回复“书籍”即可获赠Python从入门到进阶共10本电子书
导读:从2014年开源到现在,Flink已经发展成一套非常成熟的大数据处理引擎,同时被很多公司作为流数据处理平台的底层技术。本文为大家介绍Flink的架构及其组成成分。
Flink系统架构主要分为APIs & Libraries、Core和Deploy三层,如图1所示,其中APIs层主要实现了面向流处理对应的DataStream API,面向批处理对应的DataSet API。Libraries层也被称作Flink应用组件层,是根据API层的划分,在API层之上构建满足了特定应用领域的计算框架,分别对应了面向流处理和面向批处理两类,其中面向流处理支持CEP(复杂事件处理)、基于类似SQL的操作(基于Table的关系操作);面向批处理支持Flink ML(机器学习库)、Gelly(图处理)。运行时层提供了Flink计算的全部核心实现,例如支持分布式Stream作业执行、JobGraph到ExecutionGraph的映射和调度等,为API层提供了基础服务。Deploy层支持多种部署模式,包括本地、集群(Standalone、YARN、Kubernetes)及云部署(GCE/EC2)。
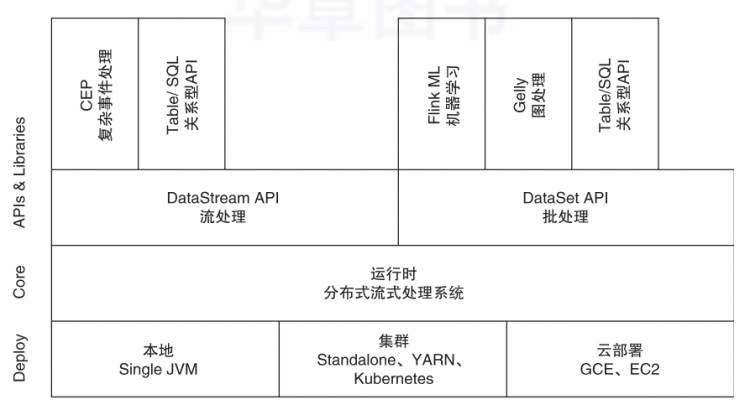
图1 Flink整体架构
1、编程接口
Flink提供了多种抽象的编程接口,适用于不同层级的用户。数据分析人员和偏向业务的数据开发人员可以使用Flink SQL定义流式作业。如图2所示,Flink编程接口分为4层。
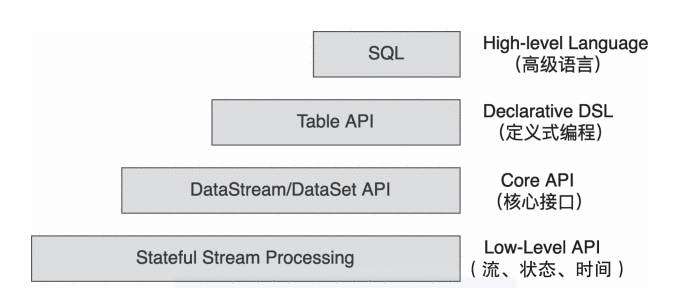
图2 Flink编程接口抽象
一项大数据技术如果想被用户接受和使用,除了应具有先进的架构理念之外,另一点非常重要的就是要具有非常好的易用性。我们知道虽然Pig中的操作更加灵活和高效,但是在都满足数据处理需求的前提下,数据开发者更愿意选择Hive作为大数据处理的开发工具。其中最重要的原因是,Hive能够基于SQL标准进行拓展,提出了HQL语言,这就让很多只会SQL的用户也能够快速掌握大数据处理技术。因此Hive技术很快得到普及。
对于Flink同样如此,如果想赢得更多的用户,就必须不断增强易用性。FlinkSQL基于关系型概念构建流式和离线处理应用,使用户能够更加简单地通过SQL构建Flink作业。
Flink SQL解析生成逻辑执行计划和物理执行计划,然后转换为Table之间的操作,最终转换为JobGraph并运行在集群上。Table API和Spark中的DataSet/DataFrame接口类似,都提供了面向领域语言的编程接口。相比Flink SQL,Table API更加灵活,既可以在Java & Scala SDK中与DataStream和DataSet API相互转换,也能结合Flink SQL进行数据处理。
在早期的Flink版本中,DataSet API和DataStream API分别用于流处理和批处理场景。DataSet用于处理离线数据集,DataStream用于处理流数据集。DataFlow模型希望使用同一套流处理框架统一处理有界和无界数据,那么为什么Flink还要抽象出两套编程接口来处理有界数据集和无界数据集呢?这也是近年来Flink社区不断探讨的话题。目前Table和SQL API层面虽然已经能够做到批流一体,但这仅是在逻辑层面上的,最终还是会转换成DataSet API和DataStream API对应的作业。后期Flink社区将逐渐通过DataStream处理有界数据集和无界数据集,社区已经在1.11版本中对DataStream API中的SourceFunction接口进行了重构,使DataStream可以接入和处理有界数据集。在后期的版本中,Flink将逐步实现真正意义上的批流一体化。
Stateful Processing Function接口
Stateful Processing Function接口提供了强大且灵活的编程能力,在其中可以直接操作状态数据、TimeService等服务,同时可以注册事件时间和处理时间回调定时器,使程序能够实现更加复杂的计算。使用Stateful Processing Function接口需要借助DataStream API。虽然Stateful Processing Function接口灵活度很高,但是接口使用复杂度也相对较高,且在DataStream API中已经基于Stateful Process Function接口封装了非常丰富的算子,这些算子可以直接使用,因此,除非用户需要自定义比较复杂的算子(如直接操作状态数据等),否则无须使用Stateful Processing Function接口开发Flink作业。
2、运行时执行引擎
用户使用组件栈和接口编写的Flink作业最终都会在客户端转换成JobGraph对象,然后提交到集群中运行。除了任务的提交和运行之外,运行时还包含资源管理器Resource-Manager以及负责接收和执行Task的TaskManager,这些服务各司其职,相互合作。运行时提供了不同类型(有界和无界)作业的执行和调度功能,最终将任务拆解成Task执行和调度。同时,运行时兼容了不同类型的集群资源管理器,可以提供不同的部署方式,并统一管理Slot计算资源。
3、物理部署层
物理部署层的主要功能是兼容不同的资源管理器,如支持集群部署模式的Hadoop YARN、Kubernetes及Standalone等。这些资源管理器能够为在Flink运行时上运行的作业提供Slot计算资源。第4章会重点介绍Flink物理部署层的实现,帮助大家了解如何将运行时运行在不同的资源管理器上并对资源管理器提供的计算资源进行有效管理。
如图3所示,Flink集群主要包含3部分:JobManager、TaskManager和客户端,三者均为独立的JVM进程。Flink集群启动后,会至少启动一个JobManager和多个Task-Manager。客户端将任务提交到JobManager,JobManager再将任务拆分成Task并调度到各个TaskManager中执行,最后TaskManager将Task执行的情况汇报给JobManager。
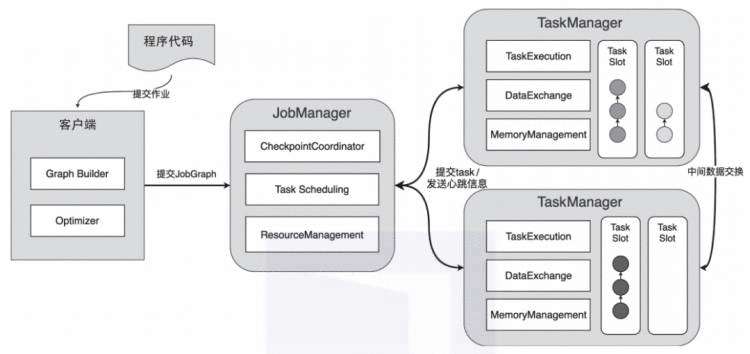
图3 Flink集群架构图
客户端是Flink专门用于提交任务的客户端实现,可以运行在任何设备上,并且兼容Windows、macOS、Linux等操作系统,只需要运行环境与JobManager之间保持网络畅通即可。用户可以通过./bin/f?link run命令或Scala Shell交互式命令行提交作业。客户端会在内部运行提交的作业,然后基于作业的代码逻辑构建JobGraph结构,最终将JobGraph提交到运行时中运行。JobGraph是客户端和集群运行时之间约定的统一抽象数据结构,也就是说,不管是什么类型的作业,都会通过客户端将提交的应用程序构建成JobGraph结构,最后提交到集群上运行。
JobManager是整个集群的管理节点,负责接收和执行来自客户端提交的JobGraph。JobManager也会负责整个任务的Checkpoint协调工作,内部负责协调和调度提交的任务,并将JobGraph转换为ExecutionGraph结构,然后通过调度器调度并执行ExecutionGraph的节点。ExecutionGraph中的ExecutionVertex节点会以Task的形式在TaskManager中执行。
除了对Job的调度和管理之外,JobManager会对整个集群的计算资源进行统一管理,所有TaskManager的计算资源都会注册到JobManager节点中,然后分配给不同的任务使用。当然,JobManager还具备非常多的功能,例如Checkpoint的触发和协调等。
TaskManager作为整个集群的工作节点,主要作用是向集群提供计算资源,每个TaskManager都包含一定数量的内存、CPU等计算资源。这些计算资源会被封装成Slot资源卡槽,然后通过主节点中的ResourceManager组件进行统一协调和管理,而任务中并行的Task会被分配到Slot计算资源中。
根据底层集群资源管理器的不同,TaskManager的启动方式及资源管理形式也会有所不同。例如,在基于Standalone模式的集群中,所有的TaskManager都是按照固定数量启动的;而YARN、Kubernetes等资源管理器上创建的Flink集群则支持按需动态启动TaskManager节点。
1、有状态计算
在Flink架构体系中,有状态计算是非常重要的特性之一。如图4所示,有状态计算是指在程序计算过程中,程序内部存储计算产生的中间结果,并将其提供给后续的算子进行计算。状态数据可以存储在本地内存中,也可以存储在第三方存储介质中,例如Flink已经实现的RocksDB。
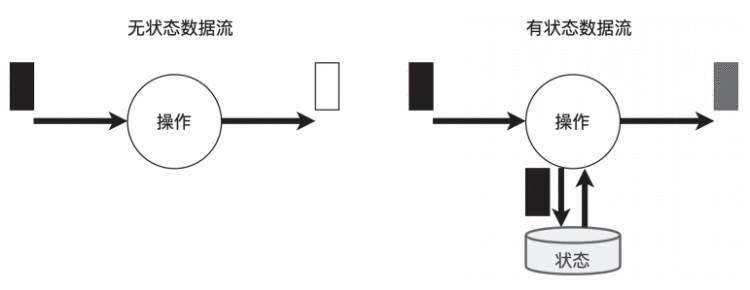
图4 有状态处理和无状态处理
和有状态计算不同,无状态计算不会存储计算过程中产生的结果,也不会将结果用于下一步计算。程序只会在当前的计算流程中执行,计算完成就输出结果,然后接入下一条数据,继续处理。
无状态计算实现的复杂度相对较低,实现起来也比较容易,但是无法应对比较复杂的业务场景,例如处理实时CEP问题,按分钟、小时、天进行聚合计算,求取最大值、均值等聚合指标等。如果不借助Flink内部提供的状态存储,一般都需要通过外部数据存储介质,常见的有Redis等键值存储系统,才能完成复杂指标的计算。
和Storm等流处理框架不同,Flink支持有状态计算,可以应对更加复杂的数据计算场景。
2、时间概念与水位线机制
在DataFlow模型中,时间会被分为事件时间和处理时间两种类型。如图5所示,Flink中的时间概念基本和DataFlow模型一致,且Flink在以上两种时间概念的基础上增加了进入时间(ingestion time)的概念,也就是数据接入到Flink系统时由源节点产生的时间。
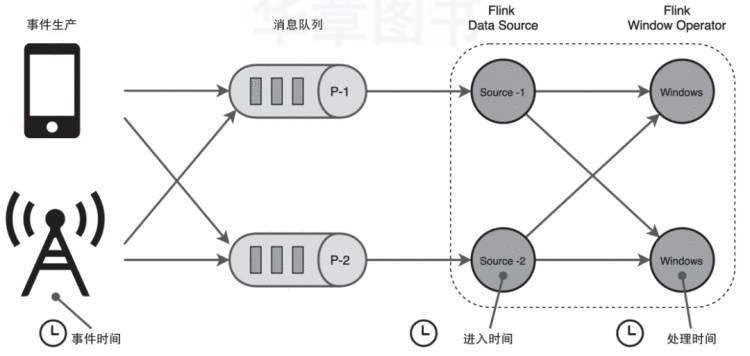
图5 Flink时间概念
事件时间指的是每个事件在其生产设备上发生的时间。通常在进入Flink之前,事件时间就已经嵌入数据记录,后续计算从每条记录中提取该时间。基于事件时间,我们可以通过水位线对乱序事件进行处理。事件时间能够准确地反映事件发生的先后关系,这对流处理系统而言是非常重要的。在涉及较多的网络传输时,在传输过程中不可避免地会发生数据发送顺序改变,最终导致流系统统计结果出现偏差,从而很难通过实时计算的方式得到正确的统计结果。
处理时间是指执行相应算子操作的机器系统时间。当应用基于处理时间运行时,所有基于时间的算子操作(如时间窗口)将使用运行相应算子机器的系统时钟。例如,应用程序在上午9:15运行,则第一个每小时处理时间窗口包括在上午9:15到上午10:00之间处理的事件,下一个窗口包括在上午10:00到11:00之间处理的事件。
处理时间是最简单的时间概念,不需要在流和机器之间进行协调,它提供了最佳的性能和最低的延迟。但在分布式和异步环境中,处理时间不能提供确定性,因为它容易受到记录到达系统的速度(例如从消息队列到达系统)以及系统内算子之间流动速度的影响。
接入时间是指数据接入Flink系统的时间,它由SourceOperator自动根据当前时钟生成。后面所有与时间相关的Operator算子都能够基于接入时间完成窗口统计等操作。接入时间的使用频率并不高,当接入的事件不具有事件时间时,可以借助接入时间来处理数据。
相比于处理时间,接入时间的实现成本较高,但是它的数据只产生一次,且不同窗口操作可以基于统一的时间戳,这可以在一定程度上避免处理时间过度依赖处理算子的时钟的问题。
不同于事件时间,接入时间不能完全刻画出事件产生的先后关系。在Flink内部,接入时间只是像事件时间一样对待和处理,会自动分配时间戳和生成水位线。因此,基于接入时间并不能完全处理乱序时间和迟到事件。
本文摘编于《Flink设计与实现:核心原理与源码解析》。

推荐阅读:Flink贡献者/第四范式AI数据平台架构师张利兵撰写,源码剖析Flink设计思想、架构原理以及各模块实现原理,大量架构图、UML图。
本周赠书:《Flink设计与实现:核心原理与源码解析》最后给大家推荐一个数据分析的直播,明天晚上8点,假期也记得给自己加油噢!
活动规则
参与方式:在下方公众号后台回复 “送书”关键字,记得是“送书”二字哈,即可参与本次的送书活动。
公布时间:2021年8月25号(周三)晚上20点
领取事宜:请小伙伴添加小助手微信: pycharm1314,或者扫码添加好友。添加小助手的每一个人都可以领取一份Python学习资料,更重要的是方便联系。

注意事项:一定要留意微信消息,如果你是幸运儿就尽快在小程序中填写收货地址、书籍信息。一天之内没有填写收货信息,送书名额就转给其他人了噢,欢迎参与。
------------------- End -------------------
往期精彩文章推荐:
盘点Python编程的简易版自动化工具——ADB史上全操作
手机自动化测试IDE-----Airtest实战篇
手机自动化测试IDE ----- 手把手教你用Airtest模拟器来连接手机
手机自动化测试IDE-----Airtest基本操作方法









![R语言中向量(Vector)数据类型的元素索引与访问:利用中括号[]和赋值操作符在向量末尾追加数据以扩展其长度](https://img5.php1.cn/3cdc5/92e2/2be/c2a171af6e5eeb5a.png)



 京公网安备 11010802041100号
京公网安备 11010802041100号