作者:姚若薇_453 | 来源:互联网 | 2023-07-30 21:57
前言在上一部分我们介绍了概率论的基础,本节我们介绍一些信息论里面需要了解的基本概念。信息论基础熵(entropy)香农(ClaudeElwoodShannon)于19
前言
在上一部分我们介绍了概率论的基础,本节我们介绍一些信息论里面需要了解的基本概念。
信息论基础
熵(entropy)
香农(Claude Elwood Shannon)于1940年获得麻省理工学院数学博士学位和电子工程硕士学位后,于1941年加入了贝尔实验室数学部,并在那里工作了15年。1948年6月和10月,由贝尔实验室出版的《贝尔系统技术》杂志连载了香农博士的文章《通讯的数学原理》,该文奠定了香农信息论的基础。熵是信息论中重要的基本概念。
如果X 是一个离散型随机变量,其概率分布为:p(x) = P(X = x), 。X 的熵H(X) 为:
。X 的熵H(X) 为:

其中,约定0log 0 = 0。H(X) 可以写为H(p)。通常熵的单位为二进制位(bits)。
熵又称为自信息(self-information),表示信源X每发一个符号(不论发什么符号)所提供的平均信息量。熵也可以被视为描述一个随机变量的不确定性的数量。一个随机变量的熵越大,它的不确定性越大,那么,正确的估计其值的可能性就越小。越不确定的随机变量越需要大的信息量用以确定其值。


说明:考虑了英文字母和空格实际出现的概率后,英文信源的平均不确定性,比把字母和空格看作等概率出现时英文信源的平均不确定性要小。
联合熵(joint entropy)
如果X,Y是一对离散型随机变量X,Y~P(x,y),X,Y的联合熵H(X,Y)为:

联合熵实际上就是描述一对随机变量平均所需的信息量。
条件熵 (conditional entropy)
给定随机变量X的情况下,随机变量Y的条件熵定义为:


如果( X, Y ) ~ p(x, y),X, Y 之间的互信息I(X; Y) 为:I (X; Y) = H(X) –H( X | Y )。
根据定义,展开H(X) 和H(X|Y) 容易得到:

互信息I (X; Y) 是在知道了Y 的值后X 的不确定性的减少量。即,Y 的值透露了多少关于X 的信息量。

由于H(X, X) = 0, 所以,H(X) = H(X) –H(X|X) = I(X; X)。这一方面说明了为什么熵又称自信息,另一方面说明了两个完全相互依赖的变量之间的互信息并不是一个常量,而是取决于它们的熵。
交叉熵
如果一个随机变量X ~ p (x),q(x)为用于近似p(x)的概率分布,那么随机变量X和模型q之间的交叉熵定义为:

交叉熵的概念是用来衡量估计模型与真实概率分布之间差异情况的。对于语言L = (Xi) ~ p(x) 与其模型q的交叉熵定义为:

其中, 为语言L的语句,
为语言L的语句,  为L中语句的概率,
为L中语句的概率, 为模型q对
为模型q对 的概率估计。
的概率估计。
我们可以假设这种语言是“理想的”,即n趋于无穷大的时候,其全部“单词”的概率和为1。也就是说,根据信息论的定理:假定语言L是稳态的(stataionary)ergodic随机过程,L与其模型q的交叉熵计算公式就变为:

由此,我们可以根据模型q和一个含有大量数据的L的样本来计算交叉熵。在设计模型q时,我们的目的是使交叉熵最小,从而使模型最接近真实的概率分布p(x)。
困惑度(preplexity)
在设计语言模型的时候,我们通常用困惑度来代替交叉熵衡量语言模型的好坏。给定语言L的样本 ,L的困惑度
,L的困惑度 定义为:
定义为:

语言模型设计的任务就是寻找困惑度最小的模型,使其最接近真实的语言。
噪声信道模型(noisy cahnnel model)
在信号传输的过程中都要进行双重性处理:一方面要通过压缩消除所有的冗余,另一方面又要通过增加一定的可控冗余以保障输入信号经过噪声信道后可以很好的恢复原状。这样的话,信息编码时要尽量占有少量的空间,但又必须保持足够的冗余以便能够检测和校验错误。而接收到的信号需要被解码使其尽量恢复到原始的输入信号。
噪声信道模型的目标就是优化噪声信道中信号传输的吞吐量和准确率,其基本假设是一个信道的输出以一定的概率依赖于输入。

例如:一个二进制的对称信道(binary symmetric channel, BSC)的输入符号集X:{0, 1},输出符号集Y:{0, 1}。在传输过程中如果输入符号被误传的概率为p,那么,被正确传输的概率就是1-p。这个过程我们可以用一个对称的图型表示如下:

信息论中很重要的一个概念就是信道容量(capacity),其基本思想是用降低传输速率来换取高保真通讯的可能性。其定义可以根据互信息给出:

根据这个定义,如果我们能够设计一个输入编码X,其概率分布为p(X),使其输入与输出之间的互信息达到最大值,那么,我们的设计就达到了信道的最大传输容量。在自然语言处理中,我们不需要进行编码,只需要进行解码,使系统的输出更接近于输入。



也就是说,如果我们要建立一个源语言f 到目标语言e的统计翻译系统,我们必须解决三个关键的问题:
(1)估计语言模型概率P(e);
(2)估计翻译概率P(f | e);
(3)设计有效快速的搜索算法求解 eˆ使得P(e)×P(f | e)最大。

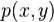



 京公网安备 11010802041100号
京公网安备 11010802041100号