考虑到在大多数情况下
这里的参数
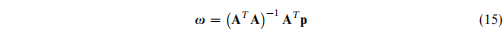
通过常数约束进行估计

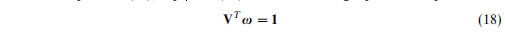

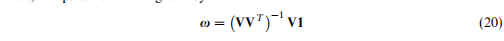
通过语意一致性进行估计
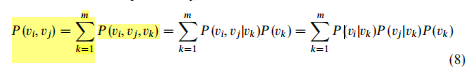

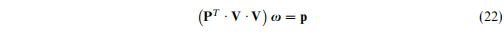


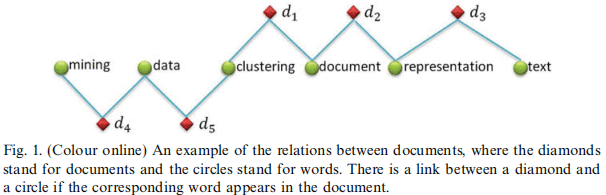
本文提出了三个参数估计的方式,使用这三个方式之前都需要我们首先构建上下文矩阵
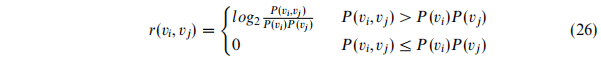


正如公式5那样,上面方法计算的词之间的显式关系被符号化为条件概率:
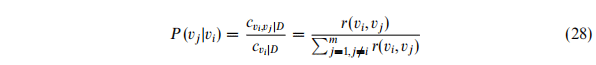
此处,当i = j时,记$p(v_j|v_i) = 1
通常,我们假设一个词的出现频率足够产生可靠的边缘概率,为了使边缘概率的计算更加可信,我们引入了一个阈值变量TH,它用来判断一个词的出现评率是否充足。不是一般性,这里假设预料库V中各个词出现的评率逆序排列,则这里的边缘概率采用下面的公式计算:
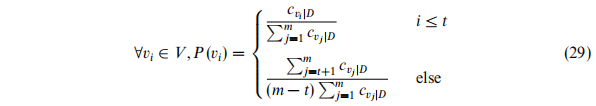
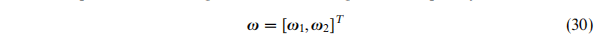
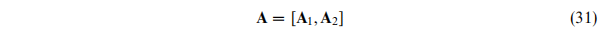
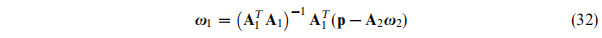

文档聚类
1、扩充BOW是必要的;
2、考虑词之间的隐式相关关系是必要的;
3、词的边缘分布隐藏着一些固有的语义信息;
4、三种参数估计方法中,基于边缘概率的方法表现最好,基于语意的方法次之,基于常数的方法最差;
5、专家库的知识覆盖面可能会影响以知识库为基础的方法;
6、本文提出的方法优于主题模型。
语意相似性估计
1、词的多义性、同义性、语意转化现象都增加了基于统计学的方法检测人名、技术术语相似性的难度;
2、词之间的相关性更能表达语法相关性而非语意相似性。
NNMs在非监督学习问题中(NLP)用得很少,在本文的实验中,NNM在两个任务中都没有足够好的表现,这里将表现不好的原因归结为以下几个方面:
对于非监督任务,NNMs给的信息量过大:NNM在文档特征向量中嵌入的不仅仅是语意形式,还有很多语法信息,这些不必要的信息可以通过监督训练过滤掉,但是这也许会影响非监督方法的计算过程。此外,非监督的关键是采用尽可能少的信息训练百万级的参数,从这方面讲,TPMF和TPMS获取的词之间的共现频率、词的出现频率就可以成为新的约束,把它们加入NNMs中有提高NNMs表现的可能。
本文实验结果表明,统计学方法和基于专家知识的方法在文档聚类和语意相似度估计中各有长短,所以集成以专家知识为基础的方法和本文提出的方法来强化词语关系估计效果,进而缓解知识覆盖面有限的问题是很有价值的。
在用基于知识的方法来推测隐式关系之前,一词多义问题也需要控制。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有