快速探索图数据与图计算
图计算是研究客观世界当中的任何事物和事物之间的关系,对其进行完整的刻划、计算和分析的一门技术。图计算依赖底于底层图数据模型,在图数据模型基础上计算分析Spark是一个非常流行且成熟稳定的计算引擎。下面文章从ONgDB与Spark的集成开始【使用TensorFlow等深度学习框架分析图数据的方案不在本文的讨论范围,仅从图数据库领域探讨与Spark的集成是一个比较流行的方案,可以做一些基础图数据的计算与预训练提交给TensorFlow】,介绍一下具体集成实施方案。下载案例项目源代码可以帮助新手快速开始探索,不必踩坑。大致流程是先在Spark集群集成图数据库插件,然后使用具体API构建图数据分析代码。
在Spark集群安装neo4j-spark插件
https://github.com/ongdb-contrib/neo4j-spark-connector/releases/tag/2.4.1-M1
E:\software\ongdb-spark\spark-2.4.0-bin-hadoop2.7\jars
基础组件依赖信息
Spark 2.4.0 http://archive.apache.org/dist/spark/spark-2.4.0/
ONgDB 3.5.x
Neo4j-Java-Driver 1.7.5
Scala 2.11
JDK 1.8
hadoop-2.7.7
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
neo4j-spark-connector-full-2.4.1-M1 https://github.com/neo4j-contrib/neo4j-spark-connector
hadoop-2.7.7
spark-2.4.0-bin-hadoop2.7
winutils
neo4j-spark-connector-full-2.4.1-M1 【把jar包放到spark/jars文件夹里】
scala-2.11.12
创建测试数据
UNWIND range(1,100) as id
CREATE (p:Person {id:id}) WITH collect(p) as people
UNWIND people as p1
UNWIND range(1,10) as friend
WITH p1, people[(p1.id + friend) % size(people)] as p2
CREATE (p1)-[:KNOWS {years: abs(p2.id - p2.id)}]->(p2)
FOREACH (x in range(1,1000000) | CREATE (:Person {name:"name"+x, age: x%100}));
UNWIND range(1,1000000) as x
MATCH (n),(m) WHERE id(n) = x AND id(m)=toInt(rand()*1000000)
CREATE (n)-[:KNOWS]->(m);
备注
https://github.com/ongdb-contrib/ongdb-spark-java-scala-example
下载依赖包如果出现问题请检查下面网址是否可以正常下载Spark相关的JAR包
http://dl.bintray.com/spark-packages/maven
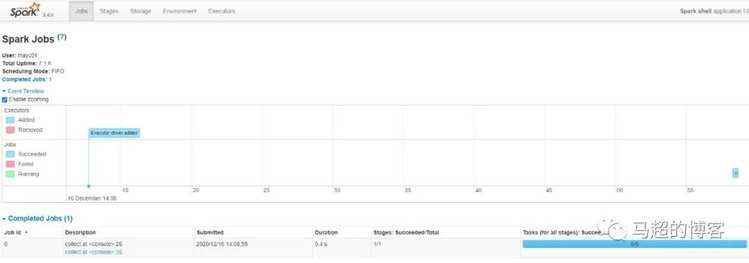
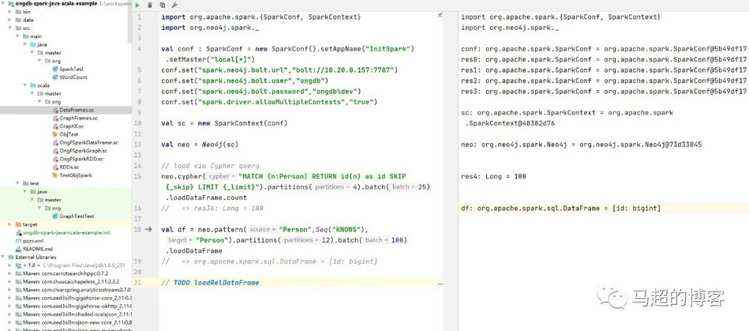











 京公网安备 11010802041100号
京公网安备 11010802041100号