作者:吴国伟60942 | 来源:互联网 | 2023-07-23 12:35
导语:如何将大数据与 AI 结合......
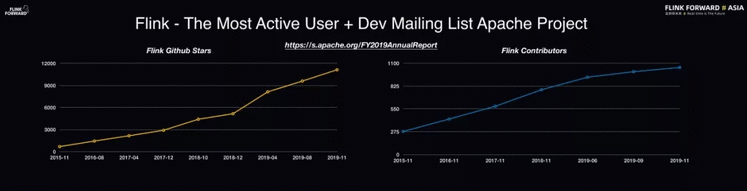
自 Flink 开源以来,越来越多的开发者加入了 Flink 社区。仅仅 2019 年,Flink 在 GitHub 上的 Star 数量翻了一倍,Contributor 数量也呈现出持续增长的态势。而它目前在 GitHub 上的访问量,也位居 Apache 项目中前三,是 Apache 基金会中最为活跃的项目之一。
Flink 发展如此之快,除了开源使得更多开发者与企业可以接触与使用之外,它在 AI 方面的部署也起着很大作用。看似 Flink 的主要应用场景还是数据分析,但它面向多个 AI 场景,已经提供了深度学习引擎协同等功能。而对于这一与时俱进的 Flink,我们也许可以看到更多可能的未来。
Flink?Blink?Alink?
很多人在谈到 Flink 的时候,也通常会提 Blink 和 Alink。从名字可以看出,它们与 Flink 有着很深的联系,Blink 和 Alink 都是基于 Flink 而得。
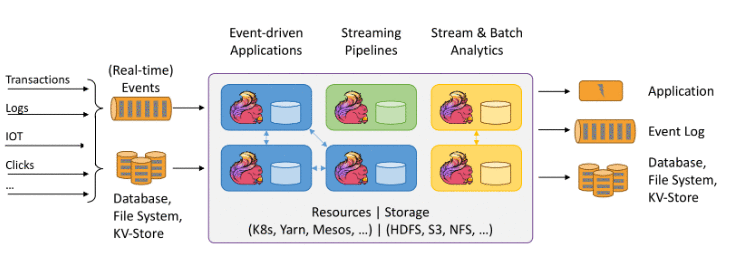
Flink 状态计算中的数据流
Flink 是欧洲的一个大数据研究项目,早期专注于批计算,再到后来 Flink 发展成为了 Apache 的顶级大数据项目。
具体而言,Flink 擅长处理无边界和有边界的数据集。对时间和状态的精确控制使 Flink 的运行时能够在无限制的流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部进行处理。
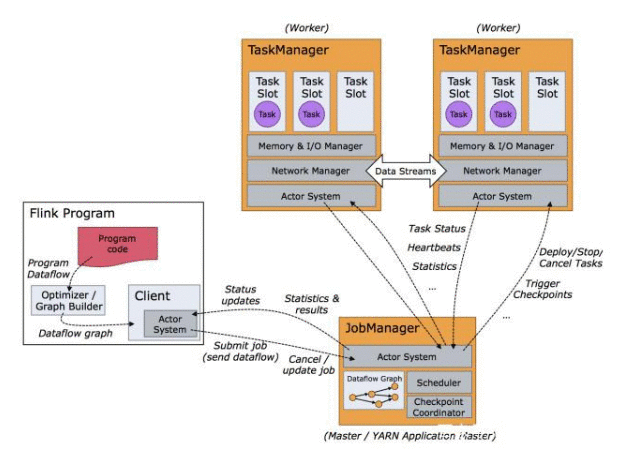
Flink 架构
其核心是一个流式的数据流执行引擎,能够基于同一个 Flink 运行时,提供支持流处理和批处理两种类型应用。它在运行时的架构主要包含几个部分:Client、JobManager(master 节点) 和 TaskManger(slave 节点),是一个高效和分布式的通用数据处理平台。
更多信息:
https://flink.apache.org/
Blink 是阿里在 2018 年推出的内部改良 Flink,主要针对业务场景需求,做了如下几个优化:
-
优化了集群调度策略使得 Blink 能够更好更合理地利用集群资源;
-
优化了 checkpoint 机制,使得 Blink 能够很高效地处理拥有很大状态的 job;
-
优化了 failover 的策略,使得 job 在异常的时候能够更快恢复,从而对业务延迟造成更少的影响;
-
设计了异步算子,使得 Blink 能够在即使被读取外部数据阻塞的同时还能继续处理其他 event,从而获得整体非常高的吞吐率。
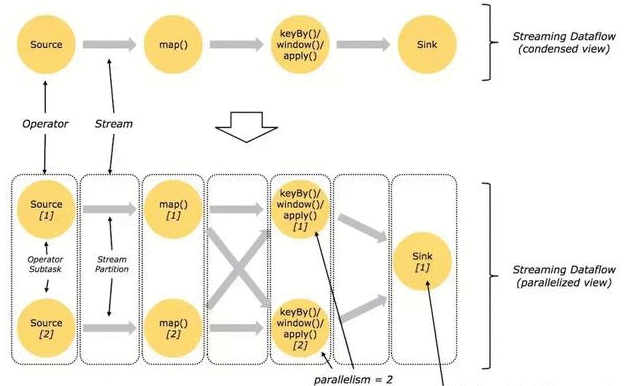
一个典型的 Blink workflow 示意图
目前,Blink 已开放给开源社区。今年 8 月发布的 Flink 1.9.0 是阿里内部版本 Blink 合并入 Flink 后的首次发版,在今天的 Flink Forward 2019 大会上,阿里发布了 Flink 1.10 版本功能前瞻,正式版本预计于 2020 年 1 月发布。
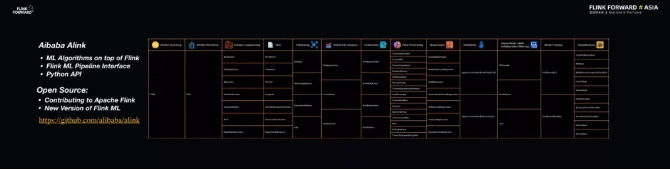
而 Alink 则是基于 Flink 的机器学习算法库,由阿里云机器学习 PAI 团队开发。除了支持阿里的平台外,还支持 Kafka,HDFS 和 HBase 等一系列开源数据存储平台。
这是一套分布式、批流一体的机器学习算法库,它既非常好地利用了 Flink 批流一体的计算能力以及在机器学习基础设施上的一些优势,又结合了一些业务场景需求,在机器学习方面有很强的性能。
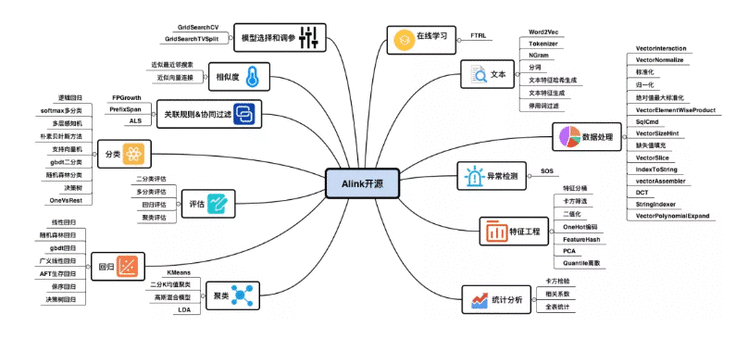
开发者和数据分析师可以利用开源代码来构建软件功能,例如统计分析、机器学习、实时预测、个性化推荐和异常检测。而 Alink 提供的一系列算法,可以帮助处理机器学习任务,例如 AI 驱动的客户服务和产品推荐。
近日,阿里云计算部门已在 GitHub 上发布了其 Alink 平台的「核心代码」,并上传了一系列算法库,支持批处理和流处理,有利于机器学习相关任务。
更多信息:
https://developer.aliyun.com/article/738040?utm_content=g_1000092211
携 AI 前行的 Flink
近年来,AI 场景发展得如火如荼,同时其计算规模也越来越大。这也让专注于数据处理的 Flink 有了较大的发展空间。
在 Flink 社区对 AI 的大力支持下,Flink 机器学习方面开发了支持 AI 场景,以及和 AI 原生的深度学习引擎实现协同,例如: Flink + TensorFlow、Flink + PyTorch 等,并提供大数据+AI 的全链路解决方案。
2019 年,Flink 在 AI 方面首先部署了机器学习基础设施,第一件事情便实现了 Flink ML Lib 的基础 API,即 ML Pipeline。
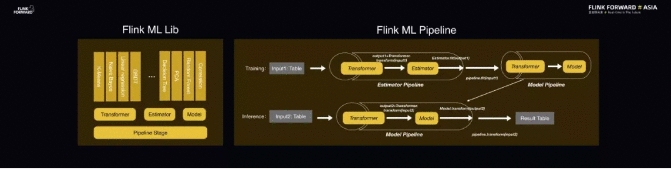
ML Pipeline 的核心是机器学习的流程,其中的核心概念包含 Transformer、Estimator、Model 等。Flink 机器学习算法的开发人员可以使用这套 API 去开发不同的 Transformer、Estimator、Model,并实现各种经典的机器学习算法。
同时,基于 ML Pipeline 这套 API 还能够自由组合组件来构建机器学习的训练流程和预测流程。
对于 AI 算法的开发人员而言,目前主流的语言即为 Python。因此,Flink 对于 Python 的支持也尤为重要。
在 2019 年,Flink 社区也投入了大量的资源来完善 Flink 的 Python 生态,并开发了 PyFlink 项目;与此同时,也在 Flink 1.9 版本中实现了 Python 对于 Table API 的支持。
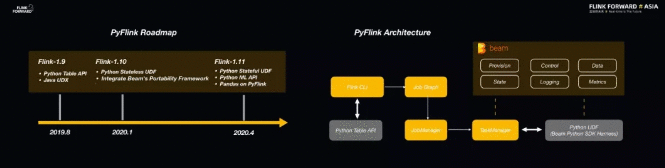
除此之外,Flink 1.10 版本还重点支持了 Python UDF 特性。这个部分直接使用成熟的框架,Flink 社区与 Beam 社区之间开展了良好的合作,并使用了 Beam 的 Python 资源,比如:SDK、Framework 以及数据通信格式等。
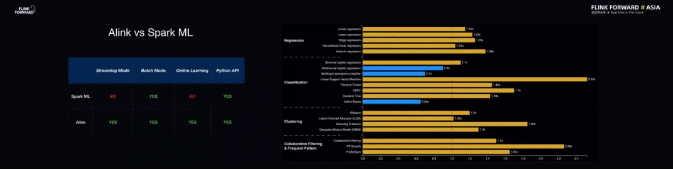
据相关数据显示,将 Alink 与主流的机器学习算法库进行对比,它不仅能够支持批式训练的机器学习场景,也能够支持在线的机器学习场景。
而 Alink 在离线的机器学习场景下与主流的 Spark ML 的对比显示,其在功能集合上所有算法基本一致。
在性能对比方面,Alink 和 Spark ML 在离线训练场景下的性能基本在一个水平线上。但 Alink 支持部分算法通过流式方法进行计算,更好地实现在线机器学习。
另外,AI 部分的新项目——AI Flow 也值得关注。AI Flow 是大数据及 AI 的处理流程平台,在 AI Flow 中定义不同数据之间的关系以及元数据格式等就能够非常方便地搭建一套大数据及 AI 处理的流程。
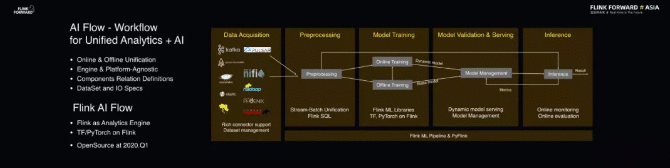
整个 Workflow 并不绑定某一引擎或者平台,但是用户可以借助 Flink 批流一体的能力去搭建自己的大数据及 AI 解决方案。目前,AI Flow 项目正在准备中,预计将于明年的第一季度以与 Alink 相同的模式进行开源。
Apache Flink 未来计划
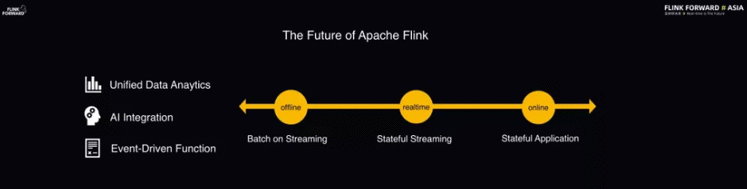
如今,Flink 的主要应用场景基本上还是数据分析,尤其是实时数据分析。Flink 本质上是一款流式数据处理引擎,覆盖的场景主要是实时数据分析、实时风控、实时 ETL 处理等。未来,社区希望 Flink 演化成为统一的数据引擎。
-
在离线数据处理方面,希望 Flink 能够在流数据处理的基础之上进一步实现批与流的统一,提供统一的数据处理和分析的解决方案。
-
另一方面,朝着在线数据分析处理的方向演进,即利用 Flink 的核心优势、Event-Driven Function 的能力以及 Flink 自带的状态管理等特性实现在线的函数计算。
而对于 Alink,未来 Flink 社区希望使用新开发的 Alink 的算法,逐渐替换掉原有的一套机器学习算法库 FlinkML 的算法,并期待着 Alink 成为新一代版本的 FlinkML。
但由于 Alink 包含了非常多的机器学习算法,预计往 Flink 贡献或发布的时候整个过程耗时会比较长,所以 Alink 已经单独开源,大家如果有需要的可以先用起来。
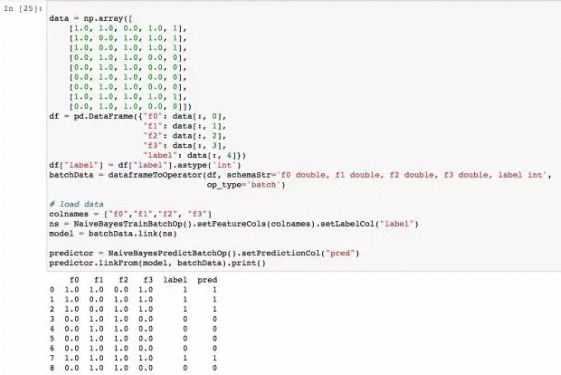
PyAlink 在 notebook 中使用示例
后面贡献进展比较顺利的情况下,Alink 应该能完全合并到 FlinkML,也就是直接进入 Flink 生态的主干,这时 FlinkML 就可以跟 SparkML 完全对应起来。
当然,在未来 Flink 也会进一步完善对于 Python API 和 UDF 的支持,在 ML Pipeline 上更多地支持 Python,同时也希望引入更多成熟的 Python 库。

Github 开源地址:
https://github.com/alibaba/Alink
https://github.com/apache/flink









 京公网安备 11010802041100号
京公网安备 11010802041100号