实验五
https://mp.csdn.net/editor/html/116616391
配置环境和实验五一样
Hadoop提供的sheel的命令学习指导http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
一,利用Hadoop提供的Shell命令完成以下任务:
任务1:向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
- 先到Hadoop主文件夹
cd /usr/local/hadoop
- 启动Hadoop服务
sbin/start-dfs.sh
sbin/start-yarn.sh
- 创建两个任意文本文件用于实验
echo "hello world" > local.txt
echo "hello hadoop" >text.txt
- 创建用户工作目录(HDFS默认工作目录格式为/user/当前用户)
hadoop fs -mkdir -p /user/当前用户名 (此时提示hadoop不是command时,按照实验五添加hadoop环境变量)
- 检查文件是否存在
hadoop fs -test -e text.txt
echo $?
- 上传本地文件到HDFS系统
hadoop fs -put text.txt
- 追加到文件末尾的指令
hadoop fs -appendToFile local.txt text.txt
- 查看HDFS文件的内容
hadoop fs -cat text.txt
- 覆盖原有文件的指令(覆盖之后再执行一遍上一步)
hadoop fs -copyFromLocal -f local.txt text.txt
- 以上步骤也可以用如下Shell程序实现
if $(hadoop fs -test -e text.txt);
then $(hadoop fs -appendToFile local.txt text.txt);
else $(hadoop fs -copyFromLocal -f local.txt text.txt);
Fi
任务1的1-10命令:

任务2:从HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名。
Shell命令实现:
if $(hadoop fs -test -e /usr/local/hadoop/text.txt);
then $(hadoop fs -copyToLocal text.txt ./text.txt);
else $(hadoop fs -copyToLocal text.txt ./text2.txt);
fi

任务3:将HDFS中指定文件的内容输出到终端中;
Shell命令实现:
hadoop fs -cat text.txt

任务4:显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
hadoop fs -ls -h text.txt

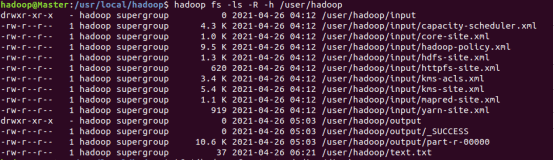
任务5:给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
Shell命令实现:
hadoop fs -ls -R -h /user/hadoop
任务6:提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录。
Shell命令实现:
if $(hadoop fs -test -d dir1/dir2);
then $(hadoop fs -touchz dir1/dir2/filename);
else $(hadoop fs -mkdir -p dir1/dir2 && hdfs dfs -touchz dir1/dir2/filename);
fi

删除操作:
hadoop fs -rm dir1/dir2/filename

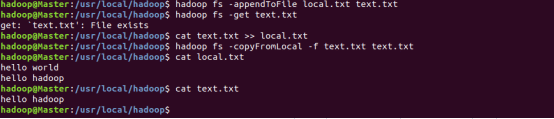
任务七:向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾。
追加到文件末尾
hadoop fs -appendToFile local.txt text.txt
追加到文件开头
hadoop fs -get text.txt
cat text.txt >> local.txt
hadoop fs -copyFromLocal -f text.txt text.txt
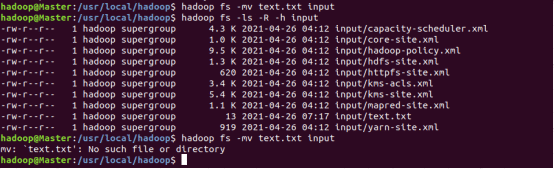
任务8:在HDFS中,将文件从源路径移动到目的路径
Shell命令实现:
hadoop fs -mv text.txt input
- 请给出每一个shell命令执行后的结果。
如任务下截图
- 请说明实验中hadoop fs -test -e text.txt命中hadoop fs命令组合的作用。
调用文件系统(FS)Shell命令应使用 bin/hadoop fs 的形式。 所有的的FS shell命令使用URI路径作为参数。URI格式是scheme://authority/path。对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
- 实验中hadoop fs -copyFromLocal -f text.txt text.txt中copyFromLocal参数的作用是什么。
使用方法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI
复制文件到本地文件系统,除了限定目标路径是一个本地文件外,和get命令类似。
- 实验中hadoop fs -get text.txt中-get参数的含义是什么。
使用方法:hadoop fs -get [-ignorecrc] [-crc] 复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。









 京公网安备 11010802041100号
京公网安备 11010802041100号