# sqoop安装
1. 常规步骤
由于sqoop2配置相对比较麻烦,此次使用的是sqoop1进行演示。
上传sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz文件至/hadoop目录下,解压并重命名为sqoop-1.4.4,配置/etc/profile文件并source刷新。
2. 配置驱动
将数据库连接驱动mysql-connector-5.1.8.jar拷贝到$SQOOP_HOME/lib里。
3. 一些解释
注意:如果是集群环境,则sqoop可以安装在任意一台节点上就可以。如果此节点已经指定了RM和NN的位置,则可以直接运行sqoop。
- ## Name Node在文件core-site.xml和hdfs-site.xml中指定。
- ## Resource Manage在文件yarn-site.xml中指定。
子节点为什么知道在上述三个文件中寻找NM和NN的位置?这是因为sqoop会读取 $HADOOP_HOME的值。
- sqoop也是将自己的指令转化成MR执行,不过它只有Mapper阶段。
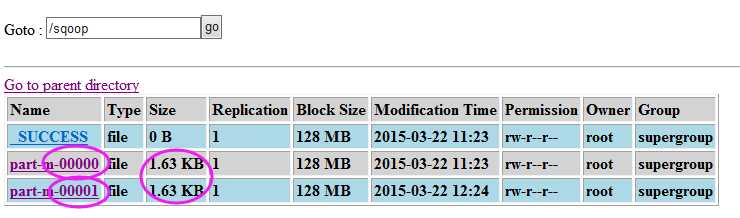
- sqoop执行结果产生的是part-m-00000文件,这是因为只有map阶段,生成的是map阶段的结果文件。
- sqoop转换结果文件默认是以”,“作为分隔符。
# 导入到hdfs
sqoop import --connect jdbc:mysql://192.168.8.100:3306/test --username root --password 123 --table goods --target-dir ‘/sqoop‘ --fields-terminated-by ‘\t‘ –m 1
Sqoop //sqoop命令
Import //表示导入
--connect jdbc:mysql://192.168.8.100:3306/test //告诉jdbc,连接MySQL的url,即test数据库。3306是MySQL默认监听端口,192.168.8.100是MySQL的IP。
--username root //连接root的用户名
--password 123 //连接root的密码
--table goods //从goods导出的表名称
--fields-terminated-by ‘\t‘ //指定输出文件中的行的字段分隔符
--null-string ‘**‘ //NULL值转化成”**”保存,默认是NULL
-m 1 //使用1个map作业,则产生一个结果文件。默认是4个
--append //追加数据到hdfs源文件中
--target-dir ‘/sqoop‘ //结果保存在 “/sqoop/” 文件夹中,直接在文件夹下输出结果文件。如果不使用该选项,意味着复制到默认目录“/user/root/”文件夹下,并产生“/test/goods/”目录,并在此目录之下输出结果文件prat-m-00000。
# 使用案例
导入指定的列 --column
sqoop import --connect jdbc:mysql://192.168.8.100:3306/test--username root --password 123 --table goods --columns ‘id, account, income, expenses‘
指定输出路径、指定数据分隔符
sqoop import --connect jdbc:mysql://192.168.8.100:3306/test --username root --password 123 --table goods --target-dir ‘/sqoop‘ --fields-terminated-by ‘\t‘
指定Map数量 -m
sqoop import --connect jdbc:mysql://192.168.8.100:3306/test --username root --password 123 --table goods --target-dir ‘/sqoop‘ --fields-terminated-by ‘\t‘ -m 2
增加where条件, (条件必须用引号引起来)
sqoop import --connect jdbc:mysql://192.168.8.100:3306/test --username root --password 123 --table goods --where ‘id>3‘ --target-dir ‘/sqoop‘
增加query语句(使用 \ 将语句换行)
sqoop import --connect jdbc:mysql://192.168.8.100:3306/test --username root --password 123 \
--query ‘SELECT * FROM goods where id > 2 AND $CONDITIONS‘ --split-by goods.id --target-dir ‘/sqoop‘
注意:如果使用 --query 这个命令的时候,需要注意的是where后面的参数,AND $CONDITIONS这个参数必须加上,而且存在单引号与双引号的区别,如果--query后面使用的是双引号,那么需要在 $CONDITIONS 前加上 \(转义符) 即 \$CONDITIONS 。如果设置map数量为1个时即-m 1,不用加上--split-by ${tablename.column},否则需要加上【表示不同的mapper任务,分割整体数据的依据,此处为good.id来分割数据。】
将HDFS上的数据导出到数据库中(不要忘记指定分隔符)
sqoop export --connect jdbc:mysql://192.168.8.101:3306/itcast --username root --password 123 --export-dir ‘/td3‘ --table td_bak -m 1 --fields-terminated-by ‘,‘
- 注意:sqoop导出到mysql,源文件是文件夹,而不是文件。
- 还有一点就是导出到mysql,这个指令可以重复执行,即,mysql数据重复增加。相对而言,导入hdfs操作则只能执行一次,不然会报错。

- 如果在导入hdfs指令后面加上 –append 则会在同一目录下生成一相同文件,不能满足只导出增量部分的要求
# 增量导入
sqoop import -connect jdbc:mysql://192.168.8.100:3306/test --username root --password 123 --table goods -m 1 --fields-terminated-by ‘\t‘ --target-dir ‘/sqoop‘ --append --check-column ‘goods_id‘ --incremental append --last-value 32
说明:
--append //表示追加写入hdfs。没有此命令,则报目录已存在的错误
--check-column ‘goods_id’ //表示判断依据为”goods_id”这一列
--incremental append //如果有增量则追加写入操作
--last-value 32 //判断依据为上一次的”goods_id”的值 32
如果mysql中的数据确实有增加,使用上述命令则会产生一个新的文件,文件中保存增加的数据。

# sqoop job
sqoop job --create myjob -- import -connect jdbc:mysql://192.168.8.100:3306/test --username root --password 123 --table goods -m 1 --fields-terminated-by ‘\t‘ --target-dir ‘/sqoop‘ --append --check-column ‘goods_id‘ --incremental append --last-value 32

- 使用命令sqoop job --list查看可使用的sqoop job.
- 使用命令 sqoop job --exec myjob来执行job脚本

此处要输入一次mysql用户root的密码,然后就可以自动执行job脚本了。
现在配置如何不用输入密码,直接执行job脚本:
在”/hadoop/sqoop-1.4.4/conf/sqoop-site-xml”文件中,打开是否允许保存密码的属性,即去掉圈中的部分。
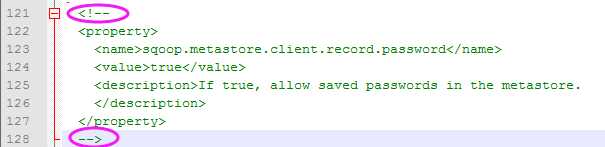
这样还是不可以自动执行的,必须得先把原有的job删掉,然后重新创建一个新的job,才能满足需求,然后就可以自动执行了。

# Sqoop 事务
sqoop导入导出的事务是以Mapper任务为单位。启动了4个Mapper任务,则就表示有4个事务。
# 导入到Hbase
sqoop import --connect jdbc:mysql://mysqlserver_IP/databaseName –table datatable --hbase-create-table --hbase-table hbase_tablename --column-family col_fam_name --hbase-row-key key_col_name
说明:
--hbase-create-table //导出到hbase上,如果没有目标表,则创建新表
--hbase-table hbase_tablename //指出要保存到hbase上的表名字
--column-family col_fam_name //col_fam_name是除rowkey之外的所有列的列族名
--hbase-row-key key_col_name //key_col_name指出datatable中哪一列作为hbase新表的Row Key

# 从Oracle导入数据
- sqoop从oracle导入,需要有ojdbc6.jar,放在$SQOOP_HOME/lib里,不用添加到classpath里,因为sqoop会自己遍历lib文件夹并添加里面的所有jar包
- --connect与mysql的不一样,如下(shell脚本中的主要部分)
- #Oracle的连接字符串,其中包含了Oracle的地址,SID,和端口:COnNECTURL=jdbc:oracle:thin:@172.7.10.16:1521:orcl
- #使用的用户名:ORACLENAME=scott
- #使用的密码:ORACLEPASSWORD=wang123456
- #需要从Oracle中导入的表名:oralceTableName=test
- #需要从Oracle中导入的表中的字段名:columns=ID,STATE
- #将Oracle中的数据导入到HDFS后的存放路径:hdfsPath=/tmp/
- #完整的命令:
sqoop import --append --connect $CONNECTURL --username $ORACLENAME --password $ORACLEPASSWORD --m 1 --table $oralceTableName –columns $columns --hbase-create-table --hbase-table or1 --hbase-row-key STATE --column-family or1
Sqoop相关





 京公网安备 11010802041100号
京公网安备 11010802041100号