30秒执行摘要
时序数据是结构化数据,很适合使用为时序优化过的关系数据库存储和处理;
时序场景期望数据的正确性(ACID),以确保数据不错不重不丢,不支持ACID不是因为不需要,而是过去的产品做不到;
时序数据库需要强大的分析能力,而不是仅简单查询能力;
时序场景包含关系数据+时序数据,而不是仅有时序数据。
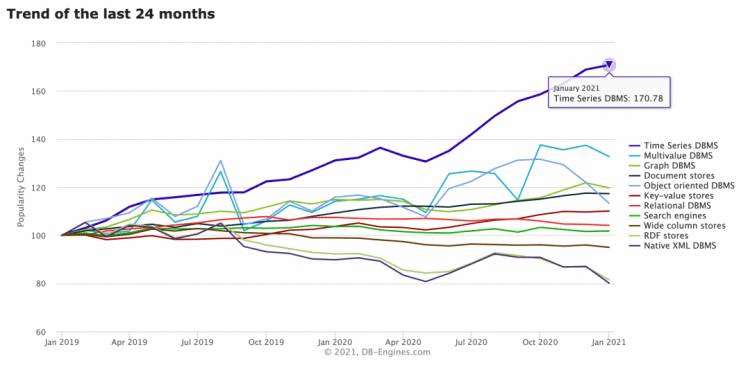
近几年IoT、IIoT、AIoT和智慧城市快速发展,时序数据库成为数据架构技术栈的标配。根据国际知名网站DB-Engines数据,时序数据库在过去24个月内排名高居榜首,且远高于其他类型的数据库,可见业内对时序数据库的迫切需求。
然而业内对时序技术的认知还停留在数年前,本文阐述时序数据库的4大误区,希望帮助读者理清来龙去脉和背后原因,以便在业务场景中选择合适的数据平台和技术栈。
误区1
关系数据库不适合时序数据的采存算用
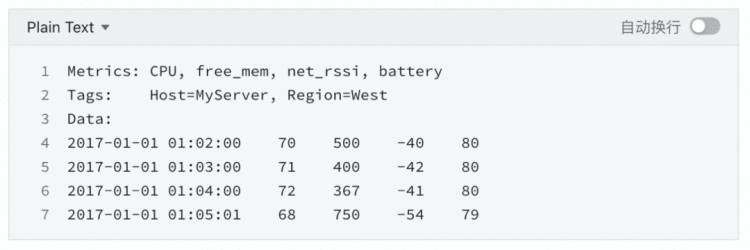
时序数据是时间序列数据,其本质是带有时间戳的一系列结构化数据,通常是周期固定的数据,譬如数控机床每百毫秒采集的轴坐标、移动量、速度等数据,无人机每秒采集的位置、高度、风力、风向等数据,汽车每分钟采集的位置、车速、转速、温度等数据,智能冰箱每小时采集的温度、湿度、耗电量,用户访问网站的点击事件流等数据。下面是时序数据的一个例子:metrics为指标名字,tags标识时序数据的来源,data为时间戳和该时刻的metrics指标值。
时序数据具有以下特点:
周期性持续采集数据源的时序数据,对插入性能要求高,可能发生乱序情况或者丢失数据;
时序数据量大,对存储压缩比敏感;
数据源标签属性多样化,修改频次低;
指标数据量大而变化小;
查询需求多样:单数据源最新值、单数据源明细、单数据源过滤聚集、多维查询、降采样、滑动窗口查询、数据源状态演变图、特定模式识别、趋势预测、根因分析、阈值修正等。
为了解决以上时序数据特点带来的挑战,受限于当时的技术能力,数年前业内走了开发专为时序数据而设计的时序数据库路线,我们称之为专用时序数据库。专用时序数据库的核心设计是存储引擎,以解决高效存储数据源属性信息、数据源指标信息、数据源层级关系信息等问题,并提供与之相匹配的简单的执行引擎和API,有的还提供某种形式的查询语言(譬如InfluxDB提供了Flux查询语言)。典型的代表是InfluxDB、OpenTSDB。
专用时序数据库一定程度满足了业务对时序数据处理的子集需求,然而也有诸多问题:
1. 性能低、扩展性差:这些时序数据库大多是为数据中心服务器监控之类简单场景而设计,可支持的数据源数量小、数据源采集指标数目少、tags数目少,无法适应物联网/工业互联网时代对大量数据源的大量指标的高频采集、存储、计算和应用需求;
2. tags数据和主数据更适合使用关系数据库存储:时序数据需要结构化才能变成有价值的信息。比如采集到数字37,那么它是温度、速度还是压力?单位是摄氏度、分钟还是帕斯卡?数据来源于锅炉、水泵还是变压器?设备数据来自生产车间还是在总部?没有这些信息,原始数据无法成为有用的信息。专用时序数据库大多采用tags来实现这样的功能,当tags数目比较多时性能差;且不易处理tags可能变化和更新的场景。此外时序场景需要主数据信息,而主数据通常存储在关系数据库中,因而使用关系数据库同时存储主数据、时序tags数据和时序指标数据更合适;
3. 需要MPP数据库或者大数据产品配合:专用时序数据库的设计核心是存储引擎,与之匹配的执行引擎能力都比较弱,中大型分析类查询性能低。故而目前市面上绝大多数时序数据库不支持分析能力,需要MPP数据库或大数据产品配合以支撑商务智能(BI)、机器学习(ML)和人工智能(AI)等应用;
4. 技术栈复杂,监控运维复杂:诸多产品学习曲线陡,知识共享度低,运维效率低且容易出错;
5. 技术栈复杂,开发效率低:应用程序需要维护与不同数据库的连接,开发大量代码,把数据从数据库拉到内存中进行合并聚集关联计算,效率低;
6. 数据孤岛化:引入任何一款数据产品都会导致新的数据孤岛,不同数据孤岛之间缺乏有效协作,数据一致性差,此外冗余副本数多,磁盘空间消耗严重。
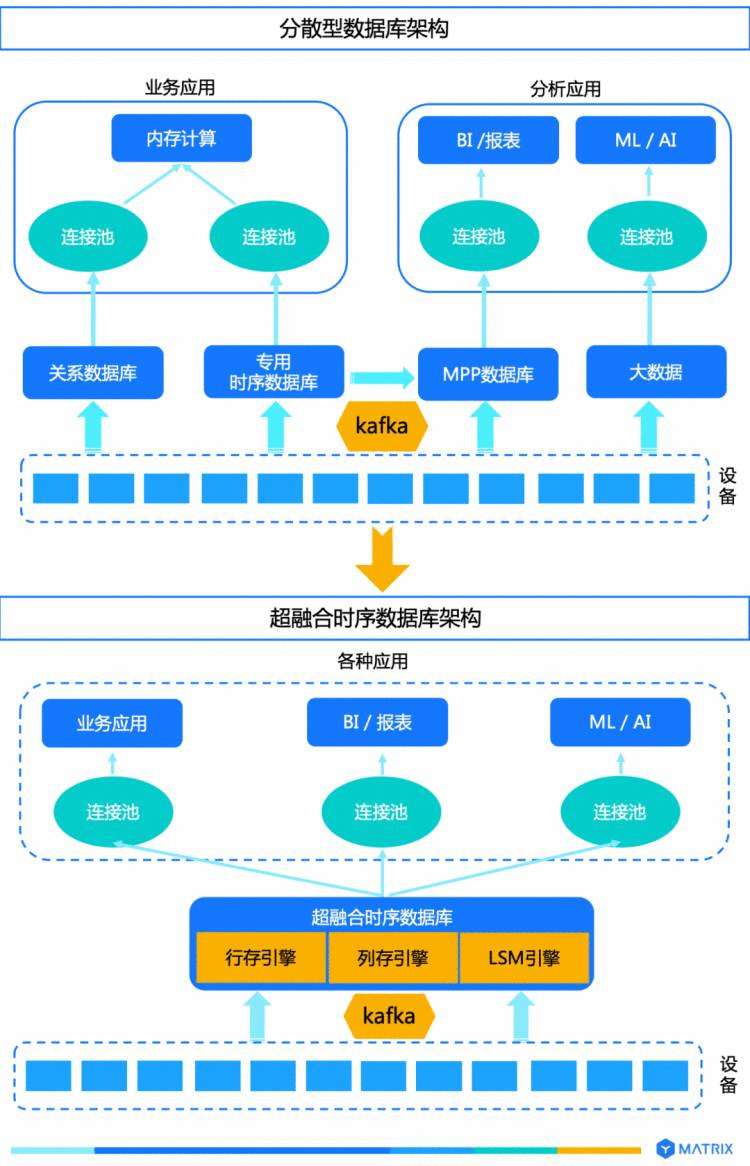
近几年,由于专用时序数据库的种种不足,工业界出现了一种新型的时序数据库方案:把时序(时间戳序列)当作关系数据库的一个数据类型,在关系数据库内设计相应的存储器,并增强优化器和执行器以发挥该存储器的优势,我们称之为超融合时序数据库(或关系时序数据库)。
把时序当做一种数据类型并不新颖,关系数据库从上世纪七八十年代就支持时间戳数据类型,然而过去关系数据库并没有专门为时序场景而优化,所以不能很好的满足时序场景的需求。原因是关系数据库普遍采用行存+Btree索引的方式:行存不利于压缩,而Btree是一种为读而优化的数据结构,会牺牲一定的写性能,所以传统认为行存+Btree不适合作为时序数据的存储方式。时序数据更适合使用列存+排序+预聚集等技术以提高写入速度、压缩比和查询性能。目前常见的时序数据库都使用了基于LSM 树的某种变种技术。
针对这一观点可从两个方面展开讨论
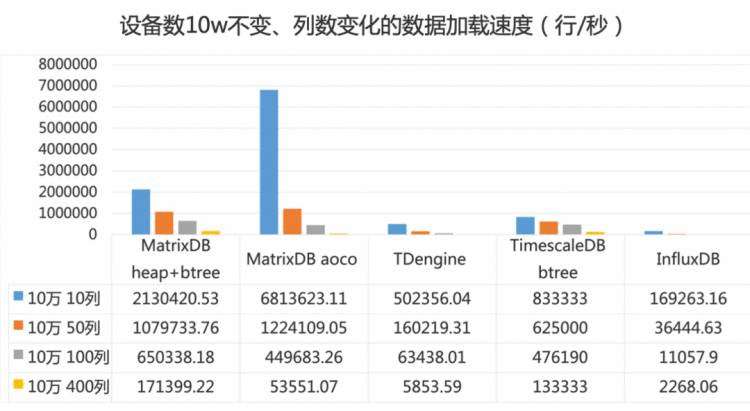
1. LSM树比B+树更适合写入,但是查询处理不如B+树友好。基于LSM变种的时序数据库为了解决各种场景的高性能查询需求,需要引入额外的开销,这些开销会降低数据写入性能,譬如InfluxDB为了支持多维查询引入了TSI,数据写入时需要创建并维护TSI数据。此外B+树虽然会造成随机IO,但是通过WAL+Buffer可以大幅降低随机IO频次。这样综合下来,基于LSM树的产品写入性能不一定比B+树产品更好。下图测试10万设备,采集指标10个、50个、100个、400个不等,实测了MatrixDB、TDEngine、TimescaleDB、InfluxDB四种时序数据库:
MatrixDB B+树写入速度可高达
InfluxDB的75倍(最慢12倍)
TDEngine的29倍(最慢4倍)
这个数字不是说B+树更适合时序场景,而是表达最终产品会综合考量非常多因素。
2. 现在很多关系数据库支持可插拔存储引擎、执行引擎和优化引擎技术架构,这使得关系数据库可以实现多种存储引擎,分别用来处理不同的数据类型或场景,譬如行存引擎存储关系数据、列存引擎存储历史数据、LSM引擎存储时序数据。这样可以在一款数据库中实现对不同数据类型和场景的处理,这种产品称为超融合数据库。超融合时序数据库基于模块化可插拔技术架构,在数据库内部提供专为时序数据优化的存储引擎(譬如基于LSM tree的存储引擎),并配以与之适应的执行器和优化器,借助关系数据库几十年的技术沉淀和最新工业技术成果,使得关系数据库除了支持原来的关系数据处理场景,还可以高效而灵活的处理时序数据全场景(包括点查、分析查询和流数据处理)而不再需要额外的产品配合,实现时序全场景all-in-one。
这种新思路新架构具备很大的优势:
性能卓越:关系数据库六十年积累沉淀了大量优秀的数据处理技术,加上针对时序的专门优化,性能远超专用时序数据库;
精简技术栈,无需关系数据库+时序数据库的产品组合方式,大大提升开发效率,降低运维复杂度;
支持ACID,确保数据不错不丢不重,把ACID复杂度留给数据库开发人员而不是丢给应用开发人员;
功能丰富:关系时序数据库具备几乎所有关系数据库的功能,譬如支持丰富的数据类型,包括数组、JSON等复合类型;支持自定义函数/存储过程;支持触发器;支持索引;支持监控管理;支持备份恢复;支持冷热分级存储;支持灵活的分区等;
完善的生态:关系数据库生态体系发展了几十年,关系时序数据库可以直接融入到已有的生态中。
故而,时序数据是一种结构化非常好的数据,非常适合使用专为时序优化过的关系数据库进行存储和处理,而不必使用专用时序数据库。
诸如MatrixDB这样的超融合时序数据库产品,在关系数据库中实现了对时序数据的支持,并且性能卓越,远超专用的时序数据库,测评指标参见https://ymatrix.cn。
误区2
时序数据库不需要正确性(ACID)
传统时序数据库,诸如InfluxDB、OpenTSDB、TDEngine等都不支持事务。然而这并不意味着时序场景不需要事务。毋庸置疑,有一些时序场景,譬如服务器监控,可以容忍丢失数据或者重复数据,但是也有大量的场景不希望错数据、重数据或者丢失数据,譬如:
证券极速交易、工业设备监控、电磁信号诊断和对抗等,这种场合每一条数据都非常重要,数据错误可能造成重大损失;
时序数据高级分析场景,譬如事件识别,趋势预测,异常诊断等。大数据分析一个基本共识是garbage in,garbage out,如果数据本身是错误的,那么得到的模型也会是糟糕的模型;
即使是能容忍错误数据的场景,也希望数据是正确的,只是过去的产品做不到。
时序数据库之所以放弃ACID主要是考虑到支持ACID的额外开销,希望通过放弃ACID以提高性能。实际上时序数据主要操作是INSERT和SELECT,从事务的角度来看,对总体性能影响微乎其微。
误区3
时序数据库不需要分析能力
主流时序数据库如InfluxDB、OpenTSDB,以及一些新时序数据库例如TDEngine,都只支持简单的查询,支撑简单的场景,譬如单数据源单/多指标过滤查询、单数据源单/多指标过滤聚集,多数据源过滤聚集等。核心是点查和聚集查询。
然而随着大数据分析、IoT、IIoT等快速发展,越来越多的应用需要更强大的分析能力,以实现模式识别、趋势预测等高级功能。因而时序数据需要强大的分析能力,包括和关系数据的关联聚集分析和高级分析(如ARIMA、趋势预测、特定模式识别、根因分析、阈值修正)等。
此外用户希望能用自己熟悉的语言譬如Python、R等对时序数据进行更复杂的处理,并充分发挥Python、R在数据分析方面的强大生态。
误区4
时序场景不需要关系型数据库
很多人认为时序场景只需要时序数据库,实际上很少有场景只需要时序数据库。绝大多数情况下,时序数据库需要关系数据库配合,以解决实际业务问题,因为时序数据库本质只能表达时间序列数据以及和时间序列数据紧密相关的元信息,譬如数据源id,位置,供应商等额外信息。而实际场景中,需要更多信息才能发挥时序数据的价值,譬如工业设备监控、智能制造、柔性制造、个性化定义等等。传统的时序数据库如InfluxDB、OpenTSDB无法解决这种场景,而必须配之以关系型数据库,以获得时序数据更多的上下文信息。
总 结
专用时序数据库是一个阶段性产物,是为了解决特定历史时期的供需矛盾而出现的。第三代超融合时序数据库以全新的思路解决专用时序数据库遗留的诸多问题,成为未来时序数据库发展的主流。目前很多专用时序数据库也已经开始或者计划添加更多的特性,数据产品的边界将越来越模糊。
关注
我们
yMatrix官方社群现已正式对外开放,我们诚挚地期待您的加入。在这里,您不仅可以了解到最前沿的创新技术,掌握最In的科技资讯,获取专业的技术解答,还能够有机会与大咖面对面的互动和交流;您还在等什么?快快扫描下方二维码,加小M助手为好友即可入群。












 京公网安备 11010802041100号
京公网安备 11010802041100号