
来源:Pexels
这篇文章是关于科学家们运用手头的计算能力,并使用Swifter软件将其应用到panda数据帧中。
问题陈述
科学家们已经拥有一个巨大的panda数据帧,要对它应用一个复杂的函数,需要很多时间。
针对这篇文章,笔者将生成25万行和4列的相关数据。
使用并行化可以很容易地获得代码的额外性能吗?
import pandas as pdimport numpy as nppdf = pd.DataFrame(np.random.randint(0,100,size=(25000000,4)),columns=list( abcd ))
数据如下:
数据样本
仅使用单个更改的并行化

来源:Pexels 放松并并行化!!
接下来进行一个简单的实验。
尝试在数据帧(dataframe)中创建一个新列。这一步骤可以简单地通过在panda中使用 apply-lambda 来实现。
def func(a,b): if a>50: return True elif b>75: return True else: return Falsepdf[ e ] =pdf.apply(lambda x : func(x[ a ],x[ b ]),axis=1)

以上的代码大约需要10分钟才能运行。笔者只是对以上这两列做一个简单的计算。
那能够优化吗?需要做些什么呢?
当然,回答是肯定的,只要加上一个“神奇的词”—— Swifter就能够进行优化。
但是首先,需要安装swifter软件,这十分容易:
conda install -c conda-forgeswifter
然后只需在 apply 使用它之前导入并附加swifter关键字来进行操作。
import swifterpdf[ e ] = pdf.swifter.apply(lambda x : func(x[ a ],x[ b ]),axis=1)
这有效果吗?

当然。与只使用函数本身相比,这一操作可以将运行时间缩短一倍。
这其中到底蕴藏着什么奥秘呢?
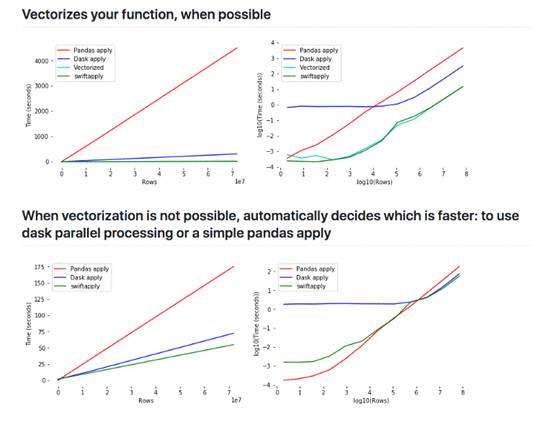
来源:增加数据的大小如何影响Dask, Pandas 和 Swifter的性能?
Swifter通过向量化函数或在后端使用Dask并行化函数,再或者在数据集较小的情况下使用简单的panda apply函数,来选择实现函数 apply的最佳方式。
在本例中,Swifter使用Dask将apply函数与默认值并行化npartitions = cpu_count()*2.
对于笔者正在处理的MacBook, 其CPU计数是6,而超线程是2。因此,CPU计数是12,这使得npartitions的值为24。
读者也可以选择自己设置n_partitions的值。笔者注意到默认值在大多数情况下都能正常运作,但读者也可以通过调优它来获得额外的加速。
例如:如果设置n_partitions=12,然后又得到了2x的加速。在这里,减少分区数量会减少运行时间,因为分区之间的数据迁移成本很高。

结论
并行不是什么灵丹妙药,它是一剂炸弹。
并行化并不能解决所有的问题,仍然需要优化函数,但是它是一个很好的工具。
时间一去不复返,时间总是不够用的。在这种情况下,需要在数据处理中用一个词来进行并行处理。
这个词是swifter。

来源:Pexels
工作固然重要,但人生在世,最重要的还是生活。
希望大家阅读完这篇文章后,都能灵活运用它,提高效率,为自己省下“好好生活”的时间。
相关链接:
https://towardsdatascience.com/add-this-single-word-to-make-your-pandas-apply-faster-90ee2fffe9e8
* 凡来源非注明“机器学习算法与Python学习原创”的所有作品均为转载稿件,其目的在于促进信息交流,并不代表本公众号赞同其观点或对其内容真实性负责。
推荐阅读
告别2019:属于深度学习的十年,那些我们必须知道的经典
NeurIPS顶会接收,PyTorch官方论文首次曝光完整设计思路
下载 | 700页《图形深度学习》教程【PPT】
一行代码简化Python异常信息:错误清晰指出,排版简洁美观 | 开源









 京公网安备 11010802041100号
京公网安备 11010802041100号