参考:https:zhuanlan.zhihu.comp45002720https:blog.csdn.netshenxiaolu1984articledetails5142839
参考:
https://zhuanlan.zhihu.com/p/45002720
https://blog.csdn.net/shenxiaolu1984/article/details/51428392
https://blog.csdn.net/wangzi371312/article/details/81174452
https://github.com/bearpaw/pytorch-pose
https://github.com/princeton-vl/pytorch_stacked_hourglass
https://github.com/wbenbihi/hourglasstensorlfow
https://github.com/microsoft/human-pose-estimation.pytorch/blob/master/lib/dataset/coco.py
姿态估计(pose estimation)在计算机视觉领域是一个非常重要的方向,人类动作理解,人机互动等等应用都需要精确的姿态识别。目前,绝大多数的2d姿态识别都是识别人体的关键点,比如,给定一张普通的RGB图像,算法会给出人体的脚踝,胳膊,面部等区域的关键点(keypoint)目前,基于stacked Hourglass Model的各种变种算法,牢牢占据了姿态检测的半壁江山,所以,非常有必要搞清楚stacked hourglass model。
1 提出同时使用多层特征
stacked hourglass model(以下简写做SHM)的主要贡献在于利用多尺度特征来识别姿态。以前估计姿态的网络结构,大多只使用最后一层的卷积特征,这样会造成信息的丢失。事实上,对于姿态估计这种关联型任务,全身不同的关节点,并不是在相同的feature map上具有最好的识别精度。举例来说,胳膊可能在第3层的feature map上容易识别,而头部在第5层上更容易识别,见下图。所以,需要设计一种可以同时使用多个feature map的网络结构。
2 .Stacked HourGlass 网络结构详解
在我刚开始接触SHM时,无论是原文还是其他博客,看起来云里雾里的,不是很明白具体的网络结构到底是什么样的,直到后面阅读源码才对细节一清二楚。这里吐槽一句,大部分paper,不给你源码,你绝无可能自己复现出来,甚至某些开放了源码的,都无法跑出文章给的结果!所以一切不给源码的paper都是在耍流氓。
2.1 Hourglass Network
细心的读者可能注意到了,这里为什么少了个Stacked?因为堆叠沙漏网络是多个沙漏网络串联起来的,首先要明白单个的Hourglass Network如何工作的。串联的Stacked Hourglass相比单个网络主要是复用全身关节信息来提高单个关节的识别精度,后面会进一步解释。
首先还得看看resisual block,
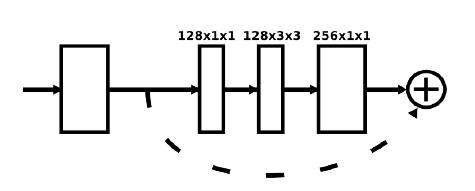
上图的残差块是论文中的原图,描述的不够详细,自己看了下源代码之后,画出了如下图所示的Residual Module:
Hourglass Module由上面的Residual Module组成,由于它是一个递归的结构,所以可以定义一个阶数来表示递归的层数,首先来看一下一阶的Hourglass Module:
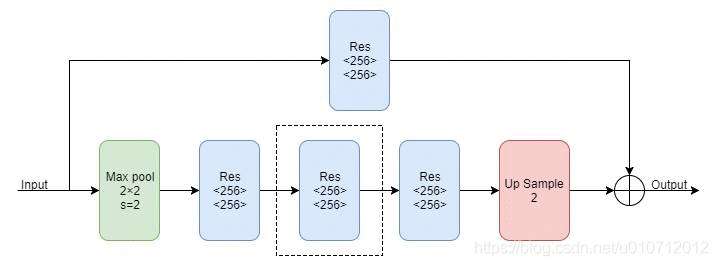
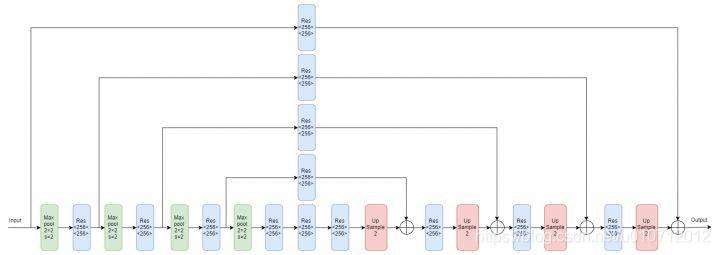
上图中的Max pool代表下采样,Res代表上面介绍的Residual Module,Up Sample代表上采样。多阶的Hourglass Module就是将上图虚线框中的块递归地替换为一阶Hourglass Module,由于作者在实验中使用的是4阶的Hourglass Moudle,所以我们画出了4阶的Hourglass Module的示意图:
每次降采样之前,分出上半路保留原尺度信息;
每次升采样之后,和上一个尺度的数据相加;
两次降采样之间,使用三个Residual模块提取特征;
两次相加之间,使用一个Residual模块提取特征。
但我们还是得一个一个分析:
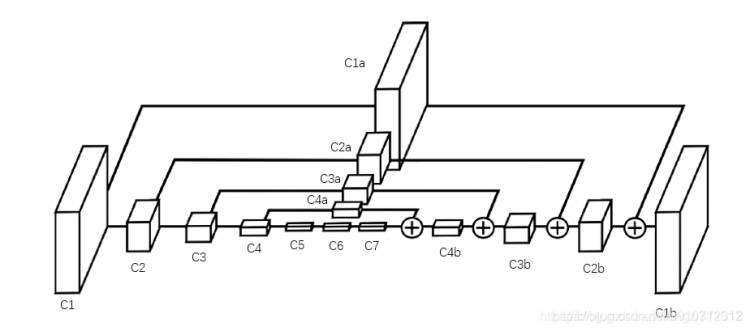
上图就是原论文里给出的HourGlass Model,跟第1节中的网络结构(c1-c7)相比,有两个显著不同:(1)右边就像左边的镜像一样,倒序的复制了一份(c4b-c1b),整体上看起来就是一个沙漏(2)上面也复制了一份(c4a-c1a),而且每个方块还通过加号与右边对应位置的方块合并。
我们来分析下c4b这个网络层,它是由c7和c4a合并来的,这里有两块操作:
(1)c7层通过上采样将分辨率扩大一倍,上采样相当于pool层的反操作,为了将feature map的分辨率扩大,比如c7的kernel size为 4×4 ,那么上采样后得到的kernel size 为 8×8 。
(2)c4a层与c4层的大小保持一致,可以看作是c4层的“副本”,它的kernel size 是c7的两倍,刚好与被上采样后的c7大小一致,可以直接将数值相加,那么就得到了c4b
用python伪代码写下来上述操作如下:
c7_up = up_sample(c7) # 1x4x4x256 -> 1x8x8x256
c4_a = residual(c4) # 1x8x8x256 -> 1x8x8x256
# c4_a相当于c4的副本,但是经过了一个residual处理
# 后面会解释这个操作,这里可以简单理解为复制了一份c4
c4b = c4_a + c7_up # 1x8x8x256
接下来就是c3b这个网络层,同样的,先对c4b进行上采样,然后与c3a合并,python伪代码如下:
c4_up = up_sample(c4_b) # 1x8x8x256 -> 1x16x16x256
c3_a = residual(c3) # 1x16x16x256 -> 1x32x32x256
c3b = c3_a + c4_up # 1x16x16x256
后面的层不再赘述。
这样将feature map层层叠加后,最后一个大的feature map – c1b 既保留了所有层的信息,又与输入原图大小,意味着可以通过1×1卷积生成代表关键点概率的heat map ,上图中并未画出该部分
2.2 Heat Map
大部分姿态检测的最后一步,是在feature map上对每个像素做概率预测,计算该像素是某个关节点的概率。

上图就是各个关节点的heat map,左边第一张为输入图像以及最终的预测关节点位置,第二张为对颈部节点的概率预测,红色和黄色代表着对应像素位置是颈部的概率很高,其他蓝色区域意味着这里几乎不会是颈部位置。
实际代码里,所有关节的预测是一起的,放在一个大的高维矩阵里,上图是为了演示才分开画的。
[ px1_of_c1b ]->[socre_of_neck,score_of_wrist,socre_of_knee,... ]
[ px2_of_c1b ]->[score_of_neck,score_of_wrist,score_of_knee,... ]
# px1_of_c1b,px2_of_c1b 是特征层c1b上的两个像素
# score_of_neck 是预测该点为颈部关键点的得分
2.3 关节点间的相互参考
2.1节给出的hourglass network 其实已经可以用来训练姿态估计了,但是为什么作者还要将沙漏网络串联呢?
关节点之间是可以互相参考预测的,即知道双肩的位置后,可以更好的预测肘部节点,给出腰部和脚踝位置,又可以用于预测膝盖。其他姿态估计文章有利用图模型(Graphic Model)来结合CNN做预测的,这个图模型就是对人体关节点的结构做抽象归纳。但是目前的图模型效果一般。
既然热力图代表了输入对象的所有关节点,那么热力图就包含了所有关节点的相互关系,可以看作是图模型。所以将第一个沙漏网络给出的热力图作为下一个沙漏网络的输入,就意味着第二个沙漏网络可以使用关节点件的相互关系,从而提升了关节点的预测精度。
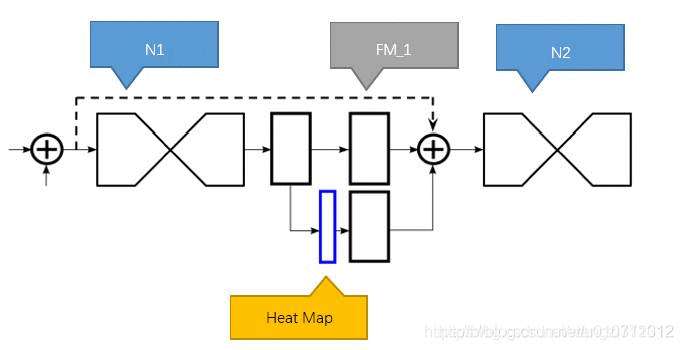
如上图,N1代表第一个沙漏网络,提取出的混合特征经过1个1×1全卷积网络后,分成上下两个分支,上部分支继续经过1×1卷积后,进入下一个沙漏网络。下部分支先经过1×1卷积后,生成heat map,就是图中蓝色部分.
上图中蓝色方块比其他三个方块要窄一些,这是因为heat map矩阵的depth与训练数据里的节点数一致,比如 [1x64x64x16],其他几个则具有较高的depth,如 [1x64x64x256]
heat_map继续经过1×1卷积,将depth调整到与上部分支一致,如256,最后与上部分支合并,一起作为下一个沙漏网络的输入。
2.4 中间监督(Intermediate Supervision)
传统的识别或者检测网络,loss只比较最后的预测与ground truth之间的差异。因为堆叠沙漏网络的每一个子沙漏网络都会有heat map作为预测,所以将每个沙漏输出的heat map参与到loss中,实验证实,预测精确度要远远好于只考虑最后一个沙漏预测的loss,这种考虑网络中间部分的监督训练方式,就叫做中间监督(Intermediate Supervision)
3 训练过程细节
作者在FLIC和MPII Human Pose数据集上进行了训练与评估。这篇论文只能用于单人姿态检测,但是在一张图片中经常有多个人,解决办法就是只对图片正中心的人物进行训练。将目标人物裁剪到正中心后再将输入图片resize到256×256。为了进行数据增量,作者将图片进行了旋转(+/-30度)、scaling(.75-1.25)。
网络使用RMSprop进行优化,学习率为2.5e-4. 测试的时候使用原图及其翻转的版本进行预测,结果取平均值。网络对于关节点的预测是heatmap的最大激活值。损失函数使用均方误差(Mean Squared Error,MSE)来比较预测的heatmap与ground truth的heatmap(在节点中心周围使用2D高斯分布,标准差为1)

代码分析:
创建网络
把打开工程文件夹,Stacked Hourglass的整体网络架构是在src/models/hg.lua文件中实现的:
function createModel()
local inp = nn.Identity()()
-- Initial processing of the image
local cnv1_ = nnlib.SpatialConvolution(3,64,7,7,2,2,3,3)(inp) -- 128
local cnv1 = nnlib.ReLU(true)(nn.SpatialBatchNormalization(64)(cnv1_))
local r1 = Residual(64,128)(cnv1)
local pool = nnlib.SpatialMaxPooling(2,2,2,2)(r1) -- 64
local r4 = Residual(128,128)(pool)
local r5 = Residual(128,opt.nFeats)(r4)
local out = { }
local inter = r5
for i = 1,opt.nStack do
local hg = hourglass(4,opt.nFeats,inter)
-- Residual layers at output resolution
local ll = hg
for j = 1,opt.nModules do ll = Residual(opt.nFeats,opt.nFeats)(ll) end
-- Linear layer to produce first set of predictions
ll = lin(opt.nFeats,opt.nFeats,ll)
-- Predicted heatmaps
local tmpOut = nnlib.SpatialConvolution(opt.nFeats,ref.nOutChannels,1,1,1,1,0,0)(ll)
table.insert(out,tmpOut)
-- Add predictions back
if i < opt.nStack then
local ll_ = nnlib.SpatialConvolution(opt.nFeats,opt.nFeats,1,1,1,1,0,0)(ll)
local tmpOut_ = nnlib.SpatialConvolution(ref.nOutChannels,opt.nFeats,1,1,1,1,0,0)(tmpOut)
inter = nn.CAddTable()({ inter, ll_, tmpOut_})
end
end
-- Final model
local model = nn.gModule({ inp}, out)
return model
end
我们来一行行分析这个网络的实现。
inp是是表示输入的向量,在该工程中,它的大小为batchsize×3×256×256,训练的样本都是彩色图片,所以每一次训练的输入是batchsize大小的3通道的256×256的图片,如果图片本来不是256×256,要先截取人物部分的方框并缩放到256×256的大小。(以下输入输出大小均省去batchsize)
输入的图片先通过一个卷积层,卷积核大小为7 * 7,slide为2,pad为3,输出层数为64.经过这一层的卷积后,cnv1的大小为64 * 128 * 128,再把它batch normalization和用ReLU激活。
cnv1接下来通过一个Residual的网络,接下来的网络依次是一个池化层和两个Residual模块网络,到这边为止,得到将是opt.nFeats * 64 * 64的特征,这里的opt.nFeats是预先设定的参数,论文和工程都是预设为256(后面opt开头的都是工程预设的数值)。
Residual模块
预处理和后面hourglass部分都用到了大量的Residual模块,其实现代码如下:
local conv = nnlib.SpatialConvolution
local batchnorm = nn.SpatialBatchNormalization
local relu = nnlib.ReLU
-- Main convolutional block
local function convBlock(numIn,numOut)
return nn.Sequential()
:add(batchnorm(numIn))
:add(relu(true))
:add(conv(numIn,numOut/2,1,1))
:add(batchnorm(numOut/2))
:add(relu(true))
:add(conv(numOut/2,numOut/2,3,3,1,1,1,1))
:add(batchnorm(numOut/2))
:add(relu(true))
:add(conv(numOut/2,numOut,1,1))
end
-- Skip layer
local function skipLayer(numIn,numOut)
if numIn == numOut then
return nn.Identity()
else
return nn.Sequential()
:add(conv(numIn,numOut,1,1))
end
end
-- Residual block
function Residual(numIn,numOut)
return nn.Sequential()
:add(nn.ConcatTable()
:add(convBlock(numIn,numOut))
:add(skipLayer(numIn,numOut)))
:add(nn.CAddTable(true))
end
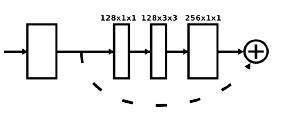
Residual模块是由两个子模块convBlock和skipLayer构成的,参数是输入层数和输出层数。
convBlock子模块相对复杂,由三组batchNormalization+ReLU+convolution串联构成,具体代码参考上面function convBlock部分,不再赘述。(图中的实线箭头移动部分,卷积核的大小如图中数字所示)skipLayer比较简单,如果输入层数等于输出层数,就直接输出,如果不等,就通过一个卷积层让输出层数变成设定值。(图中的虚线部分)最后两个子模块的输出合在一起,作为Residual模块的输出。
Houglass模块
从输入图片到得到opt.nFeats * 64 * 64的特征,只是网络处理的开始,还没有真正进入漏斗状的网络中。接下来才真正要进入hourglass网络。
在for语句那一行的opt.nStack是预设的层叠个数,表示要叠用几个漏斗状网络。
每个层叠的漏斗网络包括基本的hourglass模块,opt.nModules个Residual模块,一个卷积层,batch normalization,ReLU以及再一个卷积层。到这里为止,网络得到就是nJoints * 64 * 64大小的热图,这里的nJoints表示人体关键点的个数,也就是ref.nOutChannels的值。
基本的hourlass模块的函数如下:
local function hourglass(n, f, inp)
-- Upper branch
local up1 = inp
for i = 1,opt.nModules do up1 = Residual(f,f)(up1) end
-- Lower branch
local low1 = nnlib.SpatialMaxPooling(2,2,2,2)(inp)
for i = 1,opt.nModules do low1 = Residual(f,f)(low1) end
local low2
if n > 1 then low2 = hourglass(n-1,f,low1)
else
low2 = low1
for i = 1,opt.nModules do low2 = Residual(f,f)(low2) end
end
local low3 = low2
for i = 1,opt.nModules do low3 = Residual(f,f)(low3) end
local up2 = nn.SpatialUpSamplingNearest(2)(low3)
-- Bring two branches together
return nn.CAddTable()({ up1,up2})
end
Hourglass模块之间
hourlass模块的输出再经过两个1*1的卷积层后,结果作为当前stack的热图输出tempOut,两个卷积层之间的结果在createModel函数中记为ll。
在两个漏斗网络之间,还要对热图进行进一步的处理,分别是:1.对上一个漏斗网络中的ll通过一个卷积层;2.对上一个漏斗网络的热图tempOut通过一个卷积层。最后这两个结果和前一个漏斗的输入合并,作为下一个漏斗网络的输入。
漏斗间的处理结构图如下:
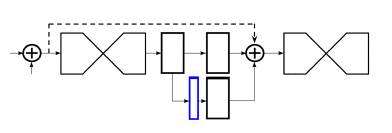
图中的蓝色部分表示当前stack的热图。
损失函数
最后得到的热图总共有opt.nStack组,每一个漏斗网络输出的结果都是一组热图(nJoints6464)。训练的时候,每一个漏斗网络的ground truth heatmaps都是一样的,根据关键点label生成一个二维的高斯图,损失函数是所有stack的输出热图和ground truth热图之差的L2范数(MSE)。
预测
预测时,输入任意一张人物图片(256*256),得到最后一个stack的输出热图(不是所有的)。








 京公网安备 11010802041100号
京公网安备 11010802041100号