模式:
| ha-mode | ha-params | 效果 |
|---|---|---|
| 准确模式exactly | 队列的副本量count | 集群中队列副本(主服务器和镜像服务器之和)的数量。count如果为1意味着单个副本:即队列主节点。count值为2表示2个副本:1个队列主和1个队列镜像。换句话说:count = 镜像数量 + 1。如果群集中的节点数少于count,则该队列将镜像到所有节点。如果有集群总数大于count+1,并且包含镜像的节点出现故障,则将在另一个节点上创建一个新的镜像。 |
| all | (none) | 队列在群集中的所有节点之间进行镜像。队列将镜像到任何新加入的节点。镜像到所有节点将对所有群集节点施加额外的压力,包括网络I / O,磁盘I / O和磁盘空间使用情况。推荐使用exactly,设置副本数为(N / 2 +1)。 |
| nodes | node names | 指定队列创建到哪些节点,如果指定的节点全部不存在,则会出现异常。如果指定的节点在集群中存在,但是暂时不可用,会创建节点到当前客户端连接到的节点。 |
这里我们以rabbitmqctl命令作为案例来讲解配置语法。
语法示例:
rabbitmqctl set_policy ha-two "^two\." '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
rabbitmqctl set_policy:固定写法ha-two:策略名称,自定义"^two\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以two.开头的队列名称'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}': 策略内容"ha-mode":"exactly":策略模式,此处是exactly模式,指定副本数量"ha-params":2:策略参数,这里是2,就是副本数量为2,1主1镜像"ha-sync-mode":"automatic":同步策略,默认是manual,即新加入的镜像节点不会同步旧的消息。如果设置为automatic,则新加入的镜像节点会把主节点中所有消息都同步,会带来额外的网络开销rabbitmqctl set_policy ha-all "^all\." '{"ha-mode":"all"}'
ha-all:策略名称,自定义"^all\.":匹配所有以all.开头的队列名'{"ha-mode":"all"}':策略内容"ha-mode":"all":策略模式,此处是all模式,即所有节点都会称为镜像节点rabbitmqctl set_policy ha-nodes "^nodes\." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
rabbitmqctl set_policy:固定写法ha-nodes:策略名称,自定义"^nodes\.":匹配队列的正则表达式,符合命名规则的队列才生效,这里是任何以nodes.开头的队列名称'{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}': 策略内容"ha-mode":"nodes":策略模式,此处是nodes模式"ha-params":["rabbit@mq1", "rabbit@mq2"]:策略参数,这里指定副本所在节点名称从RabbitMQ 3.8版本开始,引入了新的仲裁队列,他具备与镜像队里类似的功能,但使用更加方便。
仲裁队列:仲裁队列是3.8版本以后才有的新功能,用来替代镜像队列,具备下列特征:
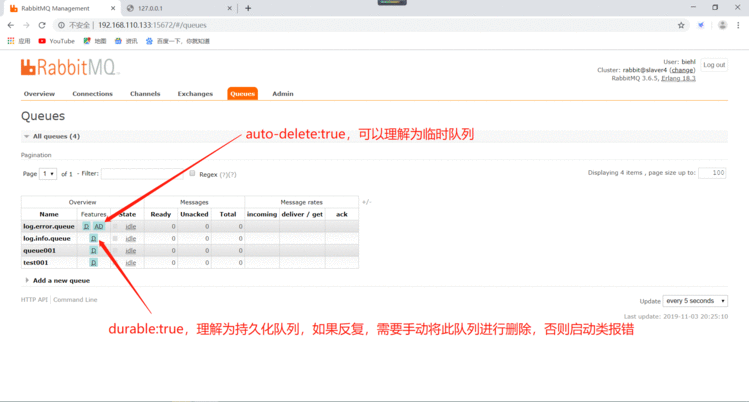
在任意控制台添加一个队列,一定要选择队列类型为Quorum类型。
在任意控制台查看队列:
可以看到,仲裁队列的 + 2字样。代表这个队列有2个镜像节点。
因为仲裁队列默认的镜像数为5。如果你的集群有7个节点,那么镜像数肯定是5;而我们集群只有3个节点,因此镜像数量就是3.
@Bean
public Queue quorumQueue() {
return QueueBuilder
.durable("quorum.queue") // 持久化
.quorum() // 仲裁队列
.build();
}
注意,这里用address来代替host、port方式
spring:
rabbitmq:
addresses: 192.168.150.105:8071, 192.168.150.105:8072, 192.168.150.105:8073
username: itcast
password: 123321
virtual-host: /






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有