前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
正文

Sqoop 概述
Sqoop 从工程角度,解决了关系型数据库与 Hadoop 之间的数据传输问题,它构建了两者之间的“桥梁"”,使得数据迁移工作变得异常简单。
在实际项目中,如果遇到以下任务,可尝试使用 Sqoop 完成:
数据迁移
公司内部商用关系型数据仓库中的数据以分析为主,综合考虑扩展性、容错性和成本开销等方面。
若将数据迁移到 Hadoop 大数据平台上,可以方便地使用 Hadoop 提供的如 Hive 、 SparkSQL 分布式系统等工具进行数据分析。
为了一次性将数据导人 Hadoop 存储系统,可使用 Sqoop
可视化分析结果
Hadoop 处理的输入数据规模可能是非常庞大的,比如 PB 级别,但最终产生的分析结果可能不会太大,比如报表数据等,而这类结果通常需要进行可视化,以便更直观地展示分析结果。
目前绝大部分可视化工具与关系型数据库对接得比较好,因此,比较主流的做法是,将 Hadoop 产生的结果导入关系型数据库进行可视化展示。
数据增量导入
考虑到 Hadoop 对事务的支持比较差,因此,凡是涉及事务的应用比如支付平台等,后端的存储均会选择关系型数据库,而事务相关的数据,比如用户支付行为等,可能在 Hadoop 分析过程中用到(比如广告系统,推荐系统等)。
为了减少 Hadoop 分析过程中影响这类系统的性能,我们通常不会直接让 Hadoop 访问这些关系型数据库,而是单独导入一份到 Hadoop 存储系统中。
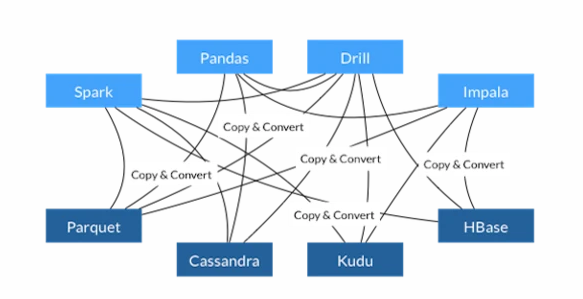
为了解决上述数据收集过程中遇到的问题, Apache Sqoop 项目诞生了,它是一个性能高、易用、灵活的数据导入导出工具,在关系型数据库与 Hadoop 之间搭建了一个桥梁,如图所示,让关系型数据收集变得异常简单。

Sqoop 基本思想及特点
Sqoop 采用插拔式 Connector 架构, Connector 是与特定数据源相关的组件,主要负责(从特定数据源中)抽取和加载数据。
用户可选择 Sqoop 自带的 Connector ,或者数据库提供商发布的 native Connector ,甚至根据自己的需要定制 Connector ,从而把 Sqoop 打造成一个公司级别的数据迁移统一管理工具。
Sqoop 主要具备以下特点:
- 性能高: Sqoop 采用 MapReduce 完成数据的导入导出,具备了 MapReduce 所具有的优点,包括并发度可控、容错性高、扩展性高等。
- 自动类型转换: Sqoop 可读取数据源元信息,自动完成数据类型映射,用户也可根据需要自定义类型映射关系。
- 自动传播元信息: Sqoop 在数据发送端和接收端之间传递数据的同时,也会将元信息传递过去,保证接收端和发送端有一致的元信息。
Apache Sqoop 项目已经被 Apache 基金会终止
小企业还是可以使用的,大企业建议使用 DataX 等迁移工具,Sqoop后续已经不维护了
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件,邮件中提到,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到这个项目;Apache Sqoop 项目的活跃程度越来越低。所以 venkatrangan 发邮件给社区是想看下社区是否对 Sqoop 有新的 roadmap,否则把 Apache Sqoop 移到 Apache Attic 是比较合适的。
不过几天过去了,看起来好像没有人有新的 roadmap。紧接着,5月14日,venkatrangan 又给社区发了一个投票《VOTE: Move Apache Sqoop to attic》
最后有三个 PMC 投票同意这个决定。
在6月16日举办的 Apache Board Meeting,董事会一致决定:Terminate the Apache Sqoop project(终止 Apache Sqoop 项目)!








 京公网安备 11010802041100号
京公网安备 11010802041100号