作者:愤然尔立_980 | 来源:互联网 | 2023-07-19 16:55
篇首语:本文由编程笔记#小编为大家整理,主要介绍了数据挖掘和机器学习的面试问题相关的知识,希望对你有一定的参考价值。
来源 | TowardsDataScience
译者 | Ray
编辑 | 磐石
在过去的几个月里,我面试了许多公司涉及数据科学和机器学习的实习岗位。介绍一下我的背景,我研究生期间的方向是机器学习,计算机视觉,并且以前大部分时间都是在研究学术,但在早期有8个月的创业经历(与ML无关)。我面试的岗位包括数据科学、传统机器学习、自然语言处理或者是计算机视觉,并且面试的都是像亚马逊、特斯拉、三星、Uber、华为这些大公司,也有许多创业公司。
今天,我将会分享所有我面试时遇到的问题,并分享如何去回答这些问题。这些问题中有些是比较正常的并且有一定的理论背景,但有一些问题则很有创新性。对于一些普通的面试题,我就简单的列一下,因为这些题在网上都很容易找到。主要深入讲解一下比较少见的面试。我希望阅读这篇文章后,能够帮助你在机器学习面试中表现的更好,并且找到你梦寐以求的工作。
让我们开始吧:
1. 如何权衡偏差和方差?
2. 什么是梯度下降?
3. 解释一下过拟合和欠拟合,如何解决这两种问题?
4. 如何处理维度灾难?
5. 什么是正则化项。为什么要使用正则化,说出一些常用的正则化方法?
6. 讲解一下PCA原理
7. 为什么在神经网络中Relu激活函数会比Sigmoid激活函数用的更多?
8. 什么是数据标准化,为什么要进行数据标准化?
我认为这个问题需要重视。数据标准化是预处理步骤,将数据标准化到一个特定的范围能够在反向传播中保证更好的收敛。一般来说,是将该值将去平均值后再除以标准差。如果不进行数据标准化,有些特征(值很大)将会对损失函数影响更大(就算这个特别大的特征只是改变了1%,但是他对损失函数的影响还是很大,并会使得其他值比较小的特征变得不重要了)。因此数据标准化可以使得每个特征的重要性更加均衡。
9. 解释什么是降维,在哪里会用到降维,它的好处是什么?
降维是指通过保留一些比较重要的特征,去除一些冗余的特征,减少数据特征的维度。而特征的重要性取决于该特征能够表达多少数据集的信息,也取决于使用什么方法进行降维。而使用哪种降维方法则是通过反复的试验和每种方法在该数据集上的效果。一般情况会先使用线性的降维方法再使用非线性的降维方法,通过结果去判断哪种方法比较合适。而降维的好处是:
(1)节省存储空间;
(2)加速计算速度(比如在机器学习算法中),维度越少,计算量越少,并且能够使用那些不适合于高维度的算法;
(3)去除一些冗余的特征,比如降维后使得数据不会既保存平方米和平方英里的表示地形大小的特征;
(4)将数据维度降到2维或者3维使之能可视化,便于观察和挖掘信息。
(5)特征太多或者太复杂会使得模型过拟合。
10. 如何处理缺失值数据?
数据中可能会有缺失值,处理的方法有两种,一种是删除整行或者整列的数据,另一种则是使用其他值去填充这些缺失值。在Pandas库,有两种很有用的函数用于处理缺失值:isnull()和dropna()函数能帮助我们找到数据中的缺失值并且删除它们。如果你想用其他值去填充这些缺失值,则可以是用fillna()函数。
11. 解释聚类算法
请参考(https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68--详细讲解各种聚类算法)
12. 你会如何进行探索性数据分析(EDA)?
EDA的目的是去挖掘数据的一些重要信息。一般情况下会从粗到细的方式进行EDA探索。一开始我们可以去探索一些全局性的信息。观察一些不平衡的数据,计算一下各个类的方差和均值。看一下前几行数据的信息,包含什么特征等信息。使用Pandas中的df.info()去了解哪些特征是连续的,离散的,它们的类型(int、float、string)。接下来,删除一些不需要的列,这些列就是那些在分析和预测的过程中没有什么用的。
比如:某些列的值很多都是相同的,或者这些列有很多缺失值。当然你也可以去用一些中位数等去填充这些缺失值。然后我们可以去做一些可视化。对于一些类别特征或者值比较少的可以使用条形图。类标和样本数的条形图。找到一些最一般的特征。对一些特征和类别的关系进行可视化去获得一些基本的信息。然后还可以可视化两个特征或三个特征之间的关系,探索特征之间的联系。
你也可以使用PCA去了解哪些特征更加重要。组合特征去探索他们的关系,比如当A=0,B=0的类别是什么,A=1,B=0呢?比较特征的不同值,比如性别特征有男女两个取值,我们可以看下男和女两种取值的样本类标会不会不一样。
另外,除了条形图、散点图等基本的画图方式外,也可以使用PDF\CDF或者覆盖图等。观察一些统计数据比如数据分布、p值等。这些分析后,最后就可以开始建模了。
一开始可以使用一些比较简单的模型比如贝叶斯模型和逻辑斯谛回归模型。如果你发现你的数据是高度非线性的,你可以使用多项式回归、决策树或者SVM等。特征选择则可以基于这些特征在EDA过程中分析的重要性。如果你的数据量很大的话也可以使用神经网络。然后观察ROC曲线、查全率和查准率。
13. 你是怎么考虑使用哪些模型的?
其实这个是有很多套路的。我写了一篇关于如何选择合适的回归模型,链接在这(https://towardsdatascience.com/selecting-the-best-machine-learning-algorithm-for-your-regression-problem-20c330bad4ef)。
14. 在图像处理中为什么要使用卷积神经网络而不是全连接网络?
这个问题是我在面试一些视觉公司的时候遇到的。答案可以分为两个方面:首先,卷积过程是考虑到图像的局部特征,能够更加准确的抽取空间特征。如果使用全连接的话,我们可能会考虑到很多不相关的信息。其次,CNN有平移不变性,因为权值共享,图像平移了,卷积核还是可以识别出来,但是全连接则做不到。
15. 是什么使得CNN具有平移不变性?
正如上面解释,每个卷积核都是一个特征探测器。所以就像我们在侦查一样东西的时候,不管物体在图像的哪个位置都能识别该物体。因为在卷积过程,我们使用卷积核在整张图片上进行滑动卷积,所以CNN具有平移不变性。
16. 为什么实现分类的CNN中需要进行Max-pooling?
Max-pooling可以将特征维度变小,使得减小计算时间,同时,不会损失太多重要的信息,因为我们是保存最大值,这个最大值可以理解为该窗口下的最重要信息。同时,Max-pooling也对CNN具有平移不变性提供了很多理论支撑,详细可以看吴恩达的benefits of MaxPooling(https://www.coursera.org/learn/convolutional-neural-networks/lecture/hELHk/pooling-layers)。
17. 为什么应用于图像切割的CNN一般都具有Encoder-Decoder架构?
Encoder CNN一般被认为是进行特征提取,而decoder部分则使用提取的特征信息并且通过decoder这些特征和将图像缩放到原始图像大小的方式去进行图像切割。
18. 什么是batch normalization,原理是什么?
Batch Normalization就是在训练过程,每一层输入加一个标准化处理。
深度神经网络之所以复杂有一个原因就是由于在训练的过程中上一层参数的更新使得每一层的输入一直在改变。所以有个办法就是去标准化每一层的输入。具体归一化的方式如下图,如果只将归一化的结果进行下一层的输入,这样可能会影响到本层学习的特征,因为可能该层学习到的特征分布可能并不是正态分布的,这样强制变成正态分布会有一定影响,所以还需要乘上γ和β,这两个参数是在训练过程学习的,这样可以保留学习到的特征。
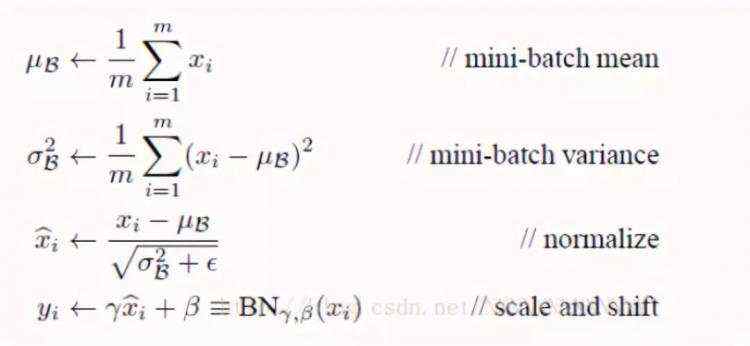
来自网络
神经网络其实就是一系列层组合成的,并且上一层的输出作为下层的输入,这意味着我们可以将神经网络的每一层都看成是以该层作为第一层的小型序列网络。这样我们在使用激活函数之前归一化该层的输出,然后将其作为下一层的输入,这样就可以解决输入一直改变的问题。
19. 为什么卷积核一般都是3*3而不是更大?
这个问题在VGGNet模型中很好的解释了。主要有这2点原因:第一,相对于用较大的卷积核,使用多个较小的卷积核可以获得相同的感受野和能获得更多的特征信息,同时使用小的卷积核参数更少,计算量更小。第二:你可以使用更多的激活函数,有更多的非线性,使得在你的CNN模型中的判决函数有更有判决性。
20. 你有一些跟机器学习相关的项目吗?
对于这个问题,你可以从你做过的研究与他们公司的业务之间的联系上作答。 你所学到的技能是否有一些可能与他们公司的业务或你申请的职位有关? 不需要是100%相吻合的,只要以某种方式相关就可以。这样有助于让他们认为你可以在这个职位上所产生的更大价值。
21. 解释一下你现在研究生期间的研究?平时都在做什么工作?未来的方向是什么?
这些问题的答案都跟20题的回答思路是一致的。

总结:
所有在我面试数据科学和机器学习岗位的时候遇到的面试题都在这里了。希望你能喜欢这篇文章并能从中学到一些新的有用的知识!
【文中所含链接】:
[1] The 5 Clustering Algorithms Data Scientists Need to Know:https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68
[2] select the proper regression model:
https://towardsdatascience.com/selecting-the-best-machine-learning-algorithm-for-your-regression-problem-20c330bad4ef
[3] benefits of max-pooling.:
https://www.coursera.org/lecture/convolutional-neural-networks/pooling-layers-hELHk
你也许还想看:
欢迎扫码关注:










 京公网安备 11010802041100号
京公网安备 11010802041100号