作者:yo繽紛樂 | 来源:互联网 | 2023-08-15 07:00
现在语义分割领域,最热门的当属Transformer的应用了,你要是在网络中不添加,那么就显得你的创新点大大降低。但是现在语义分割领域Transformer的计算量太大了,导致应用的还比较少。这两天我看到一篇比较好的论文,也给我们提供了一种新的语义分割思路。
这篇文章是TopFormer,其中作者使用了一些方法来降低模型运算复杂度:
- 作者利用了CNN和ViT的优势。构建了一个基于CNN的模块,称为
Token Pyramid Module,用于处理高分辨率图像,以快速生成局部特征金字塔。考虑到在移动设备上非常有限的计算能力,在这里使用一些堆叠的轻量级MobileNetV2 Block和Fast Down-Sampling策略来构建一个Token Pyramid。 - 为了获得丰富的语义和较大的感受野,作者还构建了一个基于ViT的模块,即Scale-aware Semantics Extractor,并将
Token沿着通道维度进行拼接后,输入到Transformer Block中,从而产生与Token的尺度有关的全局语义。 - 为了进一步降低计算成本,使用
Average Pooling Operator将Token减少到一个非常小的数字,例如,输入大小的1/(64×64)。 - 为了获得密集预测任务的强大层次特征,将尺度感知的全局语义通过不同尺度的
Token通道进行分割,然后将标度感知的全局语义与相应的Token融合,以增强表示。
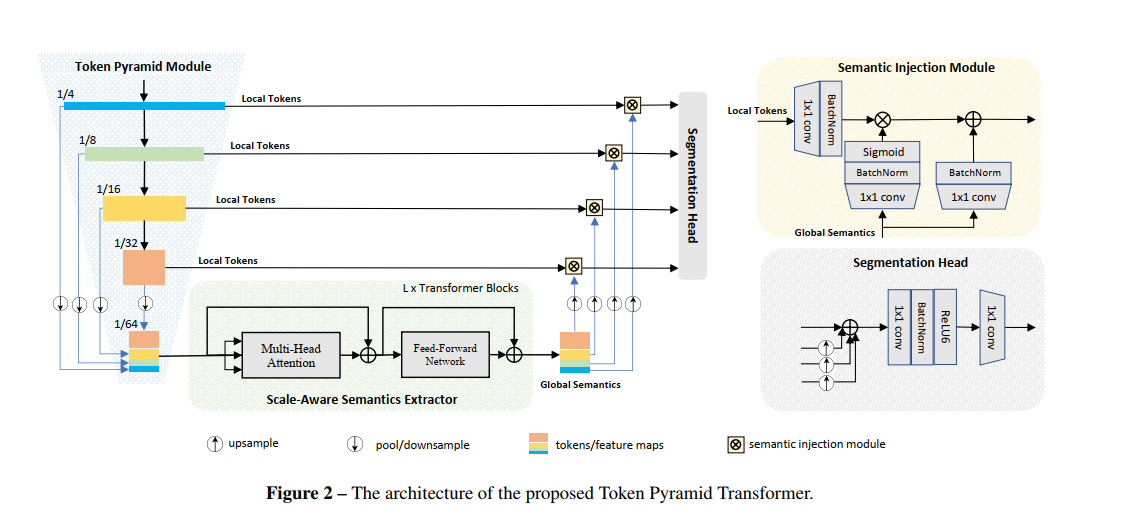
整个网络如上图所示,整个网络逻辑还和U-Net 类似,在我看来,整个网络最精华的部分是Token Pyramid Module 部分,这个部分在一般的U-Net网络中很少这么操作。看到这我想试试在正常的注意力操作中使用这个结构会不会有效果。其实后面的tran等结构都是可以替换成其他有效的注意力模块之类。











 京公网安备 11010802041100号
京公网安备 11010802041100号