transfer-eccoding所描述的是消息请求(request)和响应(response)所附带的实体对象(entity)的传输形式,规范定义格式如下:
Transfer-Encoding = "Transfer-Encoding" ":" 1#transfer-coding
举个例子:Transfer-Encoding: chunked
transfer-encoding的可选值有:chunked,identity ;
transfer-encoding的可选值有:chunked,identity,从字面意义可以理解,前者指把要发送传输的数据切割成一系列的块数据传输,后者指传输时不做任何处理,自身的本质数据形式传输。举个例子,如果我们要传输一本“红楼梦”小说到服务器,chunked方式就会先把这本小说分成一章一章的,然后逐个章节上传,而identity方式则是从小说的第一个字按顺序传输到最后一个字结束。
Content-Encoding : content-encoding和transfer-encoding所作用的对象不同,行为目标也不同,前者是对数据内容采用什么样的编码方式,后者是对数据传输采用什么样的编码。前者通常是对数据内容进行一些压缩编码操作,后者通常是对传传输采用分块策略之类的。
Content-length : content-length头的作用是指定待传输的内容的字节长度。比如上面举的例子中,我们要上传一本红楼梦小说,则可以指定其长度大小,如:content-length:731017。细心的读者可能会有疑惑,它和transfer-encoding又有什么关系呢?如果想知道它们的关系,只要反过来问下自己,为什么transfer-encoding会有identity和chunked两种,各在什么上下文情景中要用到。比如chunked方式,把数据分块传输在很多地方就非常有用,如服务端在处理一个复杂的问题时,其返回结果是阶段性的产出,不能一次性知道最终的返回的总长度(content-lenght值),所以这时候返回头中就不能有content-lenght头信息,有也要忽略处理。所以你可以这样理解,transfer-encoding在不能一次性确定消息实体(entity)内容时自定义一些传输协议,如果能确定的话,则可以在消息头中加入content-length头信息指示其长度,可以把transfer-encoding和content-length看成互斥性的两种头。
chunked格式(rfc2616 3.6.1):

Chunked-Body = *chunk
last-chunk
trailer
CRLF
chunk = chunk-size [ chunk-extension ] CRLF
chunk-data CRLF
chunk-size = 1*HEX
last-chunk = 1*("0") [ chunk-extension ] CRLF
chunk-extension= *( ";" chunk-ext-name [ "=" chunk-ext-val ] )
chunk-ext-name = token
chunk-ext-val = token | quoted-string
chunk-data = chunk-size(OCTET)
trailer = *(entity-header CRLF)
还是以上传“红楼梦”这本书举例: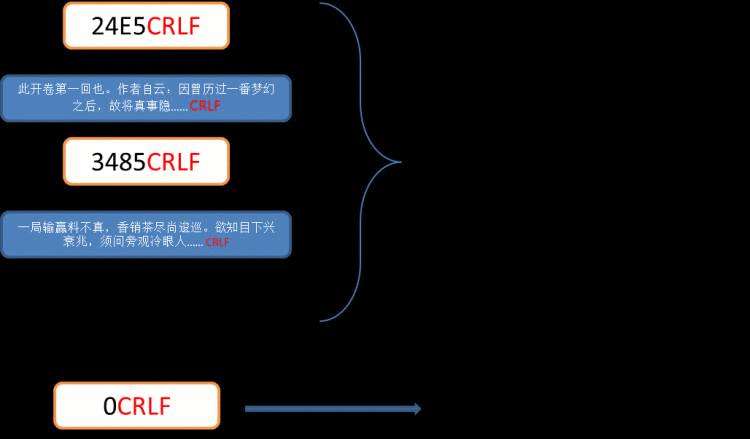
24E5是指第一个块数据长度为24E5(16进制格式字符串表示),CRLF为换行控制符。紧接着是第一个块数据内容,其长度就是上面定义的24E5,以CRLF标志结束。3485是指第二块数据长度为3485,CRLF结束,然后后面是第二块的数据内容......,以这样的格式直到所有的块数据结束。最后以“0”CRLF结束,表示数据传输完成(这里对比rfc规范内容,省略了chunk-extension和trailer的东西,因为这并不重要)。
以上转自:http://www.cnblogs.com/jcli/archive/2012/10/19/2730440.html 非常感谢这同学,使我认识 transfer-encoding。
一下是我看cowboy源码看到的对 transfer-encoding 的实现。
cowboy模块cowboy_req.erl,该模块用于读取实体数据,根据 transfer-encoding 传输类型调用不同的数据处理方法,蓝色字是Transfer-Encoding 的处理方法。
%% Request Body API.-spec has_body(req()) -> boolean().
has_body(Req) ->case lists:keyfind(<<"content-length">>, 1, Req#http_req.headers) of{_, <<"0">>} ->false;{_, _} ->true;_ ->lists:keymember(<<"transfer-encoding">>, 1, Req#http_req.headers)end.%% The length may not be known if Transfer-Encoding is not identity,
%% and the body hasn&#39;t been read at the time of the call.
-spec body_length(Req) -> {undefined | non_neg_integer(), Req} when Req::req().
body_length(Req) ->case parse_header(<<"transfer-encoding">>, Req) of{ok, [<<"identity">>], Req2} ->{ok, Length, Req3} &#61; parse_header(<<"content-length">>, Req2, 0),{Length, Req3};{ok, _, Req2} ->{undefined, Req2}end.-spec body(Req)-> {ok, binary(), Req} | {more, binary(), Req}| {error, atom()} when Req::req().
body(Req) ->body(Req, []).-spec body(Req, body_opts())-> {ok, binary(), Req} | {more, binary(), Req}| {error, atom()} when Req::req().
%% &#64;todo This clause is kept for compatibility reasons, to be removed in 1.0.
body(MaxBodyLength, Req) when is_integer(MaxBodyLength) ->body(Req, [{length, MaxBodyLength}]);
body(Req&#61;#http_req{body_state&#61;waiting}, Opts) ->%% Send a 100 continue if needed (enabled by default).Req1 &#61; case lists:keyfind(continue, 1, Opts) of{_, false} ->Req;_ ->{ok, ExpectHeader, Req0} &#61; parse_header(<<"expect">>, Req),ok &#61; case ExpectHeader of[<<"100-continue">>] -> continue(Req0);_ -> okend,Req0end,%% Initialize body streaming state.CFun &#61; case lists:keyfind(content_decode, 1, Opts) offalse ->fun cowboy_http:ce_identity/1;{_, CFun0} ->CFun0end,case lists:keyfind(transfer_decode, 1, Opts) offalse ->case parse_header(<<"transfer-encoding">>, Req1) of{ok, [<<"chunked">>], Req2} ->body(Req2#http_req{body_state&#61;{stream, 0,fun cow_http_te:stream_chunked/2, {0, 0}, CFun}}, Opts);{ok, [<<"identity">>], Req2} ->{Len, Req3} &#61; body_length(Req2),case Len of0 ->{ok, <<>>, Req3#http_req{body_state&#61;done}};_ ->body(Req3#http_req{body_state&#61;{stream, Len,fun cow_http_te:stream_identity/2, {0, Len},CFun}}, Opts)endend;{_, TFun, TState} ->body(Req1#http_req{body_state&#61;{stream, 0,TFun, TState, CFun}}, Opts)end;
body(Req&#61;#http_req{body_state&#61;done}, _) ->{ok, <<>>, Req};
body(Req, Opts) ->ChunkLen &#61; case lists:keyfind(length, 1, Opts) offalse -> 8000000;{_, ChunkLen0} -> ChunkLen0end,ReadLen &#61; case lists:keyfind(read_length, 1, Opts) offalse -> 1000000;{_, ReadLen0} -> ReadLen0end,ReadTimeout &#61; case lists:keyfind(read_timeout, 1, Opts) offalse -> 15000;{_, ReadTimeout0} -> ReadTimeout0end,body_loop(Req, ReadTimeout, ReadLen, ChunkLen, <<>>).body_loop(Req&#61;#http_req{buffer&#61;Buffer, body_state&#61;{stream, Length, _, _, _}},ReadTimeout, ReadLength, ChunkLength, Acc) ->{Tag, Res, Req2} &#61; case Buffer of<<>> ->body_recv(Req, ReadTimeout, min(Length, ReadLength));_ ->body_decode(Req, ReadTimeout)end,case {Tag, Res} of{ok, {ok, Data}} ->{ok, <
%% transferred data, and then another is applied to the actual content.
%%
%% Transfer encoding is generally used for chunked bodies. The decoding
%% function uses a state to keep track of how much it has read, which is
%% also initialized through this function.
%%
%% Content encoding is generally used for compression.
%%
%% &#64;todo Handle chunked after-the-facts headers.
%% &#64;todo Depending on the length returned we might want to 0 or &#43;5 it.
body_decode(Req&#61;#http_req{buffer&#61;Data, body_state&#61;{stream, _,TDecode, TState, CDecode}}, ReadTimeout) ->case
cowboy中模块cowboy_http_te.erl&#xff0c;该模块中实现了对 Transfer-Encoding 传输的消息体的解析。
Transfer-Encoding:identity传输编码的消息体的解析
%% Identity.%% &#64;doc Decode an identity stream.-spec stream_identity(Data, State)-> {more, Data, Len, State} | {done, Data, Len, Data}when Data::binary(), State::state(), Len::non_neg_integer().
stream_identity(Data, {Streamed, Total}) ->Streamed2 &#61; Streamed &#43; byte_size(Data),ifStreamed2
identity(Data) ->Data.
Transfer-Encoding:chunked 传输编码的消息体解析
%% Chunked.%% &#64;doc Decode a chunked stream.-spec stream_chunked(Data, State)-> more | {more, Data, State} | {more, Data, Len, State}| {more, Data, Data, State}| {done, Len, Data} | {done, Data, Len, Data}when Data::binary(), State::state(), Len::non_neg_integer().
stream_chunked(Data, State) ->stream_chunked(Data, State, <<>>).%% New chunk.
stream_chunked(Data &#61; <
%% Trailing \r\n before next chunk.
stream_chunked(<<"\r\n", Rest/bits >>, {2, Streamed}, Acc) ->stream_chunked(Rest, {0, Streamed}, Acc);
%% Trailing \r before next chunk.
stream_chunked(<<"\r" >>, {2, Streamed}, Acc) ->{more, Acc, {1, Streamed}};
%% Trailing \n before next chunk.
stream_chunked(<<"\n", Rest/bits >>, {1, Streamed}, Acc) ->stream_chunked(Rest, {0, Streamed}, Acc);
%% More data needed.
stream_chunked(<<>>, State &#61; {Rem, _}, Acc) ->{more, Acc, Rem, State};
%% Chunk data.
stream_chunked(Data, {Rem, Streamed}, Acc) when Rem > 2 ->DataSize &#61; byte_size(Data),RemSize &#61; Rem - 2,case Data of<
chunked_len(<<$1, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 1);
chunked_len(<<$2, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 2);
chunked_len(<<$3, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 3);
chunked_len(<<$4, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 4);
chunked_len(<<$5, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 5);
chunked_len(<<$6, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 6);
chunked_len(<<$7, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 7);
chunked_len(<<$8, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 8);
chunked_len(<<$9, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 9);
chunked_len(<<$A, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 10);
chunked_len(<<$B, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 11);
chunked_len(<<$C, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 12);
chunked_len(<<$D, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 13);
chunked_len(<<$E, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 14);
chunked_len(<<$F, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 15);
chunked_len(<<$a, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 10);
chunked_len(<<$b, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 11);
chunked_len(<<$c, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 12);
chunked_len(<<$d, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 13);
chunked_len(<<$e, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 14);
chunked_len(<<$f, R/bits >>, S, A, Len) -> chunked_len(R, S, A, Len * 16 &#43; 15);
%% Final chunk.
chunked_len(<<"\r\n\r\n", R/bits >>, S, <<>>, 0) -> {done, S, R};
chunked_len(<<"\r\n\r\n", R/bits >>, S, A, 0) -> {done, A, S, R};
chunked_len(_, _, _, 0) -> more;
%% Normal chunk. Add 2 to Len for the trailing \r\n.
chunked_len(<<"\r\n", R/bits >>, S, A, Len) -> {next, R, {Len &#43; 2, S}, A};
chunked_len(<<"\r">>, _, <<>>, _) -> more;
chunked_len(<<"\r">>, S, A, _) -> {more, {0, S}, A};
chunked_len(<<>>, _, <<>>, _) -> more;
chunked_len(<<>>, S, A, _) -> {more, {0, S}, A}.





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 