作者:余夫子曰 | 来源:互联网 | 2023-08-29 14:40
先一个一个java程序,读取日志文件中的数据,然后将数据写入到Kafka中,然后写一个SparkSteaming程序,使用直连的方式读取Kafka中的数据,计算如下指标该文件是一个
先一个一个java程序,读取日志文件中的数据,然后将数据写入到Kafka中,然后写一个SparkSteaming程序,使用直连的方式读取Kafka中的数据,计算如下指标
该文件是一个电商网站某一天用户购买商品的订单成交数据,每一行有多个字段,用空格分割,字段的含义如下
用户ID ip地址 商品分类 购买明细 商品金额
A 202.106.196.115 手机 iPhone8 8000
0 1 2 3 4
A 202.106.196.115 手机 iPhone8 8000
B 202.106.0.20 服装 布莱奥尼西服 199
C 202.102.152.3 家具 婴儿床 2000
D 202.96.96.68 家电 电饭锅 1000
F 202.98.0.68 化妆品 迪奥香水 200
H 202.96.75.68 食品 奶粉 600
J 202.97.229.133 图书 Hadoop编程指南 90
A 202.106.196.115 手机 手机壳 200
B 202.106.0.20 手机 iPhone8 8000
C 202.102.152.3 家具 婴儿车 2000
D 202.96.96.68 家具 婴儿车 1000
F 202.98.0.68 化妆品 迪奥香水 200
H 202.96.75.68 食品 婴儿床 600
J 202.97.229.133 图书 spark实战 80
问题1.计算出各个省的成交量总额(结果保存到MySQL中)
问题2.计算每个省城市成交量的top3(结果保存到MySQL中)
问题3.计算每个商品分类的成交总额,并按照从高到低排序(结果保存到MySQL中)
问题4.构建每一个用户的用户画像,就是根据用户购买的具体商品,给用户打上一个标签,为将来的商品推荐系统作数据支撑
说明:如果一个用户购买了一个iPhone8,对应有多个标签:果粉、高端人士、数码一族
请将下面的规则数据保存到MySQL数据库中,并作为标签规则(三个字段分别代表id、商品、对于的标签):
1 iPhone8 果粉
2 iPhone8 高端人士
3 iPhone8 数码一族
4 布莱奥尼西服 高端人士
5 布莱奥尼西服 商务男士
6 婴儿床 育儿中
7 迪奥香水 高端人士
8 迪奥香水 白富美
9 婴儿床 育儿中
10 iPhone8手机壳 果粉
11 iPhone8手机壳 高端人士
12 iPhone8手机壳 数码一族
13 spark实战 IT人士
14 spark实战 屌丝
15 Hadoop编程指南 IT人士
16 Hadoop编程指南 屌丝
用户的行为数据,根据规则打上对应的标签,然后将数据存储到Hbase中,并说明Hbase的注解和列族的设计思想!
由于用户的行为过多,计算过程要对数据进行序列化的压缩,要求使用kryo这种序列化机制,压缩方式自己选择
object OrderCount {
def main(args: Array[String]): Unit = {
val group = "g1"
val cOnf= new SparkConf().setAppName("OrderCount").setMaster("local[4]")
val ssc = new StreamingContext(conf, Duration(5000))
val broadcastRef = IPUtils.broadcastIpRules(ssc, "/ip/ip.txt")
val topic = "orders"
val brokerList = "lj01:9092,lj02:9092,lj03:9092"
val zkQuorum = "lj01:2181,lj02:2181,lj03:2181"
val topics: Set[String] = Set(topic)
val topicDirs = new ZKGroupTopicDirs(group, topic)
val zkTopicPath = s"${topicDirs.consumerOffsetDir}"
val kafkaParams = Map(
"metadata.broker.list" -> brokerList,
"group.id" -> group,
"auto.offset.reset" -> kafka.api.OffsetRequest.SmallestTimeString
)
val zkClient = new ZkClient(zkQuorum)
val children = zkClient.countChildren(zkTopicPath)
var kafkaStream: InputDStream[(String, String)] = null
var fromOffsets: Map[TopicAndPartition, Long] = Map()
//如果保存过 offset
//注意:偏移量的查询是在Driver完成的
if (children > 0) {
for (i <- 0 until children) {
val partitiOnOffset= zkClient.readData[String](s"$zkTopicPath/${i}")
val tp = TopicAndPartition(topic, i)
fromOffsets += (tp -> partitionOffset.toLong)
}
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.key(), mmd.message())
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
} else {
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
}
var offsetRanges = Array[OffsetRange]()
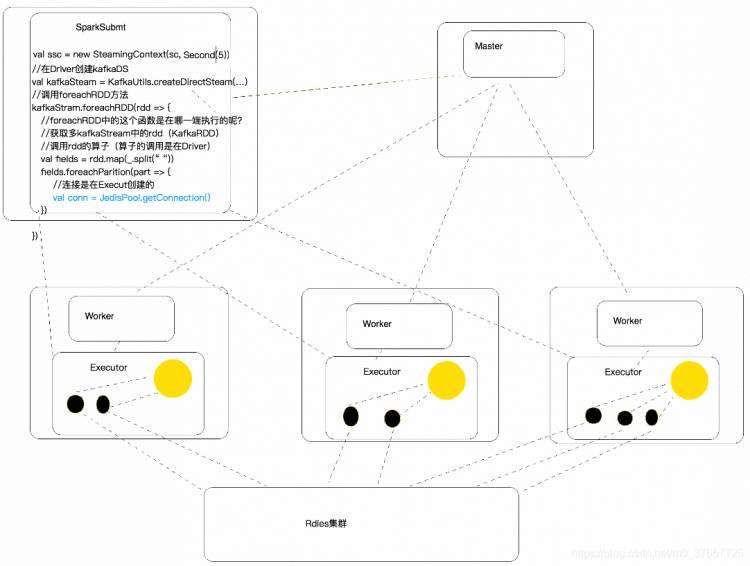
//kafkaStream.foreachRDD里面的业务逻辑是在Driver端执行,RDD在Driver端生成,RDD调算子,算子里得函数的执行是在Executor
kafkaStream.foreachRDD { kafkaRDD =>
if(!kafkaRDD.isEmpty()) {
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val lines: RDD[String] = kafkaRDD.map(_._2)
//整理数据
val fields: RDD[Array[String]] = lines.map(_.split(" "))
//计算成交总金额
CalculateUtil.calculateIncome(fields)
//计算商品分类金额
CalculateUtil.calculateItem(fields)
//计算区域成交金额
CalculateUtil.calculateZone(fields, broadcastRef) for (o <- offsetRanges) {
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
ZkUtils.updatePersistentPath(zkClient, zkPath, o.untilOffset.toString)
}
}
}
ssc.start()
ssc.awaitTermination()
}
}
实现要在redis设置一个key,变量
object Constant {
val TOTAL_INCOME = "TOTAL_INCOME"
}
工具类CalculateUtil
object CalculateUtil {
//计算成交总金额
def calculateIncome(fields: RDD[Array[String]]) = {
//将数据计算后写入到Reids
val priceRDD: RDD[Double] = fields.map(arr => {
val price = arr(4).toDouble
price
})
//reduce是一个Action,会把结果返回到Driver端
//将当前批次的总金额返回了
val sum: Double = priceRDD.reduce(_+_)
//获取一个jedis连接
val cOnn= JedisConnectionPool.getConnection()
//将历史值和当前的值进行累加
conn.incrByFloat(Constant.TOTAL_INCOME, sum)
//释放连接
conn.close()
}
// 计算分类的成交金额
def calculateItem(fields: RDD[Array[String]]) = {
val itemAndPrice: RDD[(String, Double)] = fields.map(arr => {
//分类
val item = arr(2)
//金额
val parice = arr(4).toDouble
(item, parice)
})
//按商品分类进行聚合
val reduced: RDD[(String, Double)] = itemAndPrice.reduceByKey(_+_)
//将当前批次的数据累加到Redis中
//foreachPartition是一个Action
//现在这种方式,jeids的连接是在哪一端创建的(Driver)
//在Driver端拿Jedis连接不好
reduced.foreachPartition(part => {
//获取一个Jedis连接
//这个连接其实是在Executor中的获取的
//JedisConnectionPool在一个Executor进程中有几个实例(单例)
val cOnn= JedisConnectionPool.getConnection()
part.foreach(t => {
//一个连接更新多条数据
conn.incrByFloat(t._1, t._2)
})
//将当前分区中的数据跟新完在关闭连接
conn.close()
})
}
//根据Ip计算归属地
def calculateZone(fields: RDD[Array[String]], broadcastRef: Broadcast[Array[(Long, Long, String)]]) = {
val provinceAndPrice: RDD[(String, Double)] = fields.map(arr => {
val ip = arr(1)
val price = arr(4).toDouble
val ipNum = MyUtils.ip2Long(ip)
//在Executor中获取到广播的全部规则
val allRules: Array[(Long, Long, String)] = broadcastRef.value
//二分法查找
val index = MyUtils.binarySearch(allRules, ipNum)
var province = "未知"
if (index != -1) {
province = allRules(index)._3
}
//省份,订单金额
(province, price)
})
//按省份进行聚合
val reduced: RDD[(String, Double)] = provinceAndPrice.reduceByKey(_+_)
//将数据跟新到Redis
reduced.foreachPartition(part => {
val cOnn= JedisConnectionPool.getConnection()
part.foreach(t => {
conn.incrByFloat(t._1, t._2)
})
conn.close()
})
}
}
即Myutilt
object MyUtils {
def ip2Long(ip: String): LOng= {
val fragments = ip.split("[.]")
var ipNum = 0L
for (i <- 0 until fragments.length){
ipNum = fragments(i).toLong | ipNum <<8L
}
ipNum
}
def readRules(path: String): Array[(Long, Long, String)] = {
//读取ip规则
val bf: BufferedSource = Source.fromFile(path)
val lines: Iterator[String] = bf.getLines()
//对ip规则进行整理,并放入到内存
val rules: Array[(Long, Long, String)] = lines.map(line => {
val fileds = line.split("[|]")
val startNum = fileds(2).toLong
val endNum = fileds(3).toLong
val province = fileds(6)
(startNum, endNum, province)
}).toArray
rules
}
def binarySearch(lines: Array[(Long, Long, String)], ip: Long) : Int = {
var low = 0
var high = lines.length - 1
while (low <= high) {
val middle = (low + high) / 2
if ((ip >= lines(middle)._1) && (ip <= lines(middle)._2))
return middle
if (ip high = middle - 1
else {
low = middle + 1
}
}
-1
}
def data2MySQL(it: Iterator[(String, Int)]): Unit = {
//一个迭代器代表一个分区,分区中有多条数据
//先获得一个JDBC连接
val conn: COnnection= DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123568")
//将数据通过Connection写入到数据库
val pstm: PreparedStatement = conn.prepareStatement("INSERT INTO access_log VALUES (?, ?)")
//将分区中的数据一条一条写入到MySQL中
it.foreach(tp => {
pstm.setString(1, tp._1)
pstm.setInt(2, tp._2)
pstm.executeUpdate()
})
//将分区中的数据全部写完之后,在关闭连接
if(pstm != null) {
pstm.close()
}
if (conn != null) {
conn.close()
}
}
def main(args: Array[String]): Unit = {
//数据是在内存中
val rules: Array[(Long, Long, String)] = readRules("/Users/zx/Desktop/ip/ip.txt")
//将ip地址转换成十进制
val ipNum = ip2Long("114.215.43.42")
//查找
val index = binarySearch(rules, ipNum)
//根据脚本到rules中查找对应的数据
val tp = rules(index)
val province = tp._3
println(province)
}
}






 京公网安备 11010802041100号
京公网安备 11010802041100号