作者:用途回家 | 来源:互联网 | 2021-11-05 10:52
这篇文章主要介绍了Ubuntu安装和卸载CUDA和CUDNN的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
前言
最近在学习PaddlePaddle在各个显卡驱动版本的安装和使用,所以同时也学习如何在Ubuntu安装和卸载CUDA和CUDNN,在学习过程中,顺便记录学习过程。在供大家学习的同时,也在加强自己的记忆。本文章以卸载CUDA 8.0 和 CUDNN 7.05 为例,以安装CUDA 10.0 和 CUDNN 7.4.2 为例。
安装显卡驱动
禁用nouveau驱动
sudo vim /etc/modprobe.d/blacklist.conf
在文本最后添加:
blacklist nouveau
options nouveau modeset=0
然后执行:
重启后,执行以下命令,如果没有屏幕输出,说明禁用nouveau成功:
下载驱动
官网下载地址:https://www.nvidia.cn/Download/index.aspx?lang=cn ,根据自己显卡的情况下载对应版本的显卡驱动,比如笔者的显卡是RTX2070:
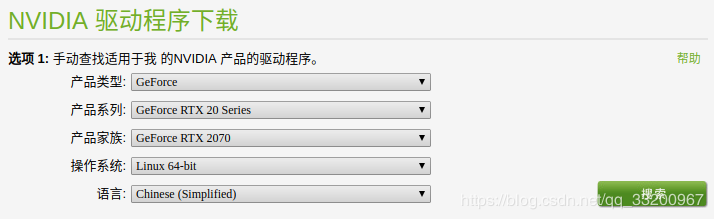
下载完成之后会得到一个安装包,不同版本文件名可能不一样:
NVIDIA-Linux-x86_64-410.93.run
卸载旧驱动
以下操作都需要在命令界面操作,执行以下快捷键进入命令界面,并登录:
执行以下命令禁用X-Window服务,否则无法安装显卡驱动:
sudo service lightdm stop
执行以下三条命令卸载原有显卡驱动:
sudo apt-get remove --purge nvidia*
sudo chmod +x NVIDIA-Linux-x86_64-410.93.run
sudo ./NVIDIA-Linux-x86_64-410.93.run --uninstall
安装新驱动
直接执行驱动文件即可安装新驱动,一直默认即可:
sudo ./NVIDIA-Linux-x86_64-410.93.run
执行以下命令启动X-Window服务
sudo service lightdm start
最后执行重启命令,重启系统即可:
注意: 如果系统重启之后出现重复登录的情况,多数情况下都是安装了错误版本的显卡驱动。需要下载对应本身机器安装的显卡版本。
卸载CUDA
为什么一开始我就要卸载CUDA呢,这是因为笔者是换了显卡RTX2070,原本就安装了CUDA 8.0 和 CUDNN 7.0.5不能够正常使用,笔者需要安装CUDA 10.0 和 CUDNN 7.4.2,所以要先卸载原来的CUDA。注意以下的命令都是在root用户下操作的。
卸载CUDA很简单,一条命令就可以了,主要执行的是CUDA自带的卸载脚本,读者要根据自己的cuda版本找到卸载脚本:
sudo /usr/local/cuda-8.0/bin/uninstall_cuda_8.0.pl
卸载之后,还有一些残留的文件夹,之前安装的是CUDA 8.0。可以一并删除:
sudo rm -rf /usr/local/cuda-8.0/
这样就算卸载完了CUDA。
安装CUDA
安装的CUDA和CUDNN版本:
接下来的安装步骤都是在root用户下操作的。
下载和安装CUDA
我们可以在官网:CUDA10下载页面,
下载符合自己系统版本的CUDA。页面如下:
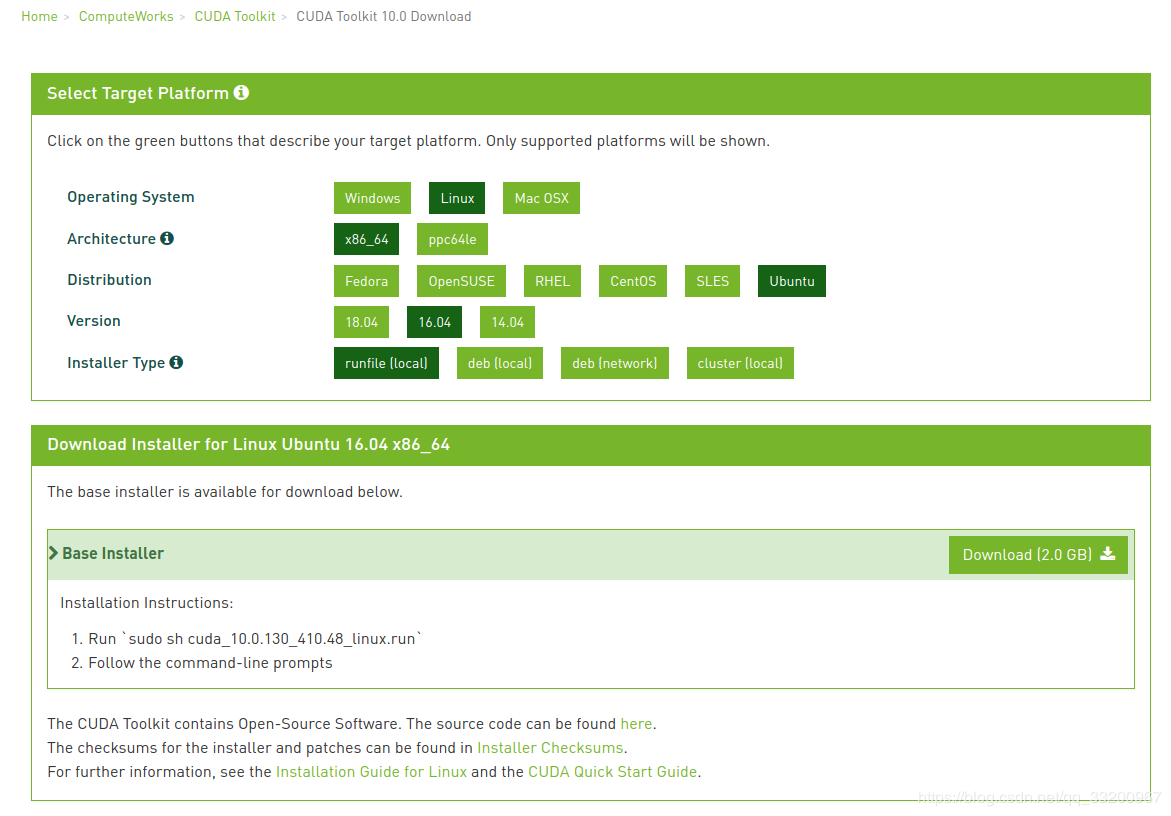
下载完成之后,给文件赋予执行权限:
chmod +x cuda_10.0.130_410.48_linux.run
执行安装包,开始安装:
./cuda_10.0.130_410.48_linux.run
开始安装之后,需要阅读说明,可以使用Ctrl + C直接阅读完成,或者使用空格键慢慢阅读。然后进行配置,我这里说明一下:
(是否同意条款,必须同意才能继续安装)
accept/decline/quit: accept
(这里不要安装驱动,因为已经安装最新的驱动了,否则可能会安装旧版本的显卡驱动,导致重复登录的情况)
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 410.48?
(y)es/(n)o/(q)uit: n
Install the CUDA 10.0 Toolkit?(是否安装CUDA 10 ,这里必须要安装)
(y)es/(n)o/(q)uit: y
Enter Toolkit Location(安装路径,使用默认,直接回车就行)
[ default is /usr/local/cuda-10.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?(同意创建软链接)
(y)es/(n)o/(q)uit: y
Install the CUDA 10.0 Samples?(不用安装测试,本身就有了)
(y)es/(n)o/(q)uit: n
Installing the CUDA Toolkit in /usr/local/cuda-10.0 ...(开始安装)
安装完成之后,可以配置他们的环境变量,在vim ~/.bashrc的最后加上以下配置信息:
export CUDA_HOME=/usr/local/cuda-10.0
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}
最后使用命令source ~/.bashrc使它生效。
可以使用命令nvcc -V查看安装的版本信息:
test@test:~$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
测试安装是否成功
执行以下几条命令:
cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
make
./deviceQuery
正常情况下输出:
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 2070"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 7950 MBytes (8335982592 bytes)
(36) Multiprocessors, ( 64) CUDA Cores/MP: 2304 CUDA Cores
GPU Max Clock rate: 1620 MHz (1.62 GHz)
Memory Clock rate: 7001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.0, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
下载和安装CUDNN
进入到CUDNN的下载官网:https://developer.nvidia.com/rdp/cudnn-download ,然点击Download开始选择下载版本,当然在下载之前还有登录,选择版本界面如下,我们选择cuDNN Library for Linux:
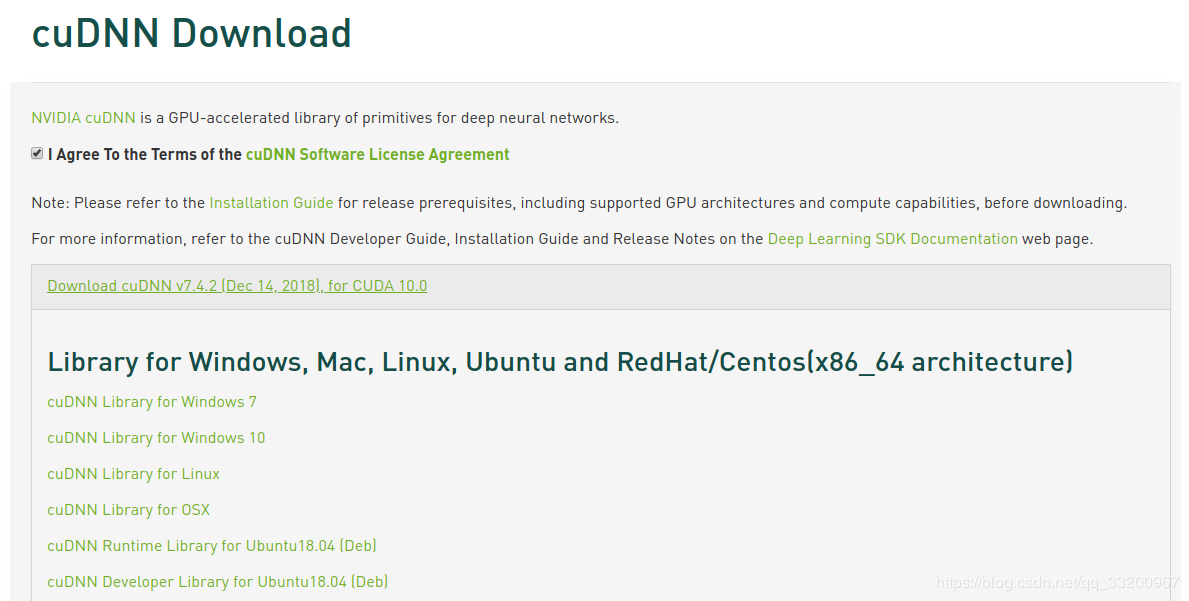
下载之后是一个压缩包,如下:
cudnn-10.0-linux-x64-v7.4.2.24.tgz
然后对它进行解压,命令如下:
tar -zxvf cudnn-10.0-linux-x64-v7.4.2.24.tgz
解压之后可以得到以下文件:
cuda/include/cudnn.h
cuda/NVIDIA_SLA_cuDNN_Support.txt
cuda/lib64/libcudnn.so
cuda/lib64/libcudnn.so.7
cuda/lib64/libcudnn.so.7.4.2
cuda/lib64/libcudnn_static.a
使用以下两条命令复制这些文件到CUDA目录下:
cp cuda/lib64/* /usr/local/cuda-10.0/lib64/
cp cuda/include/* /usr/local/cuda-10.0/include/
拷贝完成之后,可以使用以下命令查看CUDNN的版本信息:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
测试安装结果
到这里就已经完成了CUDA 10 和 CUDNN 7.4.2 的安装。可以安装对应的Pytorch的GPU版本测试是否可以正常使用了。安装如下:
pip3 install https://download.pytorch.org/whl/cu100/torch-1.0.0-cp35-cp35m-linux_x86_64.whl
pip3 install torchvision
然后使用以下的程序测试安装情况:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def main():
cudnn.benchmark = True
torch.manual_seed(1)
device = torch.device("cuda")
kwargs = {'num_workers': 1, 'pin_memory': True}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
for epoch in range(1, 11):
train(model, device, train_loader, optimizer, epoch)
if __name__ == '__main__':
main()
如果正常输出一下以下信息,证明已经安装成了:
Train Epoch: 1 [0/60000 (0%)] Loss: 2.365850
Train Epoch: 1 [640/60000 (1%)] Loss: 2.305295
Train Epoch: 1 [1280/60000 (2%)] Loss: 2.301407
Train Epoch: 1 [1920/60000 (3%)] Loss: 2.316538
Train Epoch: 1 [2560/60000 (4%)] Loss: 2.255809
Train Epoch: 1 [3200/60000 (5%)] Loss: 2.224511
Train Epoch: 1 [3840/60000 (6%)] Loss: 2.216569
Train Epoch: 1 [4480/60000 (7%)] Loss: 2.181396
参考资料
https://developer.nvidia.com
https://www.cnblogs.com/luofeel/p/8654964.html
到此这篇关于Ubuntu安装和卸载CUDA和CUDNN的实现的文章就介绍到这了,更多相关Ubuntu安装和卸载CUDA和CUDNN内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!






 京公网安备 11010802041100号
京公网安备 11010802041100号