编者按:高可用架构分享及传播在架构领域具有典型意义的文章,本文由姚四芳在高可用架构群分享。转载请注明来自高可用架构公众号「 ArchNotes 」。
姚四芳,新浪微博高级技术专家,微博平台架构组技术负责人。2012 年加入新浪微博,参与微博 Feed 架构升级,平台服务化改造,混合云等多个重点项目,现任微博平台架构组技术负责人,负责平台公共基础组建的研发工作。曾在 QCon 进行《新浪微博高性能架构》技术分享,专注高性能架构及服务中间件方向。
Nginx 使用的业务背景与问题
 Nginx 以其超高的性能与稳定性,在业界获得了广泛的使用,微博的七层就大量使用了 Nginx 。结合 Nginx 的健康检查模块,以及动态 reload 机制,可以近乎无损的服务的升级上线与扩容。这个时候扩容的频次比较低,大多数情况下是有计划的扩容。
Nginx 以其超高的性能与稳定性,在业界获得了广泛的使用,微博的七层就大量使用了 Nginx 。结合 Nginx 的健康检查模块,以及动态 reload 机制,可以近乎无损的服务的升级上线与扩容。这个时候扩容的频次比较低,大多数情况下是有计划的扩容。
微博的业务场景有非常显著的峰值特征。既有例行的晚高峰,也有像元旦、春晚、红包飞这样的预期内的极端流量峰值。更有#周一见# #我们#等明星/社会事件引发的偶发峰值。之前通常的做法就是 buffer + 降级。在不考虑降级时(会影响用户体验)buffer 小了无法承担峰值大了则成本无法承受。因此,从 2014 年开始,就在尝试利用容器化来实现 buffer 的动态调整,从而实现依据流量对 buffer 按需扩/缩容,以节省成本开销。
在这种场景下,会有持续的大量的扩/缩容操作。业界基于 Nginx 的 backend 变更有两种常用的解决方案。一种是 Tengine 提供的基于 DNS 的,一种是基于 consul-template 的 backend 服务发现。下面的表格简单对比了两种方案的特点。
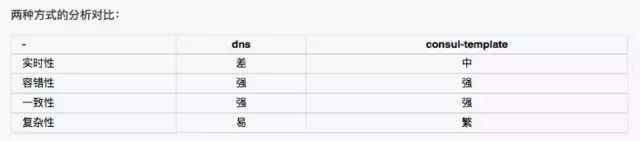
基于 DNS : 该模块由 Tengine 团队开发,可以动态的解析 upstream conf 下的域名。这种方式操作简单,只要修改 dns 下挂载的 server 列表便可。
缺点 :
基于 consul-template 与 consul : 作为一个组合,consul 作为 db,consul-template 部署于 Nginx server 上,consul-template 定时向 consul 发起请求,发现 value 值有变化,便会更新本地的 Nginx 相关配置文件,发起 reload 命令。但是在流量比较重的情况下,发起 reload 会对性能造成影响。reload 的同时会引发新的 work 进程的创建,在一段时间内新旧 work 进程会同时存在,并且旧的 work 进程会频繁的遍历 connection 链表,查看是否请求已经处理结束,若结束便退出进程;另 reload 也会造成 Nginx 与 client 和 backend 的长链接关闭,新的 work 进程需要创建新的链接。
reload 造成的性能影响 :

reload 时 Nginx 的请求处理能力会下降( 注:Nginx 对于握手成功的请求不会丢失 )
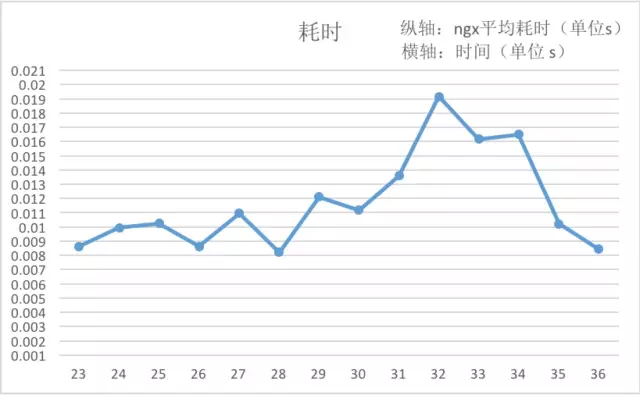
reload 时耗时会发生波动,波动幅度甚至达 50%+ ( 不同的业务耗时,波动幅度会有差异 )
每一次的 reload 对 Nginx 的 QPS 与耗时的影响通常会持续 8~10s,考虑到一次扩容会有频繁的变更,这对在线业务来说,是不堪承受之重。因此,要避免对 Nginx 进行 reload。
基于动态路由的方案设计
在 Nginx 的设计中,每一个 upstream 维护了一张静态路由表,存储了 backend 的 ip、port 以及其他的 meta 信息。每次请求到达后,会依据 location 检索路由表,然后依据具体的调度算法(如 round robin )选择一个 backend 转发请求。但这张路由表是静态的,如果变更后,则必须 reload,通过上图就可以发现 SLA 受到较大影响。
最直观的想法就是,每次更新后 backend 后,动态更新/创建一张路由表,从而避免 reaload。通过 Nginx 扩展一个模块 [ nginx-upsync-module ] ( https://github.com/weibocom/nginx-upsync-module ) 来动态更新维护路由表。通常路由表的维护的 push 与 pull 两种方式。
push 方案
此方案中 Nginx 提供 http api 接口,通过 api 添加/删除 server 时,通过调用 api 向 Nginx 发出请求,操作简单、便利。
架构图如下:
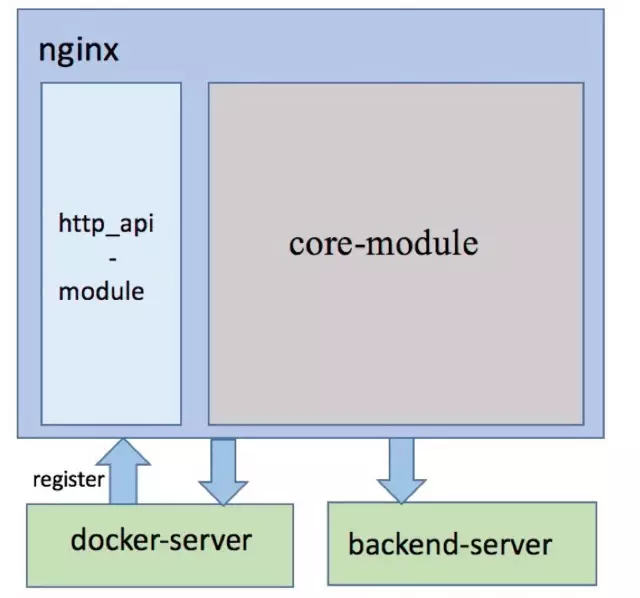
http api 除了操作简单、方便,而且实时性好;缺点是有多台 Nginx 时,不同 Nginx 路由表的一致性难于保证,如果某一条注册失败,便会造成服务配置的不一致,容错复杂。另外扩容 Nginx 服务器,需要从其他的 Nginx 中同步路由表。
pull 方案
考虑到 push 方案中路由表维度中存在的一致性待问题,引入了第三方组件 consul 解决这一问题。
架构图如下:
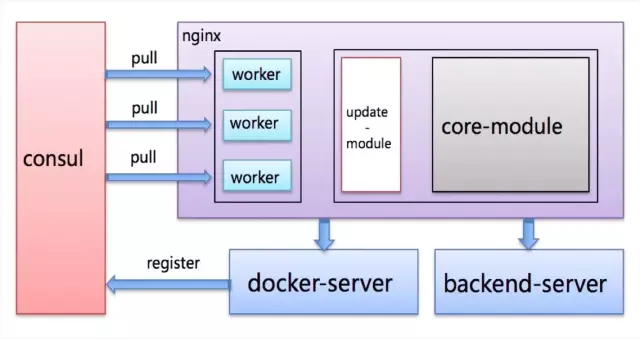
路由表中所有的 backend 信息( 含 meta )存储到 consul ,所有的 Nginx 从 consul 拉取相关信息,有变更则更新路由表,利用 consul 解决一致性问题,同时利用 consul 的 wait 机制解决实时性问题,利用 consul 的 index ( 版本号 ) 进行增量摘取,解决带宽占用问题。
在 consul 中,一个 k/v 对代表一个 backend 信息,增加一个即视作扩容,减少一个即为缩容。调整 meta 信息,如权重,也可以达到动态流量调整的目的。
下面的实现基于 consul 进行介绍。
基于动态路由的方案实现
基于 upsync 方式,开发了模块 nginx-upsync-module,它的功能是拉取 consul 的后端 server 的列表,并更新 Nginx 的路由信息。此模块不依赖于任何第三方模块。
路由表更新方式
consul 作为 Nginx 的 db,利用 consul 的 KV 服务,每个 Nginx work 进程独立的去拉取各个 upstream 的配置,并更新各自的路由。
流程图如下:

每个 work 进程定时的去 consul 拉取相应 upstream 的配置,定时的间隔可配;其中 consul 提供了 time_wait 机制,利用 value 的版本号,若 consul 发现对应 upstream 的值没有变化,便会 hang 住这个请求 5 分钟(默认),在这五分钟内对此 upstream 的任何操作,都会立刻返回给 Nginx,对相应路由进行更新。对于拉取的间隔可以结合场景的需要进行配置,基本可以实现所要求的实时性。upstream 变更后,除了更新 Nginx 的缓存路由信息,还会把本 upstream 的后端 server 列表 dump 到本地,保持本地 server 信息与 consul 的一致性。
除了注册/注销后端的 server 到 consul,会更新到 Nginx 的 upstream 路由信息外,对后端 server 属性的修改也会同步到nginx的upstream路由。当前本模块支持修改的属性有 weight、max_fails、fail_timeout、down,修改 server 的权重可以动态的调整后端的流量,若想要临时移除server,可以把 server 的 down 属性置为 1( 当前 down 的属性暂不支持 dump 到本地的 server 列表内 ),流量便会停止打到该 server,若要恢复流量,可重新把 down 置为 0。
另外每个 work 进程各自拉取、更新各自的路由表,采用这种方式的原因:一是基于 Nginx 的进程模型,彼此间数据独立、互不干扰;二是若采用共享内存,需要提前预分配,灵活性可能受限制,而且还需要读写锁,对性能可能存在潜在的影响;三是若采用共享内存,进程间协调去拉取配置,会增加它的复杂性,拉取的稳定性也会受到影响。基于这些原因,便采用了各自拉取的方式。
高可用性
Nginx 的后端列表更新依赖于 consul,但是不强依赖于它,表现在:一是即使中途consul意外挂了,也不会影响 Nginx 的服务,Nginx 会沿用最后一次更新的服务列表继续提供服务;二是若 consul 重新启动提供服务,这个时候 Nginx 会继续去 consul 探测,这个时候 consul 的后端服务列表发生了变化,也会及时的更新到 Nginx。
另一方面,work 进程每次更新都会把后端列表 dump 到本地,目的是降低对 consul 的依赖性,即使在 consul 不可用之时,也可以 reload Nginx。Nginx 启动流程图如下:
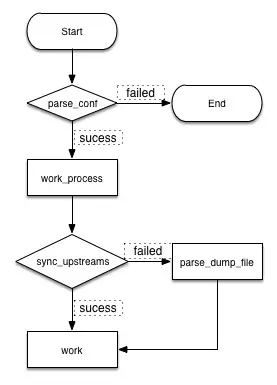
Nginx 启动时,master 进程首先会解析本地的配置文件,解析完成功,接着进行一系列的初始化,之后便会开始 work 进程的初始化。work 初始化时会去 consul 拉取配置,进行 work 进程 upstream 路由信息的更新,若拉取成功,便直接更新,若拉取失败,便会打开配置的 dump 后端列表的文件,提取之前 dump 下来的 server 信息,进行 upstream 路由的更新,之后便开始正常的提供服务。
每次去拉取 consul 都会设置连接超时,由于 consul 在无更新的情况下默认会 hang 五分钟,所以响应超时配置时间应大于五分钟。大于五分钟之后,consul 依旧没有返回,便直接做超时处理。
兼容性
整体上讲本模块只是更新后端的 upstream 路由信息,不嵌入其它模块,同时也不影响其它模块的功能,亦不会影响 Nginx-1.9.9 的几种负载均衡算法:least_conn、hash_ip 等。
除此之外,模块天然支持健康监测模块,若 Nginx 编译时包含了监测模块,会同时调用健康监测模块的接口,时时更新健康监测模块的路由表。
性能测试
nginx-upsync-module 模块,潜在的带来额外的性能开销,比如间隔性的向 consul 发送请求,由于间隔比较久,且每个请求相当于 Nginx 的一个客户端请求,所以影响有限。基于此,在相同的硬件环境下,使用此模块和不使用此模块简单做了性能对比。
基本环境
硬件环境:Intel(R) Xeon(R) CPU E5645 @ 2.40GHz 12 核
系统环境:centos6.5;
work进程数:8个;
压测工具:wrk;
压测命令:./wrk -t8 -c100 -d5m --timeout 3s http://$ip:8888/proxy_test
压测数据 :

其中 Nginx ( official ) 是官方 Nginx,不执行 reload 下的测试数据。Nginx ( upsync ) 是基于 upsync 模块,每隔 10s 钟向 consul 注册/注销一台机器的数据;从数据可以看出,通过 upsync 模块做扩缩容操作,对性能的影响有限,可以忽略不计。
应用案例
模块已经应用在微博的各类业务中,下面图表对比分析使用模块前后的 QPS 与耗时变化。
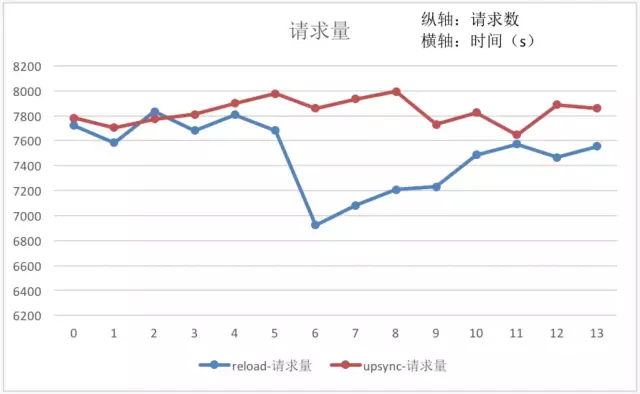
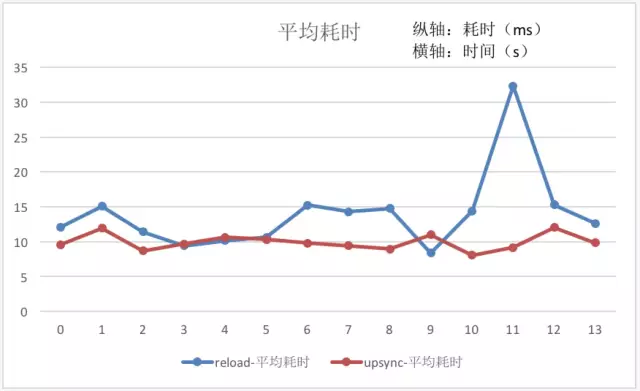
从数据可以得出,reload 操作时造成 nginx 的请求处理能力下降约 10%,Nginx 本身的耗时会增长 50%+。若是频繁的扩容缩容,reload 操作造成的开销会更加明显。
在 2016 年元旦期间,针对不同时间段流量特点,进行了上百次的扩/缩容,整体服务在扩容过程中的 SLA 未受影响。
官方商业版对 Nginx plus 支持了 DNS 与 push 版本提供了支持。
在使用过程中因为数据一致性等问题,扩展支持了基于 consul 的 pull 版本
https://github.com/weibocom/nginx-upsync-module 目前在完善 wiki 与文档 点击阅读原文可以进入。
Q & A
1、consul 中的机器配置信息注册是微博系统根据流量自动调整吗 ?
这是两个问题,在扩容时向节点注册 backend 信息的过程是自动的,已经整合到上线系统中。另外,目前微博在进行在线容量评估系统开发与评测,目前是处理半自动调整。
2、请问下当初为何不考虑 zk 呢? 如果换做 zk 不用轮训 pull 改为长连会有什么不一样吗?
目前模块已经在添加类似 etcd、zk 类的支持。当初使用 consul 是因为公司内已经有 consul 集群与运维人员。zk 与 etcd、consul 对于模块而言在本质上是一样的
3、为什么不要 Nginx 的 master 去 pull ,然后分发给各个 work ,而用 work 进程 pull ?前者可以减少网络交互和提升一个 Nginx 内部多 work 的一致性
如果使用 master 去 pull,需要修改 core 模块,在进行模块设计时,一个大的原则就是想尽量确保模块的 0 依赖。总的来说,这也是一个 trade off。
4、consul 中的机器配置信息注册是微博系统根据流量自动调整吗 ?
这个问题与问题 1 类似。
5、基于什么考虑选用了 consul 做配置管理?
与问题 2 类似。
6、能否设计一套 API,给 Nginx 去 pull ,源是 consul 还是某个 Java 服务都没关系,感觉更通用些
模块的设计思路与提到的类似,里面设计了一个 upsync type,不同的源进行不同的 type 实现即可。
7、另外不知道有没有解决过 Nginx 路由信息太多占用内存过多的问题,我们现在用 LRU 的方式淘汰,不知道微博有没有这样的场景
在设计的时候考虑过这一块。通常我们只会保持当前路由表与一个过期路由表,在过期路由表支撑的所有请求处理完成后,这一部分内存会被释放掉。
8、在流量低谷的时候,微博未使用的机器用来做什么呢?如果这批机器还在给别的服务使用,当微博动态加载这批机器,那其它服务怎么办
目前我们在进行混合云部署,buffer 池子在公有云上创建。流量低谷的时候,直接删除即可。自有机房的机器在流量低谷时,通常可以跑一些离线业务,在线与离线混跑的策略目前在开发中。
9、ab 和 work 的实际测试结果表明 在高压力下频繁更新 consul 列表会出现failed的情况 这个问题你们是怎么处理的?
我们有测试每秒钟变更上千台机器,并不会出现问题。这个已经能够支撑绝大部分(包括大鳄们)的扩容诉求。我们在压测 consul 的时候,的确出现 consul 的 failed 情况(单主提供服务),这个和模块本身并无关联。需要提升 consul 集群的性能与配置。
10、请教老师,想对 consul 做个简单了解,consul 是在内存中存储的路由信息吗?如何区分不同服务的路由信息?只能通过键值命名还是每个服务分别部署 consul ?
路由表信息会存储到 3 个地方。1. Nginx 的内存,直接提升路由服务;2. 存储在 consul 上,存储每一个节点就是一个 backend key 为 /$consul_path/$upstream/ip:port。 3. Nginx 所在服务器的文件上,以 snapshot 的方式存储,避免 consulg 与 Nginx 同时宕机。






 京公网安备 11010802041100号
京公网安备 11010802041100号