文章目录
- Pandas
- 1. 关于pandas
- 2. pandas基础
- 2.1 pandas读取和写出数据
- 2.2 Series和Dataframe
- 2.3 各类排序
- 3. 索引
Pandas
1. 关于pandas
pandas是python中一个最重要的第三方库之一,将pandas使用得当是python学的怎么样的一个直接体现。现实中大多人使用excel预处理和观察数据,但是一旦数据量超过一定的水平,excel处理就变得棘手(例如随着数据的增加excel运行的速度明显慢于python,python处理数据有着excel不具有的功能,如当数据缺失或者数据异常时,利用python能轻松的得出这些异常数据并加以处理)
2. pandas基础
2.1 pandas读取和写出数据
现在的场景是手上有一个csv格式的数据:

接下来用python读入数据
import pandas as pd
df=pd.read_csv('D:/BaiduNetdiskDownload/joyful-pandas-master/data/table.csv')
df.head()

假设你读入数据并处理完后想要把处理后的数据还原给原本的csv文件。
df.to_csv('你想输入的目录')
2.2 Series和Dataframe
Series就是一列数据(例如上表中任意一列,如School或Class…),注意Series只代表一列,而dataframe则更广泛,代表多列。他们共同具有的属性是索引index,dataframe有columns名(表头)。
2.3 各类排序
对df数据集中的身高进行排序:
df.sort_values(by='Height',ascending=True)
'''
by:对哪一列排序
ascending:是否升序
'''

可以看出数据集按Height升序输出
3. 索引
3.1 布尔索引
iloc和loc是对数据索引切片的常用方法
比如想单独取出一列(以Weight为例)
'''
两种方式
第一个参数:行索引
loc 第二个参数:列名
iloc 第二个参数:第几列
'''
df.iloc[:,6]

其他切片方式:布尔索引
比如现在想对求出男性的平均身高的体重
df[['Height','Weight']][df['Gender']=='M'].mean()
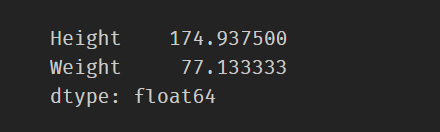
逐一对以上代码解析,df[‘Gender’]=='M’输出布尔向量

而df[[‘Height’,‘Weight’]]代表取这两列,df[[‘Height’,‘Weight’]][df[‘Gender’] == ‘M’]指的是两列数据取对应True值的位置。随后求平均数。
3.2 去重函数
数据中可能存在错误的重复值(例如ID是唯一标识符,不太可能有重复)如果数据中有重复可以用以下语句去重
'''
subset:对哪一列去重
keep: first,保留重复的第一个数
inplace: 去重后的数据替换原来重复的数据集
'''
df.drop_duplicates(subset=['ID'],keep='first',inplace=True)



 京公网安备 11010802041100号
京公网安备 11010802041100号