最近在某个“群”, 经常看到吐槽某分布式数据库的“流言蜚语”,主要提到一些问题, 如系统不稳定,系统运行缓慢,等一些问题,细究大部分问题不在分布式数据库,而在于本身使用者不具备使用分布式数据库的最基本的“能力”。
现在大部分企业都在搞虚拟机,系统上云的工作,认为所有的设备应用都建立在虚拟的主机上,很方便也很便于管理. 尤其单体的数据库产品,部署在虚拟机上的不少,并且也大多工作的状态还可以.
分布式数据库尽量不要使用虚拟机, 大白话的意思就是分布式数据库, 如 TIDB , OCEANBASE, 等分布式数据库都不应该部署在虚拟机上.
我们以OB 为例, 这是官方OB推荐的最小安装 (最小安装是不能应用到实际的生产环境的)
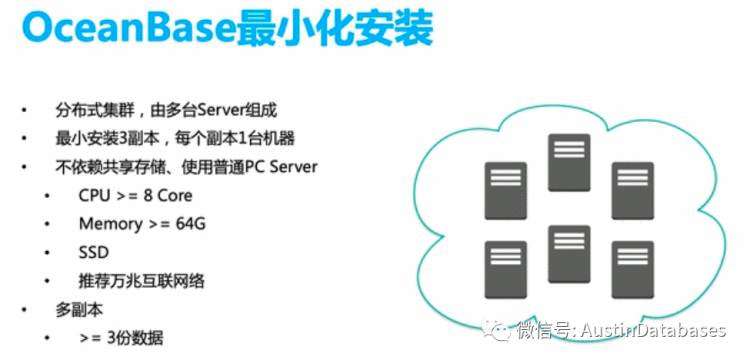
相关阿里推荐使用的机器配置如下
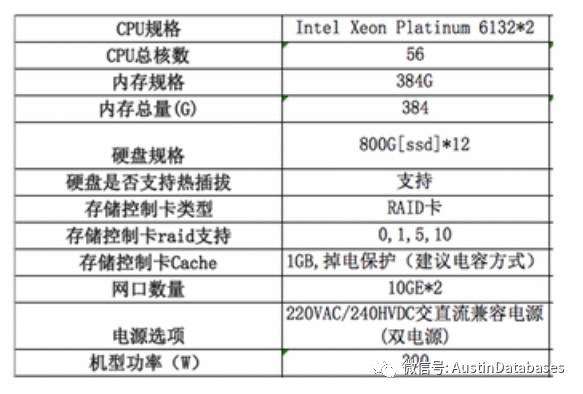
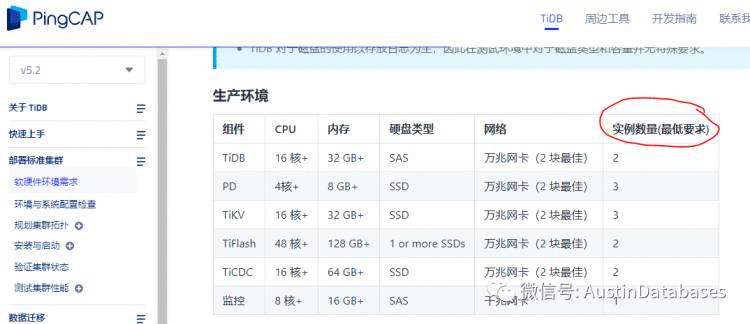
上面是TIDB的最小硬件主机数量配置. 从上面主流的两个分布式数据库重量级选手的推荐配置(也是最低的配置),看出每个分布式数据库都是需要强有力的硬件设备支持的。

这里就会产生一个疑问, 为什么主流的分布式的系统要求的硬件都如此的"高深莫测". 很多企业还在为一台虚拟的数据库主机是32GB 还是 64GB的内存纠结, 而分布式数据库产品的硬件要求让这样的企业感到 "臣妾做不到".

是数据库企业虚张声势,因为本身产品的能力不足用硬件来凑, 还是本身分布式数据库就需要大量的硬件作为保证数据库整体运行最正常的基础工作.
从分布式数据库设计的初衷来进行 "寻根溯源", 无论是 OB, TIDB, 本身分布式数据库要解决的核心问题是, 巨量数据的存储, 以及高并发的数据访问. 这是分布式数据库系统的核心需求.
基于这样的核心需求, 虚拟机本身就不应该是承载分布式数据库的主体, 虚拟机本身对下层硬件资源消耗以及在操作系统层 和 数据库系统本身之下多加了一层 "消耗". 分布式数据库本身设计的目的就是要用尽所采用的硬件资源, 在高并发和使用硬件资源时,不需要被限制.
分布式数据库在本身的设计初衷是为大数据量拆分,将不同的数据存储在不同的数据节点,同时将性能在多节点之间进行均分, 将分布式数据库架设在虚拟机上是违反分布式数据库设计的初衷,人为的制造新的性能瓶颈点和不稳定的因素. 当然这里的不稳定和性能瓶颈点都和“解耦” 有关, 分布式数据库本身是要解耦,使用虚拟主机完全达不到解耦的根本需求。
另外一点, 分布式数据库对于网络的稳定性以及网络的带宽的要求,万兆网是必须的配置. 基本上没有分布式数据库的厂商不要求千兆和万兆网络,以及网络的稳定性,有人说不就是网络吗, 有那么重要吗?
呵呵, 我们举一个例子, 单机的情况下,你的信息是从你的应用端发送到数据库端进行信息交互. 而分布式数据库是有多个组件组成,并且在每个组件的布置需要分离部署, 每个组件之间信息是要求频繁进行通讯的.
以TIDB 为例, PD 和 TIKV , TIDB 一定是分开部署的, 那如果你的网络不稳定或者或者带宽不够,TIDB 与TIKV 交互时信息频繁丢失(网络丢包), 很难想象你 TIDB 还能稳定运行, 一个分布式数据库系统的运行良好, 最基础的是由你的硬件资源和配置决定的, 所以分布式数据库部署硬件就是你的第一个门槛.
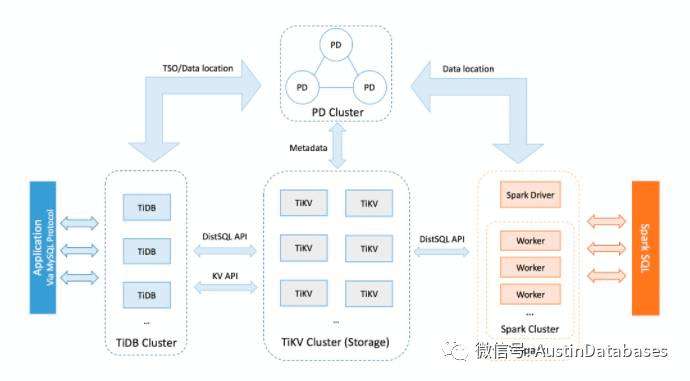
从分布式数据库的设计中是包含两段式提交的, 两阶段提交中,网络频繁丢包,或由于带宽的原因,造成数据传输拥塞, 分布式数据库会频繁的触发纠错机制,极端情况下会造成数据丢失和错误。
下面这张图中,在2PC 提交中在 5 号步骤中出现网络数据丢包,或者某一个节点,在事务提交时失效, 会造成整体每个节点的事务会回滚,事务执行失败,网络的稳定与可靠对于分布式数据库是另一道保证系统稳定运行的门槛。
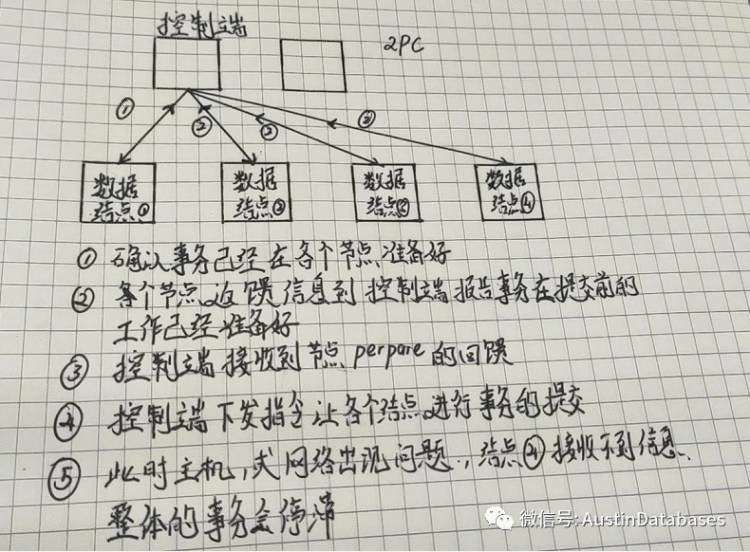
对于一个分布式数据库的部署切记有几点要满足
1 硬件资源充足, 不要使用虚拟机作为分布式数据库的承载端,避免在部署阶段就已经在给后面使用埋坑,导致后期系统不稳定。附加在分布式数据库系统下的系统层尽量要少。
2 网络的资源与稳定性要高, 分布式数据库对网络的依赖程度要高于单体数据库产品, 网络的带宽和稳定性一定要高, 出现网络不稳定,或网络长时间不联通后,对分布式数据库系统是毁灭性的打击.
在使用分布式数据库时的门槛,比单体数据库要高,无论从硬件资源,网络资源,以及使用人员对分布式数据库的理解,都是需要“门槛” 的,千万别把单机的经验直接搬到。使用类似 OB , TIDB 这样的数据库先看看自己的“斤两”,在去决定分布式数据库是否适合你,当然首先是观念要更新。







 京公网安备 11010802041100号
京公网安备 11010802041100号