摘要:
如何使用实时计算 Flink 搞定实时数据处理难题?本文由阿里巴巴高级技术专家邓小勇老师分享,从实时计算的历史回顾着手,详细介绍了阿里云实时计算 Flink 的核心优势与应用场景,文章内容主要分为以下四部分:
众所周知,阿里云的 Slogan 是“计算是为了无法计算的价值”。计算的实体是数据,但是随着时间的推移,数据的价值其实是逐渐递减的。如何从数据产生开始,尽早地发掘它的最大价值,成为实时计算不懈追求的目标。
随着技术的发展, Flink 已经成为实时计算的工业标准,越来越多的公司正在使用 Flink 作为自己实时计算的工具。在实时计算领域,阿里云也在不断地探索,并推出了实时计算 Flink 的产品。
本篇内容将通过四个方面,围绕云上实时计算 Flink 向大家展开介绍。
一、 实时计算的历史回顾
(一)实时计算发展时间轴
2013年
阿里内部已经上线了一些实时计算的典型场景,比如搜索引擎实时增量索引等等。
2015年
阿里建设了一个实时计算平台并在内部上线,并承接了当年双11 GMV大屏等关键业务。这些业务的开展,开启了实时计算 Flink 在阿里巴巴的发展。
2016年7月
实时计算1.0版本公测。采用Galaxy(基于Storm引擎开发),打响了实时计算上云的第一枪,比业界其他产品都要早。
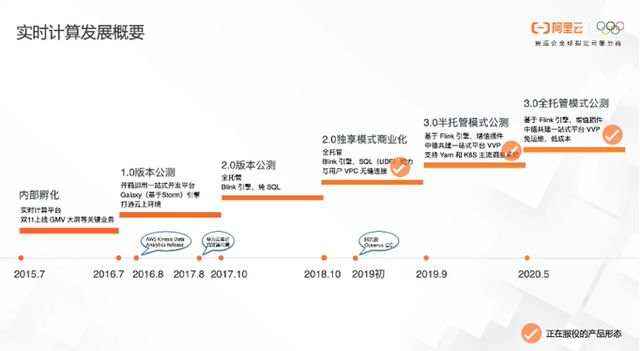
2017年10月
阿里基于 Blink 引擎的实时计算2.0版本上线并公测。该版本是基于大集群的全托管,只能运行SQL。当时用户的环境需要VPC,在这种大集群的情况下,要跟不同用户的VPC打通是一个比较大的问题。同时,由于是大集群,无法做到很好的隔离,也就意味着对SQL里面的UDF以及DataStream这些用户自定义逻辑互不影响得运行,所以只能推出纯SQL的作业模式。
2018年10月
实时计算2.0独享模式商业化。独享模式是指每个用户拥有独立的小集群,每个小集群跟用户的VPC通过 ENI无缝连接。在这种情况下,既做到了跟用户 VPC内上下游的连接,同时又能做好的物理隔离,解决了大集群很多功能限制的问题。
2019年的9月
实时计算基于 Flink 3.0半托管模式公测。由于一些大用户,需要对整个运行环境需要有比较好的掌控,于是我们推出了基于VVP(Ververica Platform)的实时计算半托管模式,即实时计算3.0半托管版本。这个版本是基于中德合作共建的一站式平台VVP,主要支持Yan和K8S两大主流的调度引擎。用户可以登录K8S或者Yan,去操作和管控自己的任务,同时也能享受到VVP提供的一些增值服务。
2020年5月
实时计算3.0全托管模式公测。相对于2.0版本,阿里推出了一种全新的全托管模式。
2.0版本底层是基于ECS机器这种资源方式,当用户资源不足的时候,扩容需要扩整台ECS机器,这种弹性有两个缺点,一是速度比较慢,二是整个ECS机器比较重,当用户只需要比如 1core资源的时候,需要弹出整台机器去满足用户的业务,不够灵活。同时由于为每个用户维护一套集群,对于系统运维来说也是一个巨大的挑战。
实时计算3.0版本推出的基于 Flink 引擎的全新全托管模式,背后是每个Region一套大集群。既能跟用户的VPC打通,又能做到充分隔离,用户就能够运行SQL的UDF和DataStream等作业,并保持跟社区的绝对兼容,按量付费,同时也给运维带来便利。这个版本也是业界在云化实时计算领域里的先行者。
(二)实时计算领域大事件
之前在阿里云上的实时计算是基于Blink和RealtimeCompute(产品)的模式,德国是基于 Apache Flink 引擎和VericaPlatform(产品)的模式。2019年双方合作后,大家统一将基础引擎调整为Apache Flink,并在上面添加增值插件,同时在阿里云上的产品统一以RealtimeCompute提供给用户,powered by Ververica。这样做的主要目的是通过共建的核心引擎和增值的插件,提升商业化能力,打造全球统一的技术品牌Ververica,在阿里云上继续使用原来的产品形态RealtimeCompute。

那么整个的关系是怎样的呢?
基于 Apache Flink ,阿里做了很多增值项,比如说Connecter、SQL增强、StateBackend增强等等。将这些能力产品化到阿里云上,这就是RealtimeCompute。随着RealtimeCompute对用户的接入和用户不断的反馈,从而不断丰富商业化的基本功能。这些功能又进一步抽象,再推回到Apache Flink社区中,从形成了社区、企业和产品良性循环发展的状态。
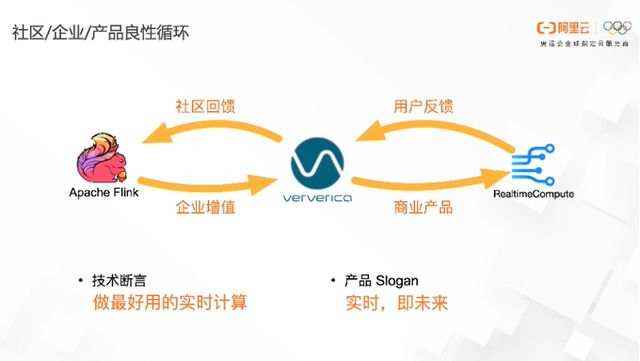
阿里技术致力于做最好的实时计算,所谓最好包括性能更强,功能更多,易用性更好。就像产品的Slogan“实时即未来”所表达的,希望更多的计算场景采用实时计算,更多的业务使用 Flink ,希望用 Flink 推动整个实时计算的发展。
2015年开始,实时计算 Flink 积累了很多基于不同业务领域的场景,包括实时大屏场景、实时机器学习、实时的ETL场景和实时数仓场景等。同时覆盖互联网、在线教育、新零售、交通出行、金融财富等各个领域,培育了很多标杆客户(见下图表格)。这些客户既扩大了对 Flink 的使用,同时客户们宝贵的场景和反馈也促进了实时计算 Flink 的优化和发展。
二、 为什么选择实时计算Flink
互联网发展到今天,业务实时化趋势越来越强。在在线应用、在线ML、实时风控、实时ETL等各行各业领域,实时计算的发展越来越越好,实时计算的需求也越来越强。下面罗列了四个选择实时计算Flink的理由。
理由一 上云优势
云上实时计算 Flink 具有“云”的天然优势。
- 成本的优势:在云上的实时计算,节省了用户建设和维护基础设施的成本,比如说机房、网络等等。
- 灵活的优势:一块业务的发展是需要多个引擎或者多款产品的组合,如果用户选择自建,不仅需要建设各个产品,还无法实现按需选择;但是在云上,用户可以根据自己的需要选择需要的产品。
- 扩展性的优势:在线下自建,用户需要提前预估好资源,预估多了可能造成资源浪费,预估少了不一定能够扛过业务的峰值。 而在云上可以实现按需索取,更具弹性,完全契合业务需求。
理由二 原创出品
实时计算 Flink是阿里与 Flink 原创团队中西合璧共同打造的一个国际化产品。完全兼容社区,用户的作业甚至基本不需改动,就可以平迁到实时计算 Flink中。如果遇到一些用户问题,也可以及时地反馈给社区,并迅速修复。同时,在 Apache Flink 的基础之上,提供了丰富的增值能力,这些能力对云上的使用场景尤为重要,也成为实时计算Flink带给用户的核心价值。
理由三 丰富经验
对于实时计算 Flink ,阿里具有丰富的实践经验。阿里巴巴已经使用实时计算 Flink 近10年时间,承接了全阿里集团的实时业务,经历过多次双11的实战大考,在这期间大量的经验和业务场景被积累下来,直接赋能用户。而这些经验和业务场景,是需要用户自己经过漫长时间和人力投入才能获得的。
理由四 企业增值
首先是Connector“多”。
Flink的输入输出需要对接不同上下游,而在阿里云上下游存储也比较多,实时提供的 Connector 基本覆盖了目前云上所有的数据存储,包括开源的和商业的,而这在社区是远远少于企业版的;并且针对一些重要场景的多次打磨和特殊优化,无缝衔接上下游。
添加了更多内置函数,可以为用户提供垂直领域的函数,使用户做到开箱即用。 “多”还指对系统和业务的监控指标非常多。这些监控指标能够让用户更直接的看到整个系统的情况,省去了自己埋点或查询资料。实时计算的运维也对接了阿里云的运维体系,如果用户有使用阿里云的经验,就可以无缝的使用阿里云的运维工具来维护自己的实时计算 Flink 的任务。
其次是“快”,指更快的实时计算能力。
如何做到更快的实时计算呢?在 Apache Flink 基础之上,自研流计算存储引擎Gemini,平均优于开源性能1倍以上。并对某些SQL或 Table API算子进行了深度优化,部分性能也能领先开源2倍。
版本更新速度快,社区的新版本可以在阿里云上很快地发布出来,同时部分功能也可以优先于社区让用户提前得到体验。提前使用的功能,用户也不用担心只在阿里云上有,后续还能推回到社区中。
作为企业级产品,7×24小时的服务可以在规定时间里响应客户并及时处理客户问题。如果遇到bug也可以先于社区发布提前解决。
第三是“好”,主要体现在跟整个云环境技术环境的集成,包括账号权限体系、存储告警、日志链路等等。对于Yan和K8S做了深度的优化,对于作业的提交时间以及大量作业提交运行的调度能力都做了深度的优化,达到生产级可用。这些优化都是在阿里巴巴集团内部使用并检验过后再发布到云上的。
另外,实时计算 Flink 还提供了Web Console,实现一站式开发调试运维服务,用户可以通过白屏化的方式去操作作业。
阿里还提供了全链路的智能诊断工具,可以让用户更智能的分析、诊断作业的问题,并且给出智能提示。
最后,阿里提供了OpenAPI,可以让用户做二次开发,方便集成自有系统中去。
实时计算 Flink内置元数据集成,同时也可以与外界的HMS等元数据系统打通。SQL开发基本上已经成为大数据开发的趋势,用户可以在Web上编辑、调试、运行SQL,或发现SQL问题。同时集成了 Alink 的能力,通过 Flink 来实现传统机器学习的算法。

“省”是用户最关心的,如何省资源、省人力和省钱等。实时计算 Flink为用户提供了单作业粒度的AutoPilot能力,这就意味着随着任务运行,假设遇到业务波峰需要更大并发和更多资源,或遇到波谷需要释放掉并发或资源,可以帮助用户进行自动调节。跟上文提到的实时计算3.0全托管形态深度的结合,单作业可以自动调优,用户还可以根据所需资源按量付费,弹性扩缩容,从而节省成本。
对于全托管用户,7×24小时运维服务可以为用户节省很多人力成本;对于半托管用户,实时计算 Flink也提供了专业的技术支持,去定位用户问题并给出解决方案。对于全链路的开发运维以及完整的作业生命周期管理,实时计算 Flink也为用户节省了不少时间成本。
三、 实时计算Flink产品介绍
实时计算 Flink 的产品介绍主要包括:产品技术栈、云上产品形态和实时打通上下游。
(一) 产品技术栈
如下图所示,整个产品技术站分为以下几个部分(由下往上):
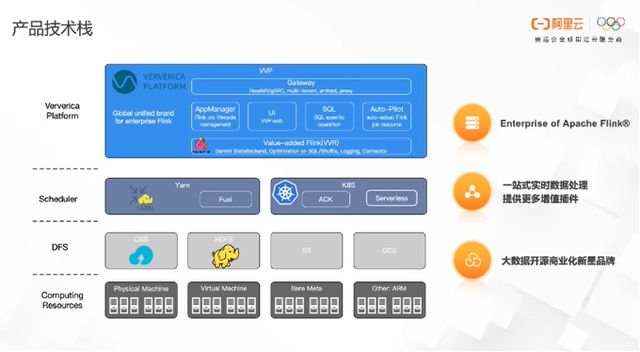
计算资源,包括物理机、虚拟机等等。实时计算 Flink 的运行需要一套分布式文件系统,这些文件系统在阿里云上主要用通过OSS、HDFS等分布式文件系统实现。关于调度系统,最主要的是支持了当前比较热门的Yan和K8S两种调度系统,充分满足了不同调度系统体系用户的需求。
上层是 Ververica Platform。首先基于Apache Flink 做了增值插件,包括上文提到GeminiStateRockend、对SQL的优化和丰富的Connector;在任务管控层采用微服务架构,给用户提供整个作业生命周期的管理,Web的开发和查看,SQL的开发以及AutoPilot的能力等等。在这做了更多任务管理上的增值和优化。最终的目标是让Apche Flink企业化版本提供一站式处理能力,并提供更多优化插件。
(二) 云上产品形态
阿里云的实时计算 Flink这款产品已经成为开源引擎商业化的新星。目前在公共云上,主要有全托管和半托管两种形态,全托管主要适合那些关注业务发展但是不关心集群运维的用户,也就是托管集群的形态。我们强烈推荐使用 Flink 全托管,跟社区完全兼容,无缝跟上下游打通,相互安全隔离,又能按量付费。
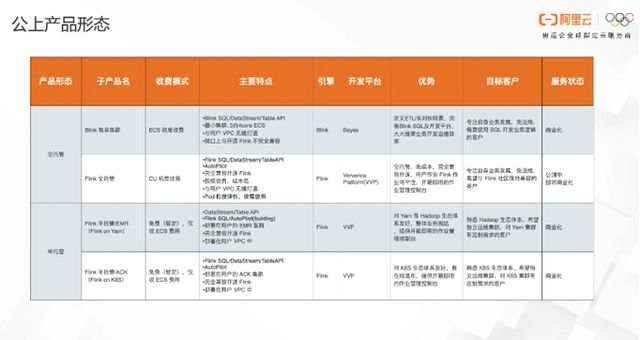
半托管主要是将整个Ververica Platform部署到用户的环境中,用户的环境可以是Yan也可以是K8S。目前半托管的这两款产品都已经商业化,并且仅收取 ECS的费用,对于Yarn或者K8S有偏好的用户,可以选择这两款产品。
(三) 实时打通上下游
不管选择哪种产品形态,都要做到打通用户上下游,像数据总线、日志服务、消息队列这样的一些流式表能够流进 Flink ,像表格存储、数据库服务等等能够作为维表。对于一些大型的存储,像MaxCompute,Hbase,OSS数据量不是特别大的情况下,也能够以维表方式加载进来。同时,这些系统也可以做出 Flink 的输出,供用户业务使用。
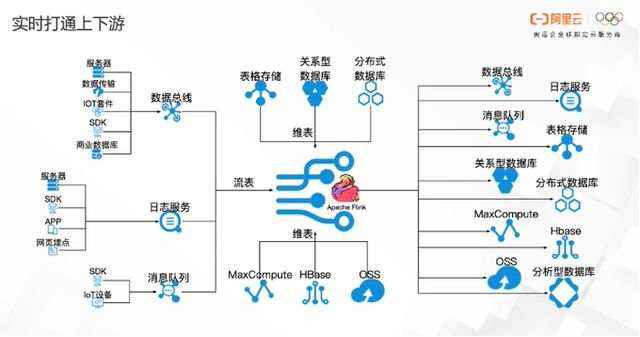
实时计算 Flink 直接将用户的流式存储作为上游,用户的一些查询存储作为维表,然后再输出到用户的环境中,不需要做数据搬移,可以自动跟用户的环境打通并完成复杂的逻辑计算。
四、 实时计算 Flink 未来可期
对于未来的发展,阿里云实时计算 Flink摩拳擦掌,信心满满。
产品功能持续推出
SQL的建设正在逐渐完备,比如SQL Preview能力能够提前在SQL提交之前就能够得到SQL的部分产出,用来判断SQL的逻辑是否正确;通过 Flink Session 提交任务,更快且节省成本;更智能的AutoPilot能力,为用户进一步节省成本;还会在SQL层进行深度优化,不断提高运行性能;对于长时间运行的 Flink ,我们将Debug和TrouleShooting能力作为主要建设目标,让用户能够方便地定位目前作业的状态以及健康程度;添加常用的监控报警,让用户能够及时感知作业的异常。
产品介绍持续更新
通过入门篇、实操篇和高级篇,由浅入深地持续为大家介绍产品。
入门篇主要介绍产品的概念以及应用场景如何开通等等;实操篇主要介绍基于实时计算 Flink 用户如何去写自己DataStream作业和SQL作业,如何使用一些AutoPilot等基础的功能;高级篇主要介绍如何使用实时计算 Flink 做Trouble Shooting和更有效的配置,比如 Flink 的内存资源调优等等。
作者:邓小勇(静行)
原文链接
本文为阿里云原创内容,未经允许不得转载。






 京公网安备 11010802041100号
京公网安备 11010802041100号