说明:许多企业目前都在使用CDH进行大数据开发,CDH具有方便,高效,一键配置,方便管理和搭建大数据组件的特点,所以下面说一下尚硅谷的Flume配合Kafka进行日志文件的采集。
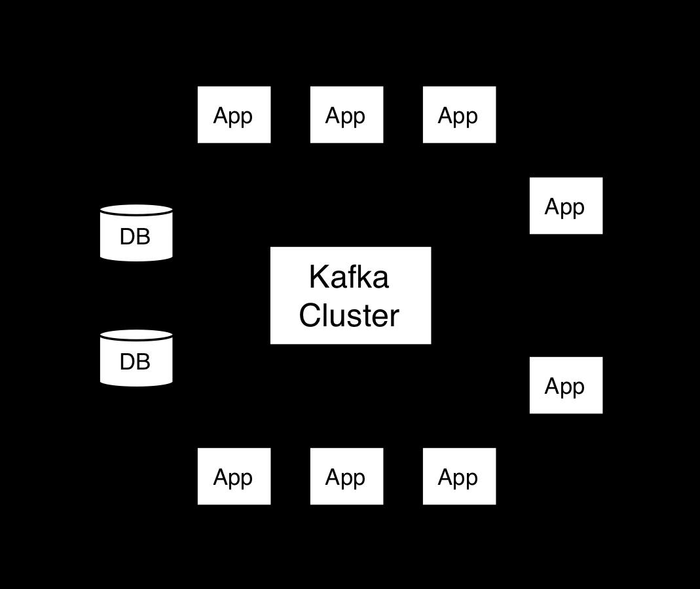
下图蓝框内为采集架构图,由架构图得到数据是以Flume –> kafka –> Flume –> HDFS进行采集的,可以看到使用了两次Flume

这一块的source是TAILDIR,channel是memory,sink是kafka,这一块用到了拦截器,拦截器的作用是将日志文件分为两个部分,一个部分就是启动日志start,一个是时间日志event,通过拦截器的筛选则会将日志文件筛选出这两部分存放在kafka的topic,前提要将kafka的topic建立好,topic_start,topic_event,此部分省略
注:flume采用的压缩为LZO,不知道如何让在CDH下配置LZO的请看我的这篇文章:CDH下LZO的配置



问:Flume的代码一定要这样放在CDH中吗
答:当然不是,这样写的好处是CDH启动后就会一直监测日志文件,只要生成日志文件就会进行传输,不这样写,按照普通配置文件也可以使用,flume-ng agent -c conf/ -n a1 -f /配置路径/f1.conf -Dflume.root.logger=DEBUG,consol 拦截器放在/opt/cloudera/parcels/CDH/lib/flume-ng/lib/
拦截器代码如下,jar包下载链接在下,可以配合Flume直接用
本项目中自定义了两个拦截器,分别是:ETL拦截器、日志类型区分拦截器。
ETL拦截器主要用于,过滤时间戳不合法和Json数据不完整的日志
日志类型区分拦截器主要用于,将启动日志和事件日志区分开来,方便发往Kafka的不同Topic。
1)创建Maven工程flume-interceptor
2)创建包名:com.atguigu.flume.interceptor
3)在pom.xml文件中添加如下配置
<dependencies> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.7.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> 4)在com.atguigu.flume.interceptor包下创建LogETLInterceptor类名
Flume ETL拦截器LogETLInterceptor
package com.atguigu.flume.interceptor; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.List; public class LogETLInterceptor implements Interceptor { @Override public void initialize() { } @Override public Event intercept(Event event) { // 1 获取数据 byte[] body = event.getBody(); String log = new String(body, Charset.forName("UTF-8")); // 2 判断数据类型并向Header中赋值 if (log.contains("start")) { if (LogUtils.validateStart(log)){ return event; } }else { if (LogUtils.validateEvent(log)){ return event; } } // 3 返回校验结果 return null; } @Override public List<Event> intercept(List<Event> events) { ArrayList<Event> interceptors = new ArrayList<>(); for (Event event : events) { Event intercept1 = intercept(event); if (intercept1 != null){ interceptors.add(intercept1); } } return interceptors; } @Override public void close() { } public static class Builder implements Interceptor.Builder{ @Override public Interceptor build() { return new LogETLInterceptor(); } @Override public void configure(Context context) { } } } 4)Flume日志过滤工具类
package com.atguigu.flume.interceptor; import org.apache.commons.lang.math.NumberUtils; public class LogUtils { public static boolean validateEvent(String log) { // 服务器时间 | json // 1549696569054 | {"cm":{"ln":"-89.2","sv":"V2.0.4","os":"8.2.0","g":"M67B4QYU@gmail.com","nw":"4G","l":"en","vc":"18","hw":"1080*1920","ar":"MX","uid":"u8678","t":"1549679122062","la":"-27.4","md":"sumsung-12","vn":"1.1.3","ba":"Sumsung","sr":"Y"},"ap":"weather","et":[]} // 1 切割 String[] logContents = log.split("\|"); // 2 校验 if(logContents.length != 2){ return false; } //3 校验服务器时间 if (logContents[0].length()!=13 || !NumberUtils.isDigits(logContents[0])){ return false; } // 4 校验json if (!logContents[1].trim().startsWith("{") || !logContents[1].trim().endsWith("}")){ return false; } return true; } public static boolean validateStart(String log) { if (log == null){ return false; } // 校验json if (!log.trim().startsWith("{") || !log.trim().endsWith("}")){ return false; } return true; } } 5)Flume日志类型区分拦截器LogTypeInterceptor
package com.atguigu.flume.interceptor; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.List; import java.util.Map; public class LogTypeInterceptor implements Interceptor { @Override public void initialize() { } @Override public Event intercept(Event event) { // 区分日志类型: body header // 1 获取body数据 byte[] body = event.getBody(); String log = new String(body, Charset.forName("UTF-8")); // 2 获取header Map<String, String> headers = event.getHeaders(); // 3 判断数据类型并向Header中赋值 if (log.contains("start")) { headers.put("topic","topic_start"); }else { headers.put("topic","topic_event"); } return event; } @Override public List<Event> intercept(List<Event> events) { ArrayList<Event> interceptors = new ArrayList<>(); for (Event event : events) { Event intercept1 = intercept(event); interceptors.add(intercept1); } return interceptors; } @Override public void close() { } public static class Builder implements Interceptor.Builder{ @Override public Interceptor build() { return new LogTypeInterceptor(); } @Override public void configure(Context context) { } } } 6)jar包链接 提取码:6wz8
a1.sources=r1 a1.channels=c1 c2 a1.sinks=k1 k2 # configure source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /tmp/logs/app.+ a1.sources.r1.fileHeader = true a1.sources.r1.channels = c1 c2 #interceptor a1.sources.r1.interceptors = i1 i2 a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.LogETLInterceptor$Builder a1.sources.r1.interceptors.i2.type = com.atguigu.flume.interceptor.LogTypeInterceptor$Builder # selector a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = topic a1.sources.r1.selector.mapping.topic_start = c1 a1.sources.r1.selector.mapping.topic_event = c2 # configure channel a1.channels.c1.type = memory a1.channels.c1.capacity=10000 a1.channels.c1.byteCapacityBufferPercentage=20 a1.channels.c2.type = memory a1.channels.c2.capacity=10000 a1.channels.c2.byteCapacityBufferPercentage=20 # configure sink # start-sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = topic_start a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sinks.k1.kafka.flumeBatchSize = 2000 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.channel = c1 # event-sink a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k2.kafka.topic = topic_event a1.sinks.k2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sinks.k2.kafka.flumeBatchSize = 2000 a1.sinks.k2.kafka.producer.acks = 1 a1.sinks.k2.channel = c2 Flume2架构图

## 组件 a1.sources=r1 r2 a1.channels=c1 c2 a1.sinks=k1 k2 ## source1 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r1.kafka.topics=topic_start ## source2 a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r2.batchSize = 5000 a1.sources.r2.batchDurationMillis = 2000 a1.sources.r2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r2.kafka.topics=topic_event ## channel1 a1.channels.c1.type=memory a1.channels.c1.capacity=100000 a1.channels.c1.transactionCapacity=10000 ## channel2 a1.channels.c2.type=memory a1.channels.c2.capacity=100000 a1.channels.c2.transactionCapacity=10000 ## sink1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.proxyUser=hive a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = logstart- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = second ##sink2 a1.sinks.k2.type = hdfs a1.sinks.k2.hdfs.proxyUser=hive a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d a1.sinks.k2.hdfs.filePrefix = logevent- a1.sinks.k2.hdfs.round = true a1.sinks.k2.hdfs.roundValue = 10 a1.sinks.k2.hdfs.roundUnit = second ## 不要产生大量小文件 a1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k2.hdfs.rollInterval = 10 a1.sinks.k2.hdfs.rollSize = 134217728 a1.sinks.k2.hdfs.rollCount = 0 ## 控制输出文件是原生文件。 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k2.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = lzop a1.sinks.k2.hdfs.codeC = lzop ## 拼装 a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1 a1.sources.r2.channels = c2 a1.sinks.k2.channel= c2 在HDFS上进行文件创建:
udo -u hdfs hadoop fs -mkdir /origin_data sudo -u hdfs hadoop fs -chown hive:hive /origin_data 体贴的我还给你们把日志生成jar包提供了,点个赞可以不~
链接:https://pan.baidu.com/s/1Lf7KTF6tvGmmZdr0Hbfv6w
提取码:jjgu
复制这段内容后打开百度网盘手机App,操作更方便哦–来自百度网盘超级会员V3的分享
重启Flume,然后再生成日志文件就可以看到文件出现了,注意修改你的ip地址就可以了

需要了解更多数据库技术:CDH下配置Flume进行配置传输日志文件(尚硅谷版),都可以关注数据库技术分享栏目—编程笔记









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有