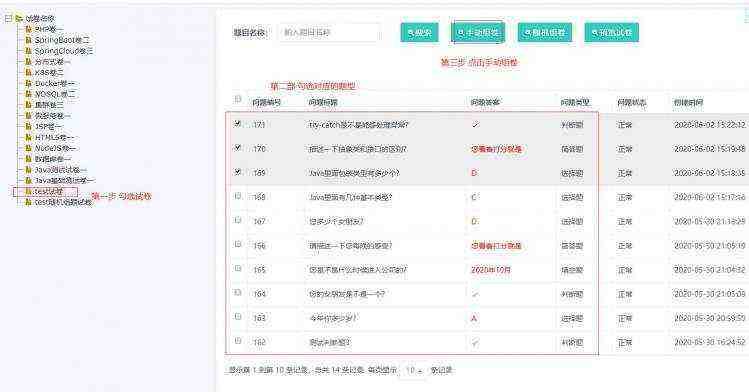
作者:艾特PONYO | 来源:互联网 | 2023-09-23 17:55
StarNet模型
1.背景
民以食为天,如何提升超大规模配送网络的整体配送效率,改善数亿消费者在”吃“方面的体验,是一项极具挑战的技术难题。面向未来,美团正在积极研发无人配送机器人,建立无人配送开放平台,与产学研各方共建无人配送创新生态,希望能在一个场景相对简单、操作高度重复的物流配送中,提高物流配送效率。在此过程中,美团无人配送团队也取得了一些技术层面的突破,比如基于神经网络StarNet的行人轨迹交互预测算法,论文已发表在IROS 2019。IROS 的全称是IEEE/RSJ International Conference on Intelligent Robots and Systems,IEEE智能机器人与系统国际会议,它和ICRA、RSS并称为机器人领域三大国际顶会。
在这项研究中,研究人员提出了一种新的检测器模型,通过在三维 LiDAR数据的背景下重新检查目标检测系统的设计,从而来更好地匹配数据形态和自动驾驶汽车感知的需求。他们首先指出一个事实,即三维区域的提议本质上是不同的,地面上的每个反射点都必须属于一个对象。
他们还表明,点云上的有效采样方案(零学习参数)足以生成区域提议。采样是因为它计算成本低,并且具有通过匹配场景的数据分布来间接利用数据稀疏性的特点。
研究人员随后在没有整体环境或共享信息的情况下处理每个提议的区域。最后,它们完全避免了任何离散化过程,并在其位置上使用本地点云分类和回归对象的边界框位置。通过重新审视当前技术的一些设计假设,他们在没有训练提议,也没有全局环境的情况下得到了一个非卷积的、基于点的对象检测器模型。
在使用KITTI和Waymo开放数据集进行评估时,这一StarNet检测器模型能在较低的推理成本下达到与现有技术一样的精确度,在类似的推理成本下甚至能做到更精确。
该模型不会浪费对空区域的计算。并且,该模型不使用全局语境,完全基于点,并且可以在推理时动态地改变提议的数量与每个提议的点数。由于每个区域都是完全独立的,因此可以在运行时根据环境选择分配区域提议的位置。简单来说,StarNet可用于定位空间位置,不需要重新训练,也不会牺牲预测质量。
原文链接:https://arxiv.org/abs/1908.11069v1
1.1 行人轨迹预测的意义
图1 主车规划轨迹跳变问题
图1中蓝色方块代表无人车,白色代表行人。上半部分描述的是在不带行人轨迹预测功能情况下无人车的行为。这种情况下,无人车会把行人当做静态物体,但由于每个时刻行人都会运动,导致无人车规划出来的行驶轨迹会随着时间不停地变化,加大了控制的难度,同时还可能产生碰撞的风险,这样违背了安全平稳行驶的目标。下半部分是有了行人轨迹预测功能情况下的无人车行为。这种情况下,无人车会预测周围行人的行驶轨迹,因此在规划自身行驶时会考虑到未来时刻是否会与行人碰撞,最终规划出来的轨迹更具有“预见性”,所以避免了不必要的轨迹变化和碰撞风险。
1.2 行人轨迹预测的难点
1.3 相关工作介绍
基于神经网络的预测算法(主要以长短期记忆神经网络Long Short Term Memory,LSTM为主)在最近5年都比较流行,预测效果确实比传统算法好很多。在CVPR(IEEE Conference on Computer Vision and Pattern Recognition) 2019上,仅行人预测算法的论文就有10篇左右。这里我们简单介绍2篇经典的行人预测算法思路,如果对这方面感兴趣的同学,可以通过文末的参考文献深入了解一下。第一篇是CVPR 2016斯坦福大学的工作Social-LSTM,也是最经典的工作之一。Social-LSTM为每个行人都配备一个LSTM网络预测其运动轨迹,同时提出了一个Social Pooling Layer的模块来计算周围其他行人对其的影响。具体的计算思路是将该行人周围的区域划分成NxN个网格,每个网络都是相同的大小,落入这些网格中的行人将会参与交互的计算。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eMQouvrn-1618891523551)(https://www.aboutyun.com/data/attachment/forum/201912/17/180721l2mmxpkm2m8o0ow0.jpg)]
第二篇是CVPR 2019卡耐基梅隆大学&谷歌&斯坦福大学的工作,他们的工作同样使用LSTM来接收历史信息并预测行人的未来轨迹。不同于其他算法的地方在于,这个模型不仅接收待预测行人的历史位置信息,同时也提取行人外观、人体骨架、周围场景布局以及周围行人位置关系,通过增加输入信息提升预测性能。除了预测具体的轨迹,算法还会做粗粒度预测(决策预测),输出行人未来时刻可能所在的区域。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BdQ96r9k-1618891523553)(https://www.aboutyun.com/data/attachment/forum/201912/17/180831iyggxggyzqrxjbxx.jpg)]
其他的相关工作,还包括基于语义图像/占有网格(Occupancy Grid Map, OGM)的预测算法,基于信息传递(Message Passing, MP)的预测算法,基于图网络(Graph Neural Network, GNN)的预测算法(GCN/GAT等)等等。2. StarNet介绍
假设感知模块检测到当前N个行人的位置,如何计算第一个行人下一时刻的位置?
Step 1计算其他人对于第一个行人的交互影响。将第i个行人在第t时刻的位置记为(一般是坐标x和y)。可以通过以下公式计算第一个行人的交互向量:
两两交互的方式存在两个问题:
(1) 障碍物2和3确实会影响障碍物1的运动,但是障碍物2和3之间同样也存在相互影响,因此不能直接将其他障碍物对待预测障碍物的影响单独剥离出来考虑,这与实际情况不相符。
基于上述两个问题,我们提出了一种新的模型,该模型旨在高效解决计算全局交互的问题。因为传统算法普遍存在计算两两交互的问题(即使是基于Attention注意力机制的Message Passing也很难考虑到全局的交互),本文想尝试通过一些更加简单直观的方式来考虑所有障碍物之间的全局交互,我们的算法大致思路如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gouI9Agw-1618891523557)(https://www.aboutyun.com/data/attachment/forum/201912/17/181106lomt1gakomtka11p.jpg)]
我们的算法结构如上图5所示,Host Network是基于LSTM的轨迹预测网络;Hub Network是基于LSTM的全局时序交互计算网络。在论文具体的实现中,首先Hub Network的静态地图模块是通过接受所有障碍物同一时刻的位置信息、全连接网络和最大池化操作得到一个定长的特征向量;然后动态地图模块使用LSTM网络对上述的特征向量进行时序编码,最终得到一个全局交互向量。Host Network首先根据行人(假设要预测第一个行人下时刻的位置)的位置
(a)平均距离差ADE(Average Displacement Error):用算法预测出的轨迹到真实轨迹所有8个点之间的平均距离差。
(b)终点距离差FDE(Final Displacement Error):用算法预测出的轨迹与真实轨迹最后一个终点之间的距离差。
(c)前向预测时间以及参数量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b3gMOth2-1618891523561)(https://www.aboutyun.com/data/attachment/forum/201912/17/181415mj25bj7h7ijh26y7.jpg)]
从实验结果可以看到,我们的算法在80%的场景下都优于其他算法,且实时性高(表中LSTM的推理时间为0.029秒,最快速是由于该算法不计算交互,因此速度最快参数也最少,但是性能较差)。
使用全局动态地图的形式来描述行人之间在时间和空间上的相互影响,更加合理,也更加准确。 Hub Network全局共享的特征提升了整个算法的计算效率。 3.未来工作
首先,我们会进一步探索新的模型结构。虽然我们的算法在数据集上取得了不错的效果,但这是我们的第一次尝试,模型设计也比较简单,如果提升模型结构,相信可以取得更好的结果。



 去动态地图中查询自己当前位置区域内的交互
去动态地图中查询自己当前位置区域内的交互  ,具体我们采用简单的点乘操作(类似于Attention机制)。最终自己的位置
,具体我们采用简单的点乘操作(类似于Attention机制)。最终自己的位置  一起输入LSTM网络预测下时刻的的位置
一起输入LSTM网络预测下时刻的的位置  。
。







 京公网安备 11010802041100号
京公网安备 11010802041100号