作者:过期物品请勿购_613 | 来源:互联网 | 2023-06-19 20:17
索引到底是什么?我们今天就来絮叨絮叨。从图中可发现,搜索加载超过1s就会直接影响页面放弃率,1s是用户的观感界限,所以搜索引擎的响应时间是需要着重优化的。然而无论是大搜还是垂搜,随
当你在搜索引擎的搜索框中输入你想查找的关键词后,首先影响你体验的并非是不相关的搜索结果,而是界面出现“loading”、“服务正在加载中”、“搜索响应失败”等字眼。据统计,搜索页面的加载时间会严重影响用户的搜索体验,进而丢失掉优质用户。如下图:
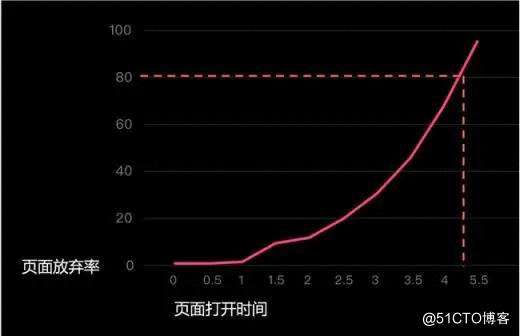
索引到底是什么?我们今天就来絮叨絮叨。从图中可发现,搜索加载超过1s就会直接影响页面放弃率,1s是用户的观感界限,所以搜索引擎的响应时间是需要着重优化的。然而无论是大搜还是垂搜,随着大数据时代的发展,被查询记录数都是数以亿计,甚至万亿计。搜索引擎是如何在大数据体量做到ms级返回的,这里就牵扯到索引的概念了。
先举个例子:
假如你是一位创业者,最开始你的公司只有10个打工人,某一天,你想找到其中几位有“销售经验”的人组建一销售团队,我相信你一个个询问、排除也很快能找出来的。这就是所谓的遍历查询。
几个月后,你拿到了一笔投资,你的团队也从10个人扩充到了100个人,这个时候你想找有“运营经验”的员工组建运营团队,发现一个个询问有点力不从心了,于是你想了个办法,提前将100个人,分到10个部门,你想找各种经验的人,直接到对应的职能部门让部门经理找就可以。这就是搜索中的正排索引。如下图:
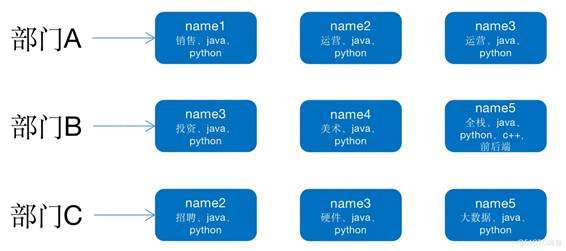
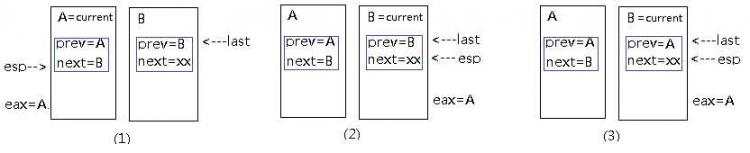
后来随着公司的爆发式增长,你的公司现在有1w人了,部门已经是事业群了,组织架构也从之前的单层升级到多层,这时你想找到有“全栈经验”的开发工程师组建新的团队开发新的产品,发现把找人任务分下去后“疯了”,因为很有可能找完1w个人之后才能找到合适的人,这个时候你又想到一招,反过来思考,我既然最终要找的是人,那么我就以人为中心建立一套标准,先找到对应的人,再根据对应的人反推属于哪个部门,再让这个部门经理找自己团队还有没有符合要求的人,这样范围不是减小了很多吗?也大大提升了效率。这就是所谓的倒排索引。
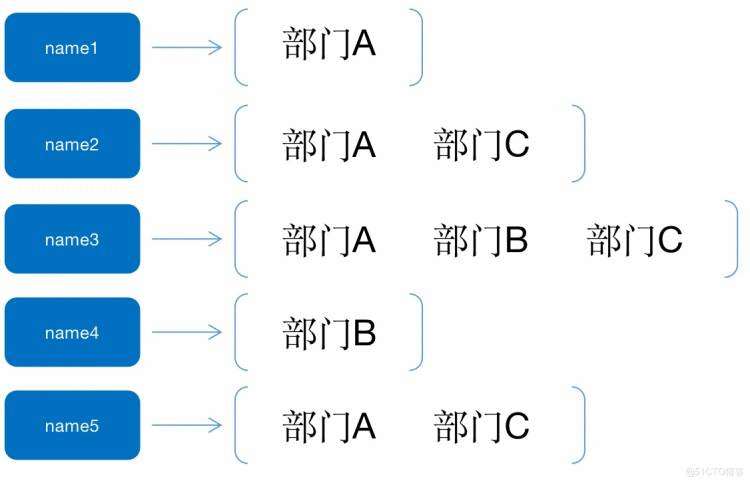
【正排索引】
正排索引也叫正向索引(forward index),在蜘蛛爬取页面后,系统将页面标题、内容,经过文本预处理,可以得到独特的、能反应页面的主题内容、以词为单位的字符串。搜索引擎索引程序就可以提取关键词信息,包含出现次数,位置等,为该页面建立页面id与关键词的对应关系,而这个过程就叫做正排索引。
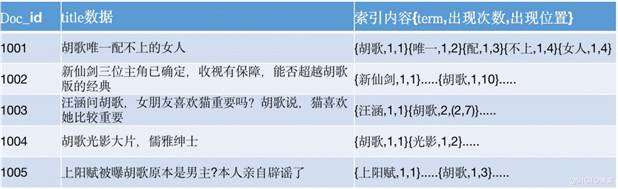
以例子来说明,现在有5篇关于“胡歌”的资讯,如下:
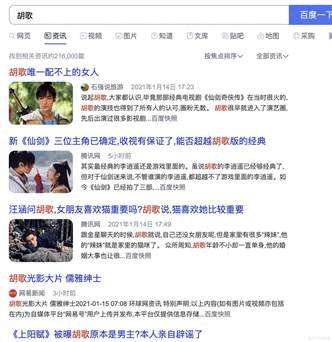
根据5篇资讯的标题,建立正排索引如下:
【倒排索引】
从上图可发现,此种方法结构比较简单,索引建立起来也比较方便,如果有文档添加时,直接按照此格式在后面添加索引块即可。如若需要删除,也指定id删除即可找到对应的所有信息直接删除即可。但是在查询的时候当你不知道你查询的内容的id是多少时,只能从1001扫描至1005,才能确保召回数没有遗漏,因此检索效率是及其低下。
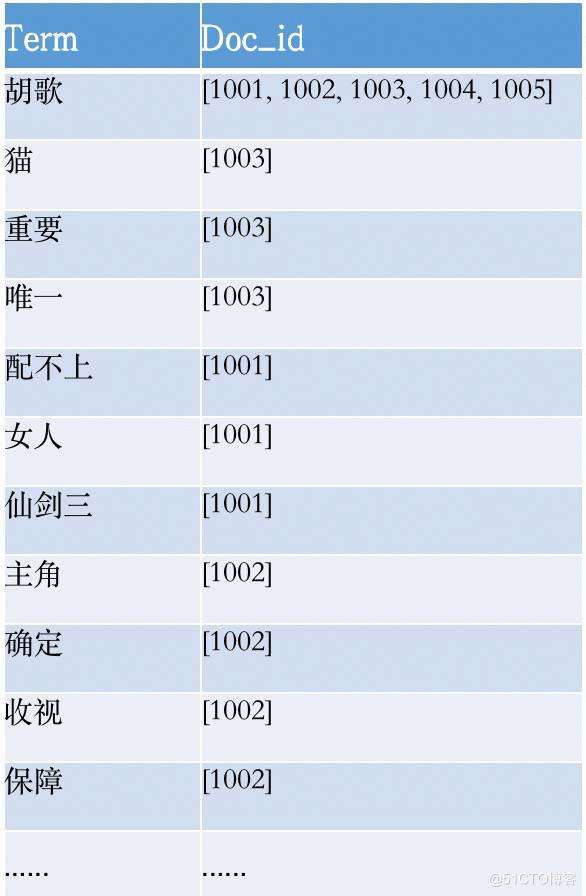
由于正排的查询效率实在太低,所以就有了倒排索引,也叫反向索引(inverted index)。在建立索引过程,将正排索引中的id对应的所有的关键词进行反转,建立一套以关键词为准的在哪个文档中出现过的索引,如下:
【摘要索引】
由上图可知,如果要查询“猫”,只查询id为1003的文档即可,缩小了查询范围,提升了查询效率。倒排索引有着广泛的应用场景,比如:不仅用于搜索引擎、大规模数据库索引、文档检索、多媒体检索/信息检索领域等等。总之,倒排索引在检索领域是很重要的一种索引机制。
除此之外,还有摘要索引用于部分场景的搜索效率提升,摘要索引将文档所需返回展示的对应信息存储在一起,通过Doc_id可以定位该文档的存储位置,并获取对应的摘要信息,为用户提供摘要获取服务。摘要索引的结构和正排索引类似,但其功能不同,其结构如下:

【分布式索引】
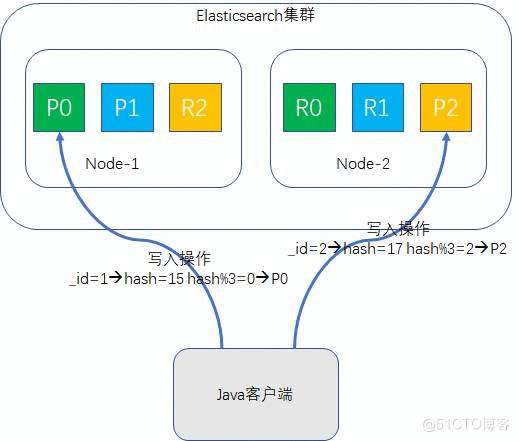
以上几种索引都是索引的结构,但仅仅使用这些索引结构进行优化是不够的,还需要在架构层面进行索引优化,既所谓的分布式索引,开源的solr和Elasticsearch都支持分布式索引,根据文档的id计算hash值,负载均衡将索引写入至对应的分片,以Elasticsearch为例,看下如下过程:
?
?
Node-1和Node-2为ES集群的两个节点,根据不同的id值hash后 ,写入不同的节点。查询过程基于整个集群并行查询,提升查询效率。
现实中无论大搜还是垂搜,都使用了以上的索引结构及架构,大厂甚至部署了集群+集群的方式来支撑高并发,来实现高性能。但每个集群下每个节点都需要索引来支撑,所以效率是搜索的门户。
?

最后欢迎关注同名微信公众号:药老算法(yaolaosuanfa),带你领略搜索、推荐等数据挖掘算法魅力。



 京公网安备 11010802041100号
京公网安备 11010802041100号