kubernetes 发展速度非常,至少在目前来说是非常不错的,很多大公司都在使用容器技术部署项目,而最近比较火的容器管理工具就是kubernetes了。
由于之前公司一直使用的还是yum安装的v1.5.2,因为没什么大的需求就一直没有更新到新版本,这次出来的1.9.0版本。听说功能更强大,所以就自己机器上搭建一个小群集来测试。因为网上还没有build好的rpm包,原本自己打算制作一个的,但是技术信息有限暂时未能做出来。可是又很想使用新版本,所以直接在网官上下载一个二进制的tar包来。
系统:CentOS Linux release 7.2.1511 (Core)
内核可以升级,如果不升级也可以运行,但是会在日志里有提示。
- ########################################################
- 节点名 主机名 IP地址
- etcd etcd 10.0.10.11
- k8s-master k8s-master 10.0.10.12
- k8s-node1 k8s-node1 10.0.10.13
- k8s-node2 k8s-node2 10.0.10.14
机器之间做好时间同步:
- yum install ntpd -y
- systemctl start ntpd
- systemctl enable ntpd
添加主机名IP地址的对应解析到/etc/hosts文件:
- [root@k8s-master system]# tail -5 /etc/hosts
- 192.168.18.54 reg.docker.tb
- 10.0.10.11 etcd
- 10.0.10.12 k8s-master
- 10.0.10.13 k8s-node1
- 10.0.10.14 k8s-node2
并在Master节点上做一个ssh-key免密登陆,传到每个节点上,和etcd机器。
软件包下载地址:
etcd:https://github.com/coreos/etcd/releases/download/v3.2.11/etcd-v3.2.11-linux-amd64.tar.gz
kubernetes: https://codeload.github.com/kubernetes/kubernetes/tar.gz/v1.9.0
配置Etcd服务器
- tar xf etcd-v3.2.11-linux-amd64.tar.gz
- cd etcd-v3.2.11-linux-amd64
- cp etcd etcdctl /usr/bin/
添加用户和组,这里的组ID和用户ID可以不用指定
- [root@etcd system]# groupadd -g 990 etcd
- [root@etcd system]# useradd -s /sbin/nologin -M -c "etcd user" -u 991 etcd -g etcd
- [root@etcd system]# id etcd
- uid=991(etcd) gid=990(etcd) groups=990(etcd)
创建启动文件:/usr/lib/systemd/system/etcd.service
- [Unit]
- Description=Etcd Server
- After=network.target
- After=network-online.target
- Wants=network-online.target
-
- [Service]
- Type=notify
- WorkingDirectory=/var/lib/etcd/
- EnvironmentFile=-/etc/etcd/etcd.conf
- User=etcd
- # set GOMAXPROCS to number of processors
- ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /usr/bin/etcd --name=\"${ETCD_NAME}\" --data-dir=\"${ETCD_DATA_DIR}\" --listen-client-urls=\"${ETCD_LISTEN_CLIENT_URLS}\""
- Restart=on-failure
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
创建启动文件中用到的目录,这个是根据rpm包的思路操作:
- mkdir -p /etc/etcd
- mkdir -p /var/lib/etcd
- chown -R etcd.etcd /var/lib/etcd
启动服务,并检查状态:
- systemctl start etcd
- systemctl enable etcd
-
- #检查健康状态:
- [root@etcd system]# etcdctl -C http://etcd:2379 cluster-health
- member 8e9e05c52164694d is healthy: got healthy result from http://10.0.10.11:2379
- cluster is healthy
配置Master节点:
Master节点上只需要运行这几个服务:apiserver、controller-manager、scheduler
直接解压文件并复制到系统路径下,如果不这样做就添加环境变量 。
- tar xf kubernetes-server-linux-amd64.tar.gz
- cd kubernetes/server/bin
-
- 复制执行文件到/usr/bin目录下:
- find ./ -perm 750|xargs chmod 755
- find ./ -perm 750|xargs -i cp {} /usr/bin/
查检kubernetes版本:
- [root@k8s-master bin]# kubectl version
- Client Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.0", GitCommit:"925c127ec6b946659ad0fd596fa959be43f0cc05", GitTreeState:"clean", BuildDate:"2017-12-15T21:07:38Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}
- The connection to the server localhost:8080 was refused - did you specify the right host or port?
把下面几个启动文件添加到系统以下目录下:/usr/lib/systemd/system/
启动文件:kube-apiserver.service
- [Unit]
- Description=Kubernetes API Server
- Documentation=https://github.com/GoogleCloudPlatform/kubernetes
- After=network.target
- After=etcd.service
-
- [Service]
- EnvironmentFile=-/etc/kubernetes/config
- EnvironmentFile=-/etc/kubernetes/apiserver
- User=kube
- ExecStart=/usr/bin/kube-apiserver \
- $KUBE_LOGTOSTDERR \
- $KUBE_LOG_LEVEL \
- $KUBE_ETCD_SERVERS \
- $KUBE_API_ADDRESS \
- $KUBE_API_PORT \
- $KUBELET_PORT \
- $KUBE_ALLOW_PRIV \
- $KUBE_SERVICE_ADDRESSES \
- $KUBE_ADMISSION_CONTROL \
- $KUBE_API_ARGS
- Restart=on-failure
- Type=notify
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
启动文件:kube-controller-manager.service
- kube-controller-manager.service
-
- [Unit]
- Description=Kubernetes Controller Manager
- Documentation=https://github.com/GoogleCloudPlatform/kubernetes
-
- [Service]
- EnvironmentFile=-/etc/kubernetes/config
- EnvironmentFile=-/etc/kubernetes/controller-manager
- User=kube
- ExecStart=/usr/bin/kube-controller-manager \
- $KUBE_LOGTOSTDERR \
- $KUBE_LOG_LEVEL \
- $KUBE_MASTER \
- $KUBE_CONTROLLER_MANAGER_ARGS
- Restart=on-failure
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
启动文件:kube-scheduler.service
- [Unit]
- Description=Kubernetes Scheduler Plugin
- Documentation=https://github.com/GoogleCloudPlatform/kubernetes
-
- [Service]
- EnvironmentFile=-/etc/kubernetes/config
- EnvironmentFile=-/etc/kubernetes/scheduler
- User=kube
- ExecStart=/usr/bin/kube-scheduler \
- $KUBE_LOGTOSTDERR \
- $KUBE_LOG_LEVEL \
- $KUBE_MASTER \
- $KUBE_SCHEDULER_ARGS
- Restart=on-failure
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
添加用户和组:只要系统ID不存在的就可以了
- groupadd -g 992 kube
- useradd -s /sbin/nologin -M -c "kube user" -u 996 kube -g kube
创建相应的目录,并授权权限:
- mkdir -p /etc/kubernetes
- #mkdir -p /var/run/kubernetes
- mkdir -p /usr/libexec/kubernetes
- #chown -R kube.kube /var/run/kubernetes/ #被下面的方法替换了
- chown -R kube.kube /usr/libexec/kubernetes
2018-02-01补充:由于kube-apiserver启动的时候会在/var/run/kubernetes下自动创建apiserver.crt 和apiserver.key两个文件,因为此目录默认不存在的而上面手工创建后,Node节点重启过系统 的话就要丢失,导致kube-apiserver启动失败,日志如下:
- Feb 1 08:45:58 k8s-master kube-apiserver: error creating self-signed certificates: mkdir /var/run/kubernetes: permission denied
所以解决方法就是:进入/usr/lib/tmpfiles.d/创建一个配置文件,这里文件会在系统启动的时候自动执行。
- [root@k8s-master ~]# cd /usr/lib/tmpfiles.d/
-
- [root@k8s-master tmpfiles.d]# cat kubernetes.conf
- d /var/run/kubernetes 0755 kube kube -
启动服务:
- for service in kube-apiserver kube-controller-manager kube-scheduler;do systemctl restart $service && systemctl enable $service ;done
Node节点安装
node节点上跑的服务就这 几个:kubelet,kube-proxy
直接把master上的几个执行文件传到Node节点的/usr/bin目录下:
- scp kube-proxy kubelet k8s-node1:/usr/bin/
- scp kube-proxy kubelet k8s-node2:/usr/bin/
添加用户和组:只要系统不存在的就可以了
- groupadd -g 992 kube
- useradd -s /sbin/nologin -M -c "kube user" -u 996 kube -g kube
创建相应的目录:
- mkdir -p /etc/kubernetes
- mkdir -p /var/run/kubernetes
- chown -R kube.kube /var/run/kubernetes/
- mkdir -p /var/lib/kubelet
- chown -R kube.kube /var/lib/kubelet
- mkdir -p /usr/libexec/kubernetes
- chown -R kube.kube /usr/libexec/kubernetes
-
添加启动文件:kubelet.service
- [Unit]
- Description=Kubernetes Kubelet Server
- Documentation=https://github.com/GoogleCloudPlatform/kubernetes
- After=docker.service
- Requires=docker.service
-
- [Service]
- WorkingDirectory=/var/lib/kubelet
- EnvironmentFile=-/etc/kubernetes/config
- EnvironmentFile=-/etc/kubernetes/kubelet
- ExecStart=/usr/bin/kubelet \
- $KUBE_LOGTOSTDERR \
- $KUBE_LOG_LEVEL \
- $KUBELET_API_SERVER \
- $KUBELET_ADDRESS \
- $KUBELET_PORT \
- $KUBELET_HOSTNAME \
- $KUBE_ALLOW_PRIV \
- $KUBELET_POD_INFRA_CONTAINER \
- $KUBELET_ARGS
- Restart=on-failure
-
- [Install]
- WantedBy=multi-user.target
添加启动文件:kube-proxy.service
- [Unit]
- Description=Kubernetes Kube-Proxy Server
- Documentation=https://github.com/GoogleCloudPlatform/kubernetes
- After=network.target
-
- [Service]
- EnvironmentFile=-/etc/kubernetes/config
- EnvironmentFile=-/etc/kubernetes/proxy
- ExecStart=/usr/bin/kube-proxy \
- $KUBE_LOGTOSTDERR \
- $KUBE_LOG_LEVEL \
- $KUBE_MASTER \
- $KUBE_PROXY_ARGS
- Restart=on-failure
- LimitNOFILE=65536
-
- [Install]
- WantedBy=multi-user.target
添加配置文件到/etc/kubernetes目录下:
config
- [root@k8s-node2 kubernetes]# egrep -v "^$|^#" config
- KUBE_LOGTOSTDERR="--logtostderr=true"
- KUBE_LOG_LEVEL="--v=0"
- KUBE_ALLOW_PRIV="--allow-privileged=false"
- KUBE_MASTER="--master=http://k8s-master:8080"
proxy,没什么内容,但是要文件存在。
- [root@k8s-node2 kubernetes]# egrep -v "^$|^#" proxy
- KUBE_PROXY_ARGS=""
kubelet
- [root@k8s-node2 kubernetes]# egrep -v "^$|^#" kubelet
- KUBELET_HOSTNAME="--hostname-override=k8s-node2"
- KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=reg.docker.tb/harbor/pod-infrastructure:latest"
- KUBELET_ARGS="--enable-server=true --enable-debugging-handlers=true --fail-s
- wap-on=false --kubecOnfig=/var/lib/kubelet/kubeconfig"
这里需要注意的,如果机器开启了swap分区的话,kubernetes会无法启动,需要关闭。
然后还要添加一个配置文件,因为1.9.0在kubelet里不再使用KUBELET_API_SERVER来跟API通信,而是通过别一个yaml的配置来实现。
- [root@k8s-node2 kubernetes]# cat /var/lib/kubelet/kubeconfig
- apiVersion: v1
- kind: Config
- users:
- - name: kubelet
- clusters:
- - name: kubernetes
- cluster:
- server: http://k8s-master:8080
- contexts:
- - context:
- cluster: kubernetes
- user: kubelet
- name: service-account-context
- current-context: service-account-context
添加后注意授权,不然会报没权限:
- chown -R kube.kube /var/lib/kubelet/
Node节点上安装docker-1.12.6
- 安装epel源:
- rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
-
- yum install docker -y
修改docker的配置文件,加入私有仓库:/etc/sysconfig/docker
- INSECURE_REGISTRY="--insecure-registry reg.docker.tb"
因为docker默认使用的
这里只要修改docker跟kubernetes一样即可。/usr/lib/systemd/system/docker.service
- --exec-opt native.cgroupdriver=cgroupfs \
启动docker服务,登陆验证:
- 启动docker服务,登陆验证:
- [root@k8s-node2 kubernetes]# docker login reg.docker.tb
- Username : upload
- Password:
- Login Succeeded
如果多个Node节点怎么办?可以直接把文件传到每个节点上。
- [root@k8s-node2 kubernetes]# ll /root/.docker/config.json
- -rw------- 1 root root 154 Jan 30 17:29 /root/.docker/config.json
启动kubelet 、kube-proxy服务
- for service in kube-proxy kubelet docker;do systemctl start $service && systemctl enable $service;done
Node节点上启动时遇到的问题:
error: failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "cgroupfs" is different from docker cgroup driver: "systemd"
解决方法就是使用上面的kubelet配置:
- Environment="KUBELET_KUBECONFIG_ARGS=--kubecOnfig=/etc/kubernetes/kubelet.conf --require-kubecOnfig=true --cgroup-driver=systemd"
这是因为docker 使用的cgroup-driver跟kubernetes的不一样,所以就会报异常。
异常提示: factory.go:340] devicemapper filesystem stats will not be reported: RHEL/Centos 7.x kernel version 3.10.0-366 or later is required to use thin_ls - you have "3.10.0-327.el7.x86_64"
k8s 1.9.0版本在使用内核方面要求3.10.366以上,如果要升级内核可以使用以下方法:
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm;yum --enablerepo=elrepo-kernel install kernel-lt-devel kernel-lt -y
安装完后可以查看是否默认为新的内核:
- [root@k8s-node2 kubernetes]# egrep ^menu /etc/grub2.cfg|cut -f 2 -d \'
- CentOS Linux (4.4.113-1.el7.elrepo.x86_64) 7 (Core)
- CentOS Linux (3.10.0-327.el7.x86_64) 7 (Core)
- CentOS Linux (0-rescue-8a1328ef9a7247f09fe7bedb9a9d95c0) 7 (Core)
设置新内核为默认选项:
- grub2-set-default 'CentOS Linux (4.4.113-1.el7.elrepo.x86_64) 7 (Core)'
核对结果:
[root@k8s-node2 kubernetes]# grub2-editenv list
saved_entry=CentOS Linux (4.4.113-1.el7.elrepo.x86_64) 7 (Core)
最后把etcd,master,和Node节点都启动,在master节点上检查一下效果。
- 返回以下结果说明跟etcd的通信正常:
-
- [root@k8s-master system]# kubectl get cs
- NAME STATUS MESSAGE ERROR
- scheduler Healthy ok
- controller-manager Healthy ok
- etcd-0 Healthy {"health": "true"}
- 返回以下结果说明两个Node节点跟Master,etcd通信正常,因为节点上的配置信息数据都是存储在etcd服务上的。
-
- [root@k8s-master system]# kubectl get node
- NAME STATUS ROLES AGE VERSION
- k8s-node1 Ready <none> 5h v1.9.0
- k8s-node2 Ready <none> 5h v1.9.0
创建一个yaml测试文件,现在两个node节点上都没有任何镜像,一会直接创建会自动去我指定的仓库里下载。
nginx-rc.yaml
- apiVersion: v1
- kind: ReplicationController
- metadata:
- name: nginx-rc
- spec:
- replicas: 2
- selector:
- app: nginx
- template:
- metadata:
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: reg.docker.tb/harbor/nginx
- ports:
- - containerPort: 80
在等待一会后,下载完镜像就可以看到效果了。
第一个就是pod基础包,我把它下载回来并打上tag上传到自己的仓库里了。
在master节点上可以看到刚才创建的rc共创建两个容器,现在已经启动了一个,因为我使用的笔记本走wifi比较慢。
- [root@k8s-master yaml]# kubectl get po
- NAME READY STATUS RESTARTS AGE
- nginx-rc-74s85 1/1 Running 0 8m
- nginx-rc-kc5tx 0/1 ContainerCreating 0 8m
这里要注意一下kubernetes与docker的版本支持,之前我还是使用docker-ce最新版的,发现有问题,就比如网络不通。
安装flannel网络插件
首先在etcd服务器上添加一个网络配置,这个网络配置自己随意只要在flannl的配置里一样即可。
- etcdctl set /atomic.io/network/config '{ "Network": "172.21.0.0/16" }'
为了 方便管理,在Master节点上也安装上flannl插件,就是除了这个etcd服务器上不安装,其它的都安装上。
下载地址:https://github.com/coreos/flannel/releases/download/v0.9.0/flannel-v0.9.0-linux-amd64.tar.gz
- tar xf flannel-v0.9.0-linux-amd64.tar.gz
-
- 传到每个机器上:
- scp flanneld k8s-node1:/usr/bin/
- scp flanneld k8s-node2:/usr/bin/
-
- #每个机器上创建一个目录:
- mkdir -p /usr/libexec/flannel
-
- scp mk-docker-opts.sh k8s-node1:/usr/libexec/flannel
- scp mk-docker-opts.sh k8s-node2:/usr/libexec/flannel
添加一个启动文件:要看启动文件中的目录,如果不存在就创建,并授权。
- [Unit]
- Description=Flanneld overlay address etcd agent
- After=network.target
- After=network-online.target
- Wants=network-online.target
- After=etcd.service
- Before=docker.service
-
- [Service]
- Type=notify
- EnvironmentFile=/etc/sysconfig/flanneld
- EnvironmentFile=-/etc/sysconfig/docker-network
- ExecStart=/usr/bin/flanneld-start $FLANNEL_OPTIONS
- ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker
- Restart=on-failure
-
- [Install]
- WantedBy=multi-user.target
- RequiredBy=docker.service
还要手工添加个shell文件:flanneld-start
- #!/bin/sh
-
- exec /usr/bin/flanneld \
- -etcd-endpoints=${FLANNEL_ETCD_ENDPOINTS:-${FLANNEL_ETCD}} \
- -etcd-prefix=${FLANNEL_ETCD_PREFIX:-${FLANNEL_ETCD_KEY}} \
- "$@"
需要可执行权限:
- chmod 755 /usr/bin/flanneld-start
然后启动服务。
再尝试一个下效果:添加一个srevice.yaml
- apiVersion: v1
- kind: Service
- metadata:
- name: nginx-service
- spec:
- type: NodePort
- ports:
- - port: 8000
- targetPort: 80
- protocol: TCP
- selector:
- app: nginx
这里可以看到type类型为NodePort,就是这个31603端口会在每个容器运行的宿主机上映射一个对外的端口,通过宿主机IP和端口即可访问上面创建的nginx服务。
- [root@k8s-master yaml]# kubectl get service
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
- kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 1d
- nginx-service NodePort 10.254.72.166 <none> 8000:31603/TCP 37m
- [root@k8s-master yaml]# kubectl get po -o wide
- NAME READY STATUS RESTARTS AGE IP NODE
- nginx-rc-r6cnh 1/1 Running 0 45m 172.21.8.2 k8s-node2
- nginx-rc-wp2hk 1/1 Running 0 45m 172.21.2.2 k8s-node1
而CLUSTER-IP就是集群的IP入口,但是它只允许有容器运行在集群内的宿主机连接。



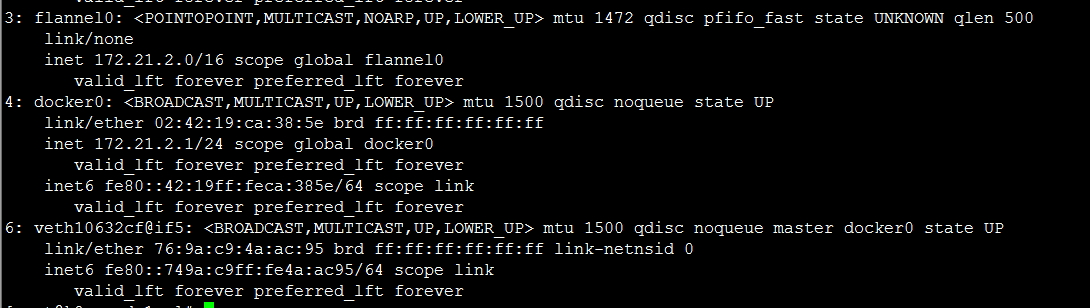





![Kubernetes 1.9.0 Alpha.1 发布公告 [Kubernetes 最新动态]](https://img1.php1.cn/3cd4a/25047/ae9/3397348f4961686e.png)

 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有