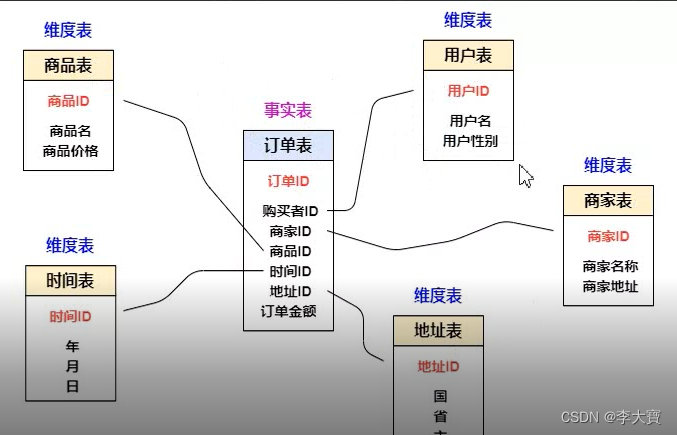
大数据时代,数据来源途径越来越丰富,而且类型也很多花样,存储和数据处理的需求量很大,对于数据展现也非常的高,并且很看重数据处理的高效性和可用性。
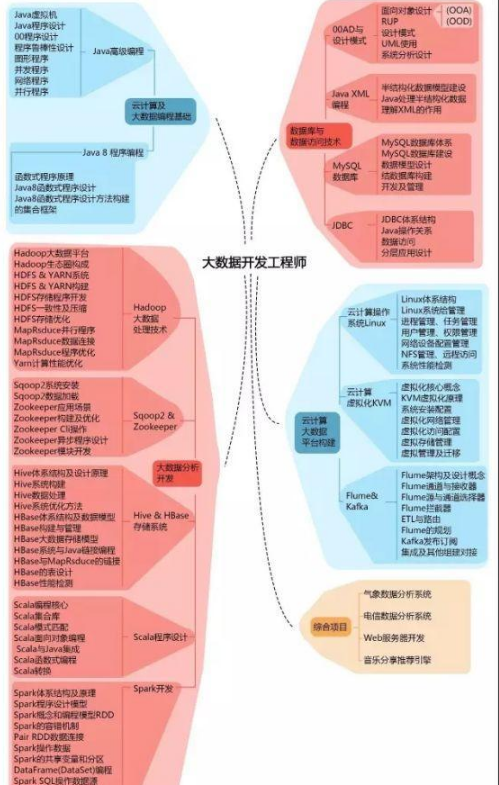
大数据领域已经涌现出了大量新的技术,它们成为大数据采集、存储、处理和呈现的有力武器。想要通过大数据技术获取更多有价值的东西,需要掌握大数据技术的核心技术:大数据采集、大数据存储及管理、大数据分析及挖掘、数据可视化。

在大数据领域,比较熟悉的几种技术:
Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群
Apache Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。

接下来具体讲解一下Apache Hadoop,Hadoop技术处理到底是什么,是如何实现的呢?
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
数据管理系统,作为数据分析的核心,汇集了结构化和非结构化的数据;
开源社区,主要为解决大数据的问题提供工具和软件。
一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行;
虽然Hadoop提供了很多功能,但仍然应该把它归类为多个组件组成的Hadoop生态圈,这些组件包括数据存储、数据集成、数据处理和其他进行数据分析的专门工具。
Apache Hadoop2.7,是经历多年企业生产应用和社区代码优化的稳定版。围绕Apache Hadoop为核心的顶级开源项目,其技术组件堆栈多达30多个组件,具备从运维管理、大规模计算、资源调度、分布式存储、多类型开发、弹性扩展、数据挖掘等全面的技术服务能力。
来源:http://www.sdydata.com/hyxw/info_itemid_85.html
转:https://blog.51cto.com/11520815/2341612








 京公网安备 11010802041100号
京公网安备 11010802041100号