在日益复杂的前端应用中,状态管理是一个经常被提及的话题,从早期的刀耕火种时代到jQuery,再到现在流行的MVVM时代,状态管理的形式发生了翻天覆地的变化,我们再也不用维护茫茫多的事件回调、监听来更新视图,转而使用双向数据绑定,只需要维护相应的数据状态,就可以自动更新视图,极大提高开发效率。
但是,双向数据绑定也并不是唯一的办法,还有一个非常粗暴有效的方式:一旦数据发生变化,重新绘制整个视图,也就是重新设置一下innerHTML。这样的做法确实简单、粗暴、有效,但是如果只是因为局部一个小的数据发生变化而更新整个视图,性价比未免太低了,而且,像事件,获取焦点的输入框等,都需要重新处理。所以,对于小的应用或者说局部的小视图,这样处理完全是可以的,但是面对复杂的大型应用,这样的做法不可取。
为了解决在大量、频繁的数据更新下,视图能够进行合理、高效的更新,Vue 在 2.0版本 引入了virtual DOM。Virtual DOM 在牺牲部分性能的前提下,增加了可维护性,实现了对DOM的集中化操作,在数据改变时先对虚拟DOM进行修改,再反映到真实的DOM中,用最小的代价来更新DOM,提高效率;除此之外,Virtual DOM还可以在DOM以外的端上进行渲染,比如Weex。
diff算法的目的是为了找到哪些节点发生了变化,哪些节点没有发生变化可以复用。如果用最传统的diff算法,如下图所示,每个节点都要遍历另一棵树上的所有节点做比较,这就是o(n^2)的复杂度,加上更新节点时的o(n)复杂度,那就总共达到了o(n^3)的复杂度,这对于一个结构复杂节点数众多的页面,成本是非常大的。

实际上vue和react都对虚拟dom的diff算法做了一定的优化,将复杂度降低到了o(n)级别,具体的策略是:
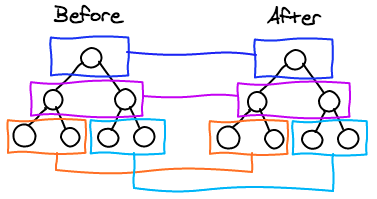
从根节点起遍历整个节点数,只对同层的节点进行相互比较。所以我们在代码开发中,如果节点内容没有发生变化,那不要轻易改变它的层级,否则会导致节点无法复用。
接下来我们就介绍一下vue里面的具体代码实现
整体流程图
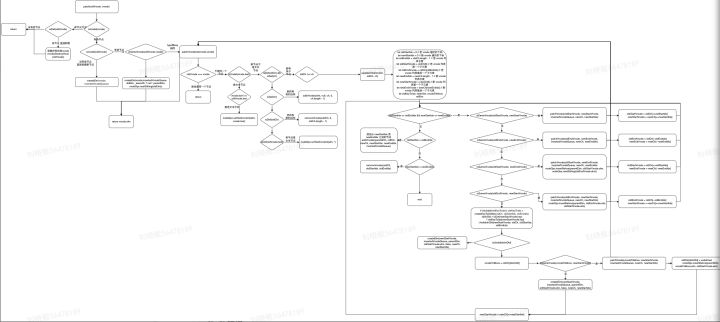
先判断是否是首次渲染,如果是首次渲染那么我们就直接createElm即可;如果不是就去判断新老两个节点的元素类型否一样;如果两个节点都是一样的,那么就深入检查他们的子节点。如果两个节点不一样那就说明Vnode完全被改变了,就可以直接替换oldVnode。
function patch(oldVnode, vnode, hydrating, removeOnly) {// 判断新的vnode是否为空if (isUndef(vnode)) {// 如果老的vnode不为空 卸载所有的老vnodeif (isDef(oldVnode)) invokeDestroyHook(oldVnode)return}let isInitialPatch = false// 用来存储 insert钩子函数,在插入节点之前调用const insertedVnodeQueue = []// 如果老节点不存在,直接创建新节点if (isUndef(oldVnode)) {isInitialPatch = truecreateElm(vnode, insertedVnodeQueue)} else {// 是不是元素节点const isRealElement = isDef(oldVnode.nodeType)// 当老节点不是真实的DOM节点,并且新老节点的type和key相同,进行patchVnode更新工作if (!isRealElement && sameVnode(oldVnode, vnode)) {patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)} else {// 如果不是同一元素节点的话// 当老节点是真实DOM节点的时候if (isRealElement) {// 如果是元素节点 并且在SSR环境的时候 修改SSR_ATTR属性if (oldVnode.nodeType === 1 && oldVnode.hasAttribute(SSR_ATTR)) {// 就是服务端渲染的,删掉这个属性oldVnode.removeAttribute(SSR_ATTR)hydrating = true}// 这个判断里是服务端渲染的处理逻辑if (isTrue(hydrating)) {if (hydrate(oldVnode, vnode, insertedVnodeQueue)) {invokeInsertHook(vnode, insertedVnodeQueue, true)return oldVnode}}// 如果不是服务端渲染的,或者混合失败,就创建一个空的注释节点替换 oldVnodeoldVnode = emptyNodeAt(oldVnode)}// 拿到 oldVnode 的父节点const oldElm = oldVnode.elmconst parentElm = nodeOps.parentNode(oldElm)// 根据新的 vnode 创建一个 DOM 节点,挂载到父节点上createElm(vnode,insertedVnodeQueue,oldElm._leaveCb ? null : parentElm,nodeOps.nextSibling(oldElm))// 如果新的 vnode 的根节点存在,就是说根节点被修改了,就需要遍历更新父节点// 递归 更新父占位符元素// 就是执行一遍 父节点的 destory 和 create 、insert 的 钩子函数if (isDef(vnode.parent)) {let ancestor = vnode.parentconst patchable = isPatchable(vnode)// 更新父组件的占位元素while (ancestor) {// 卸载老根节点下的全部组件for (let i = 0; i
function patchVnode(oldVnode, // 老的虚拟 DOM 节点vnode, // 新节点insertedVnodeQueue, // 插入节点队列ownerArray, // 节点数组index, // 当前节点的下标removeOnly) {// 新老节点对比地址一样,直接跳过if (oldVnode === vnode) {return}if (isDef(vnode.elm) && isDef(ownerArray)) {// clone reused vnodevnode = ownerArray[index] = cloneVNode(vnode)}const elm = vnode.elm = oldVnode.elm// 如果当前节点是注释或 v-if 的,或者是异步函数,就跳过检查异步组件if (isTrue(oldVnode.isAsyncPlaceholder)) {if (isDef(vnode.asyncFactory.resolved)) {hydrate(oldVnode.elm, vnode, insertedVnodeQueue)} else {vnode.isAsyncPlaceholder = true}return}// 当前节点是静态节点的时候,key 也一样,或者有 v-once 的时候,就直接赋值返回if (isTrue(vnode.isStatic) &&isTrue(oldVnode.isStatic) &&vnode.key === oldVnode.key &&(isTrue(vnode.isCloned) || isTrue(vnode.isOnce))) {vnode.compOnentInstance= oldVnode.componentInstancereturn}let iconst data = vnode.dataif (isDef(data) && isDef(i = data.hook) && isDef(i = i.prepatch)) {i(oldVnode, vnode)}const oldCh = oldVnode.childrenconst ch = vnode.childrenif (isDef(data) && isPatchable(vnode)) {// 遍历调用 update 更新 oldVnode 所有属性,比如 class,style,attrs,domProps,events...// 这里的 update 钩子函数是 vnode 本身的钩子函数for (i = 0; i
这里是diff算法的具体实现细节,流程包括:
最后如果老节点的头部指针大于老节点的尾部指针,说明新节点多,直接创建剩余新节点插入到DOM中;反之如果新节点的头部指针大于新节点的尾部指针,说明老节点数量多,删除剩余老节点即可。
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue) {let oldStartIdx = 0 // 老 vnode 遍历的下标let newStartIdx = 0 // 新 vnode 遍历的下标let oldEndIdx = oldCh.length - 1 // 老 vnode 列表长度let oldStartVnode = oldCh[0] // 老 vnode 列表第一个子元素let oldEndVnode = oldCh[oldEndIdx] // 老 vnode 列表最后一个子元素let newEndIdx = newCh.length - 1 // 新 vnode 列表长度let newStartVnode = newCh[0] // 新 vnode 列表第一个子元素let newEndVnode = newCh[newEndIdx] // 新 vnode 列表最后一个子元素let oldKeyToIdx, idxInOld, vnodeToMove, refElm// 循环,规则是开始指针向右移动,结束指针向左移动移动// 当开始和结束的指针重合的时候就结束循环while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {if (isUndef(oldStartVnode)) {oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left} else if (isUndef(oldEndVnode)) {oldEndVnode = oldCh[--oldEndIdx]// 老开始和新开始对比} else if (sameVnode(oldStartVnode, newStartVnode)) {// 是同一节点 递归调用 继续对比这两个节点的内容和子节点patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)// 然后把指针后移一位,从前往后依次对比// 比如第一次对比两个列表的[0],然后比[1]...,后面同理oldStartVnode = oldCh[++oldStartIdx]newStartVnode = newCh[++newStartIdx]// 老结束和新结束对比} else if (sameVnode(oldEndVnode, newEndVnode)) {patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)// 然后把指针前移一位,从后往前比oldEndVnode = oldCh[--oldEndIdx]newEndVnode = newCh[--newEndIdx]// 老开始和新结束对比} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved rightpatchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))// 老的列表从前往后取值,新的列表从后往前取值,然后对比oldStartVnode = oldCh[++oldStartIdx]newEndVnode = newCh[--newEndIdx]// 老结束和新开始对比} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved leftpatchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)// 老的列表从后往前取值,新的列表从前往后取值,然后对比oldEndVnode = oldCh[--oldEndIdx]newStartVnode = newCh[++newStartIdx]// 以上四种情况都没有命中的情况} else {if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)// 拿到新开始的 key,在老的 children 里去找有没有某个节点有这个 keyidxInOld = isDef(newStartVnode.key)? oldKeyToIdx[newStartVnode.key]: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)// 新的 children 里有,可是没有在老的 children 里找到对应的元素if (isUndef(idxInOld)) {/// 就创建新的元素createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)} else {// 在老的 children 里找到了对应的元素vnodeToMove = oldCh[idxInOld]// 判断标签如果是一样的if (sameVnode(vnodeToMove, newStartVnode)) {// 就把两个相同的节点做一个更新patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)oldCh[idxInOld] = undefinednodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)} else {// 如果标签是不一样的,就创建新的元素createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)}}newStartVnode = newCh[++newStartIdx]}}// oldStartIdx > oldEndIdx 说明老的 vnode 先遍历完if (oldStartIdx > oldEndIdx) {// 就添加从 newStartIdx 到 newEndIdx 之间的节点refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elmaddVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)// 否则就说明新的 vnode 先遍历完} else if (newStartIdx > newEndIdx) {// 就删除掉老的 vnode 里没有遍历的节点removeVnodes(oldCh, oldStartIdx, oldEndIdx)}}function isUndef (v) { return v === undefined || v === null }
第一步:比较新老children的length获取最小值,然后对于公共部分,进行重新patch工作;
第二步:判断新老节点的数量。如果老节点的数量大于新节点的数量,则直接‘unmountChildren’从公共部分之后的所有老节点;如果新节点的数量大于老节点的数量,那就直接‘mountChildren’公共部分之后的所有新节点。
const patchUnKeyedChildren = (n1,n2,container,anchor) => {const oldLen = n1.length;const newLen = n2.length;const commOnLen= Math.min(oldLen, newLen);for(let i = 0;i
}
c1: a b [ c d e ] f g
c2: a b [ d e c h ] f g
假如有如上的 c1 和 c2 新旧 children,在 diff 的时候,会有一个预处理的过程。
先从前往后比较,当节点不同时,不再往后进行比较。接着又从后往前进行比较,当节点不同时,不再往前进行比较。
经过预处理之后,c1 和 c2 真正需要进行 diff 的部分如下所示:
c1: c d e
c2: d e c h
最后利用“最长递增子序列”,完成上述差异部分的比较,提高diff效率
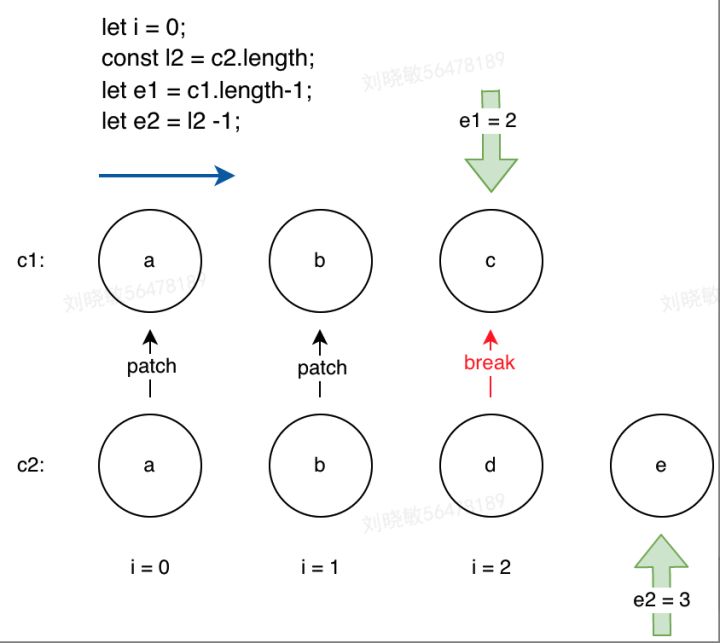
先定义三个变量 i = 0(代表比对从下表为0的节点开始);e1 = c1.length -1(代表旧节点序列的最后一个节点下表);e12= c2.length -1(代表新节点序列的最后一个节点下表)。
在while循环中,通过新老节点序列的头部节点开始比对,节点相同就进行patch工作;遇到不同的节点就退出当前的循环。
const isSameVNodeType = (n1:VNode, n2:VNode) => n1.type === n2.type && n1.key === n2.key;
// 1. sync from start
while(i<=e1 && i<=e2){let n1 = c1[i];let n2 = c2[i];if(isSameVNodeType(n1, n2)){patch(n1,n2,container);}else{break;}i++
}
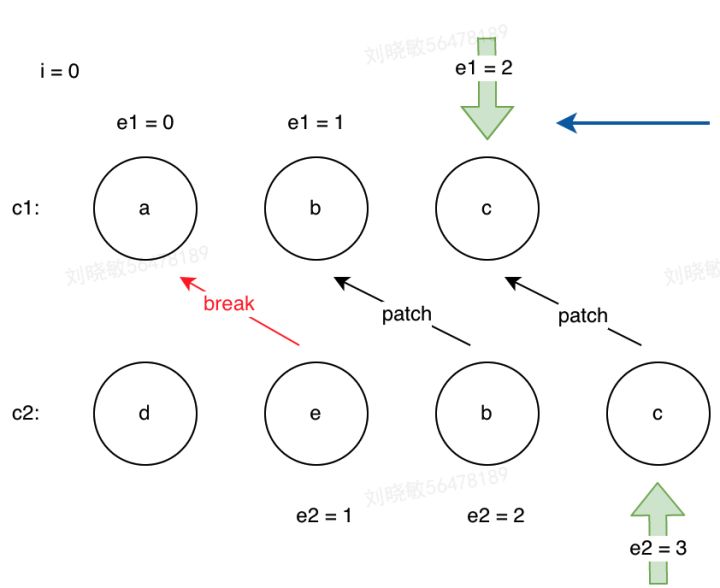
同上,我们在while循环中,从新老节点序列的尾部节点开始对比,一样就进行patch工作;遇到不同的节点就退出当前的循环。
// 2. sync from end
while(i<=e1 && i<=e2){let n1 = c1[el];let n2 = c2[e2];if(isSameVNodeType(n1, n2)){patch(n1,n2,container);}else{break;}e1--;e2--;
}
通过以上两个循环后,发现新的节点序列比老的节点序列多;遇到这种情况,我们就直接循环把多余的新增节点全部挂载到相应的位置即可。需要注意是向前挂载,还是向后挂在。这里我们是用当前e2的值加1去判断,如果e2+1>e2,那么就向后插入,反之则向前插入
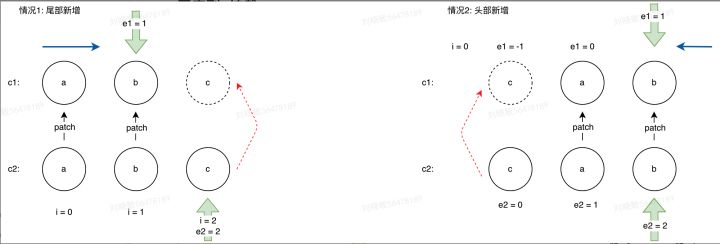
// 3. common sequence + mount
if(i>e1){if(i<= e2){const nextPos = e2 + 1;const anchor = nextPos
同上,当两个循环结束/终止后,发现老的节点序列比新的节点序列多;那么我们直接循环卸载多余的旧序列节点即可

// 4. common sequence + unmount
if(i>e2){while(i <= e1){unmount(c1[i]);i++;}
}
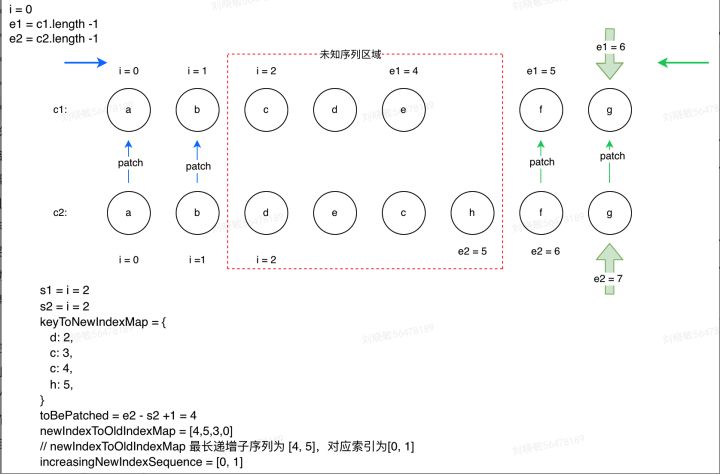
有时候,情况可能没有上述那么地简单,即 i、e1、e2 并不满足上述几种情形时,我们就要寻找其中需要被移除、新增的节点,又或是判断哪些节点需要进行移动。
为此,我们需要去遍历 c1 中未进行处理的节点,然后查看在 c2 中是否有对应的节点(key 相同)。没有,则说明该节点已经被移除,那就执行 unmount 操作。
首先,为了快速确认 c1 的节点在 c2 中是否有对应的节点及所在的位置,对 c2 中的节点建立一个映射表(key: index);
然后,基于 c2 中待处理的节点数目(toBePatched)创建一个变量newIndexToOldIndexMap(Map
然后,遍历 c1 中待处理的节点;先判断patched 是否大于c2 中待处理的节点数目toBePatched,当patched>toBePatched时,可以认为剩余c1 中的节点都是多余的了,直接移除就好。然后判断剩余c1、c2 中是否有相同 key 的节点存在;
最后根据最长递增子序列算法求得最长递增子序列后,遍历 c2 中的待处理节点,判断节点是否属于新增,是否需要进行移动。
// 5. unknown sequence
const s1 = i // prev starting index
const s2 = i // next starting index
// 5.1 build key:index map for newChildren
const keyToNewIndexMap: Map
for (i = s2; i <= e2; i++) {const nextChild = c2if (nextChild.key != null) {keyToNewIndexMap.set(nextChild.key, i)}
}
// 5.2 loop through old children left to be patched and try to patch
// matching nodes & remove nodes that are no longer present
let j
let patched = 0
const toBePatched = e2 - s2 + 1 // c2 中待处理的节点数目
let moved = false
// used to track whether any node has moved
let maxNewIndexSoFar = 0 // 已遍历的待处理的 c1 节点在 c2 中对应的索引最大值// works as Map
// Note that oldIndex is offset by +1
// and oldIndex = 0 is a special value indicating the new node has
// no corresponding old node.
// used for determining longest stable subsequence
const newIndexToOldIndexMap = new Array(toBePatched) // 用于后面求最长递增子序列
for (i = 0; i
}// 5.3 move and mount
// generate longest stable subsequence only when nodes have moved
const increasingNewIndexSequence = moved? getSequence(newIndexToOldIndexMap): EMPTY_ARR
j = increasingNewIndexSequence.length - 1
// looping backwards so that we can use last patched node as anchor
for (i = toBePatched - 1; i >= 0; i--) {const nextIndex = s2 + iconst nextChild = c2[nextIndex] as VNodeconst anchor =nextIndex + 1
当 Vue 正在更新使用 v-for 渲染的元素列表时,它默认使用“就地更新”的策略。如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序,而是就地更新每个元素,并且确保它们在每个索引位置正确渲染。这个类似 Vue 1.x 的 track-by="$index"。虽然这个默认的模式是高效的,但是只适用于不依赖子组件状态或临时 DOM 状态 (例如:表单输入值) 的列表渲染输出。
为了给 Vue 一个提示,方便它能跟踪每个节点,从而达到重用或重新排序现有元素的目的,我们需要在v-for渲染元素列表的时候为每项提供一个唯一标识 key attribute。
使用场景:
// 当 text 发生改变时, 总是会被替换而不是被修改,因此会触发过渡。
错误的用法:
正确用法:
参考资料:
https://stackoverflow.com/questions/44238139/why-is-vue-js-using-a-vdom
Announcing Vue.js 2.0 - 知乎
https://cn.vuejs.org/v2/guide/list.html
https://github.com/vuejs/vue-next/blob/master/packages/runtime-core/src/renderer.ts
本文来自内部分享!








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有