原标题:深度丨语音识别技术专利申请分析及关键技术展望(上)
语音识别作为人工智能的重要分支技术,因其使用场景亲民而备受关注,它的技术目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
本文首先对语音识别的现有技术进行梳理和总结,然后从专利申请趋势、主要申请人与发明人及其相关技术、关键技术等方面对语音识别中国专利申请情况进行统计分析。最后,对语音识别技术的国内申请情况进行总结。
由于本文干货充足篇幅较长,为方便大家阅读分享故分上、下两篇进行推送。今天推送的是第一部分,包括:语音识别技术概述、语音识别技术专利申请现状。
关键词:语音识别 ASR
一.语音识别技术概述
(一)研究背景
语音识别是从待识别语音信号中识别出该语音的语义信息、语言信息和说话人特征信息和情感信息等。语音识别技术是模式识别研究领域中一个非常重要组成部分,它涉及到许多学科,包括计算机、通信、语音语言学、电子技术和模式识别等众多学科。
随着科技的进步,人们通过大量的研究,在理论、算法、实验中通过不断地努力和改进,取得了许多重要的科学成果。
二十世纪五十年代,AT&T贝尔实验室的语音识别研究首次取得成功,该系统可以识别出一到十的英文数字,语音识别作为一颗新星正式在历史舞台现身。二十世纪六十年代,随着计算机等技术应用的不断发展和创新,迅速推动了语音识别技术的发展。

其中线性预测技术和动态规划技术的出现使得语音识别有了新的突破:前者解决了信号模型的问题,后者则解决了不等长的语音匹配问题。
以动态时间规划(DTW)为代表的语音识别技术成为上世纪七十年代语音识别领域的新突破。此时的线性预测技术获得了更进一步的发展,动态时间规划技术也逐渐成熟。新理论的提出又为语音识别添上了新的翅膀:矢量量化与隐马尔科夫模型成为语音识别理论中的佼佼者。另一方面,实践中以LPC和DTW结合实现了的孤立词语音识别系统。
上世纪八十年代,语音识别的研究硕果累累,其中HMM模型和基于神经网络技术模型在语音识别中取得新的突破。识别的算法从模板匹配转为基于统计的模型,模型也从基于规则转变为基于统计描述。连接词汇的语音识别系统、连续语言的语音识别系统不断发明出来。一九九八年CMU大学在VQ/HMM基础上幵发的非特定人连续语音识别系统SPHINX可以识别997个词汇。

上世纪九十年代又有了新的成果,语音识别开始往大词汇量、非特定人识别的方向挺进。1993年,DARPA使用具有两万词汇量的华尔街杂志语料库(Wall Street Journal Corpus)进行识别系统评估,它包含2.6万词汇的Switchboard语料库,是一个电话交谈语音库。在1998年,DARPR使用英语电台、电视新闻节目录音等资源库对广播新闻语料迸行评估,这里面包含了各种复杂背景噪音,信号失真以及口音问题,使得识别的难度大大增加。在这些识别系统中,剑桥大学的HTK系统对于低噪声部分评测具有较高的识别率,其准确率达到92.2%,而法国国家实验室的LIMSI在自然语言发音部分的识别率最高,达到85.4%。
语音识别技术关键技术不断的取得新的突破,识别技术日渐成熟。在计算机技术、电信行业应用等领域的推动下,实用化的语音识别系统及与此相关的语音服务应用走上历史舞台。
各个行业技术的迅速发展使得语音识别技术也随之达到一个高的水平,在稳健性、自适应性方面语音识别不断地从实验室走向实用产品。这一时期,语音识别的关键性特征为非特定人大词汇连续语音识别的高识别率。英国剑桥大学的HTK系统在理想语音库下的准确率超过95%;其另一个语音识别系统在广播语音的
识别率达到83.8%;美国卡内基梅隆大学的系统对于大词汇量的电话语音的识别误识率为45.1%,这些系统是语音识别系统中小词汇表现最佳的典范。
国内语音识别在上世纪七十年代以中国科学院声学所为先驱,实用电子管电路识别出十个元音,开启了国内语音识别的新天地。80年代计算机技术的发展使得我国的语音识别研究的条件基本具备。于是各个研究部门纷纷行动建立起课题,主要包括清华大学、中科院声学所、北方交通大学等科研院校及机构,而中国科技大学、哈尔滨工业大学、四川大学等也积极响应进行研究。1987年国家高科技发展计划启动,语音识别成为重要的研究课题,并进行组织化的专题会议,进行每两年一次的讨论学习会议,从而推动国内语音识别进入了新的发展阶段。

近年来,语音识别的研究以HMM为主要模型算法,其他多种技术方向并存。HMM模型在框架设计、实践序列建模和多层次信息融合等方面依然有着很大的优势。实际的应用中,仍然以HMM为主,其他技术为辅的框架。
(二)语音识别技术基本原理
目前,大多数语音识别系统都采用了模式匹配的原理。根据这个原理,未知语音的模式要与已知语音的参考模式逐一进行比较,最佳匹配的参考模式被作为识别结果。
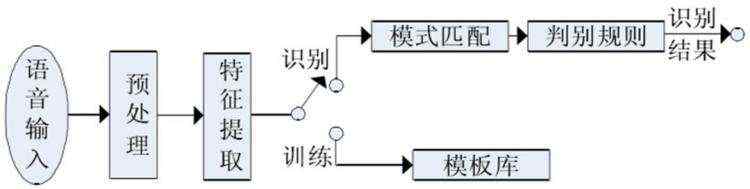
(语音识别系统原理图)
该图中,待识别语音先经话筒变换成语音信号,然后从识别系统前端输入,再进行预处理。预处理包括语音信号采样、反混叠带通滤波、去除个体发音差异和设备、环境引起的噪声影响等,并涉及到语音识别基元的选取和端点检测问题,有时还包括模数转换器。特征提取部分用于提取语音中反映本质特征的声学参数,常用的特征有短时平均能量或幅度、短时平均跨零率、短时自相关函数、线性预测系数、清音/浊音标志、基音频率、短时傅立叶变换、倒谱、共振峰等。训练在识别之前进行, 是通过让讲话者多次重复语音,从原始语音样本中去除冗余信息,保留关键数据,再按一定规则对数据加以聚类,形成模式库。模式匹配是整个语音识别系统的核心,是根据一定的准则以及专家知识(例如构词规则、语法规则、语义规则等),计算输入特征与库存模式之间的相似度,判断出输入语音的语意信息。
(三)语音识别技术基本方法
语音语音识别方法主要有动态时间归正技术(DTW)、矢量量化技术(VQ)、隐马尔可夫模型(HMM)、基于段长分布的非齐次隐含马尔可夫模型(Duration Distribution Based Hidden Markov Model,DDBHMM)和人工神经元网络(ANN)。
DTW是较早的一种模式匹配和模型训练技术,它应用动态规划方法成功解决了语音信号特征参数序列比较时时长不等的难题,在孤立词语音识别中获得了良好性能。但因其不适合连续语音大词汇量语音识别系统,目前已被HMM模型和ANN代替。
VQ技术从训练语音中提取特征矢量,得到特征矢量集,通过LBG算法生成码本,在识别时从测试语音提取特征矢量序列,把它们与各个码本进行匹配,计算各自的平均量化误差,选择平均量化误差最小的码本,作为被识别的语音。但同样只适用孤立词而不适合连续语音大词汇量语音识别。
HMM模型是语音信号时变特征的有参表示法,它由相互关联的两个随机过程共同描述信号的统计特性,其中一个是隐蔽的(不可观测的)有限状态的 Markov链,另一个是与Markov链的每一状态相关联的观察矢量的随机过程(可观测的)。隐蔽Markov链的特征要靠可观测到的信号特征揭示。这样,语音时变信号某一段的特征就由对应状态观察符号的随机过程描述,而信号随时间的变化由隐蔽Markov链的转移概率描述。模型参数包括HMM拓扑结构、状态转移概率及描述观察符号统计特性的一组随机函数。按照随机函数的特点,HMM模型可分为离散隐马尔可夫模型(采用离散概率密度函数,简称DHMM)和连续隐马尔可夫模型(采用连续概率密度函数,简称CHMM)以及半连续隐马尔可夫模型(SCHMM)。一般来讲,在训练数据足够的情况下,CHMM优于DHMM和SCHMM。HMM模型统一了语音识别中声学层和语音学层的算法结构,以概率的形式将声学层中得到的信息和语音学层中已有的信息完美地结合在一起,极大地增强了连续语音识别的效果。
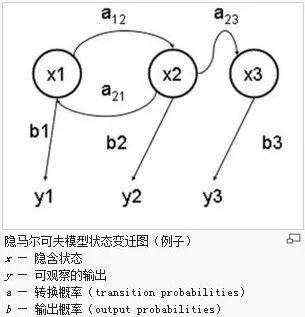
语音学的研究表明,语音单位在词中的长度有一个相对平稳的分布。正是这种状态长度分布的相对平稳性破坏了HMM模型的齐次性结构,而王作英教授提出的DDBHMM模型解决了这一缺陷。它是一个非齐次的HMM语音识别模型,从非平稳的角度考虑问题,用状态的段长分布函数替代了齐次HMM中的状态转移矩阵,彻底抛弃了“平稳的假设”,使模型成为一种基于状态段长分布的隐含Markov模型。段长分布函数的引入澄清了经典HMM语音识别模型的许多矛盾,这使得 DDBHMM比国际上流行的HMM语音识别模型有更好的识别性能和更低的计算复杂度(训练算法比流行的Baum算法复杂度低两个数量级)。由于该模型解除了对语音信号状态的齐次性和对语音特征的非相关性的限制,因此为语音识别研究的深入发展提供了一个和谐的框架。
语音识别面临的主要困难是理论上没有突破,虽然各种新的修正方法不断涌现,但其普遍适用性都值得商榷。另外,语音识别系统在商品化的进程中还要解决诸如识别速度、拒识问题以及关键词(句)检测等具体问题,主要表现在两个方面:
一是对环境的依赖性强。语音识别系统在某些环境下采集的语音进行训练后,必须在相同的环境下进行识别,否则性能急剧下降,例如自适应性差,最近凸现出的方言或口音、背景噪音、口语发音的“新三难”问题等,都会影响识别的准确性。目前可采用麦克风阵列技术消除单一麦克对语音的影响,同时在预处理阶段通过语音增强算法,使语音的可懂度和信噪比增强。
二是模型和算法都存在一定的缺陷。随着HMM语音识别方法研究工作的深入,人们也越来越认识到经典HMM语音识别模型在一些重要方面存在严重的缺陷,既不符合语音信号的实际情况,又使得模型的训练量和存储量太大。目前提出了各种各样的HMM改进算法,还加入了遗传算法、并行算法和神经网络等新技术,使得HMM的训练和识别更加准确。
二.语音识别技术专利申请现状
(一)语音识别专利申请发展趋势
在CNABS数据库中,使用索引AB和关键字“语音识别”对专利申请进行统计(统计日期为2000年1月1日-2017年6月14日),共获得7587篇专利,同时,使用相关联分类号G06K9/00、G06F17/30、G10L15/00以及G10L17/00进行限定,得到专利文献2138篇。利用索引APD对2000年1月1日至2017年6月14日的各年份专利申请量进行统计。下图给出了专利申请量随年代的分布情况。
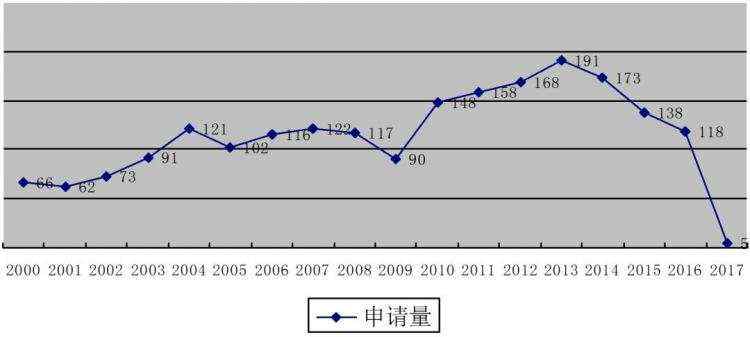
(语音识别领域的国内专利申请量趋势图)
由上图可以看出,语音识别技术在2000年-2004年的申请量呈现缓慢增长趋势,处于发展的新兴期;从2004年开始至2009年,申请量保持平稳状态,专利申请量较之前有了稳定发展;从2009年开始,语音识别技术的专利申请数量再次逐步增加,在2013年达到顶峰,主要归功于语音识别技术在各种移动终端上的应用日趋广发与智能手机行业的飞速发展。随着移动互联网技术的不断发展,尤其是移动终端的小型化、多样化变化趋势、语音识别作为区别于键盘、触屏的人机交互手段之一,又具有了自己独特的优势。从2013年开始语音识别技术领域国内专利申请量呈逐年下降的状态,这也与专利申请的有关公开状态相关。
同时,通过对该领域内专利申请进行分析,统计得出主要专利申请分布如下表所示:
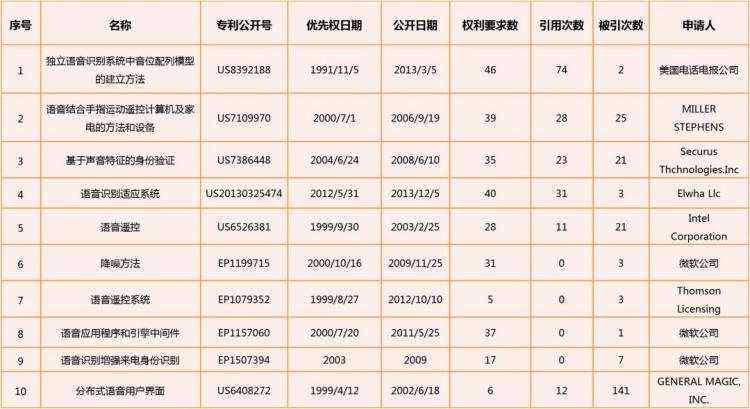
(语音识别技术领域重要专利表)
(二)申请人与发明人分析
使用索引PA对上述2138篇专利申请的申请人进行统计,得到中国专利申请量位于前10位的专利申请人如下图所示。
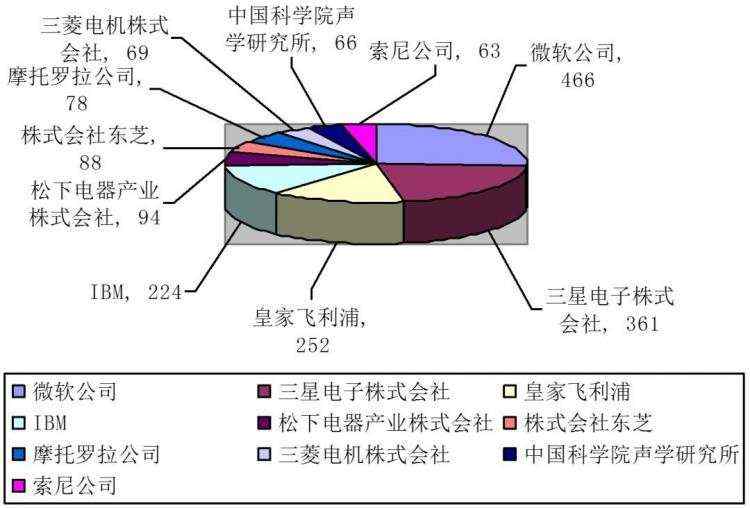
(语音识别领域中国申请的前10名申请人占比统计图)
从申请人角度来看,在语音识别领域,国外开始研究的比较早。在该领域排名前10位的申请人中,国外大企业占据了绝大部分申请数量,其中国外申请人9家,国内申请人只有中国科学院声学研究所与被联想所收购的摩托罗拉公司两家。从企业所属的国别来看,日本(4家)、中国(2家)、美国(2家)、韩国(1家)、荷兰(1家),美国起步最早,2000年后专利增长迅速,其发展重点是语音输入/输出、语音数据处理系统及语音软件产品开发。日本于20世纪90年代起开始该领域的技术探索,2000-2007年期间专利产出量较大,与美国申请量相当,但2008年以后,专利量开始迅速减少,呈现下滑趋势。日本的研发重点是语音输入/输出、语音数据处理系统。中国和韩国涉足时间较晚,2000年前后开始该领域的专利申请,2010年后专利快速增长。从企业性质分析,在该领域排名前10位的申请人中,以手机生产为主要经营领域的厂家有4家,占据40%,申请量968件,占据申请总量的55%。
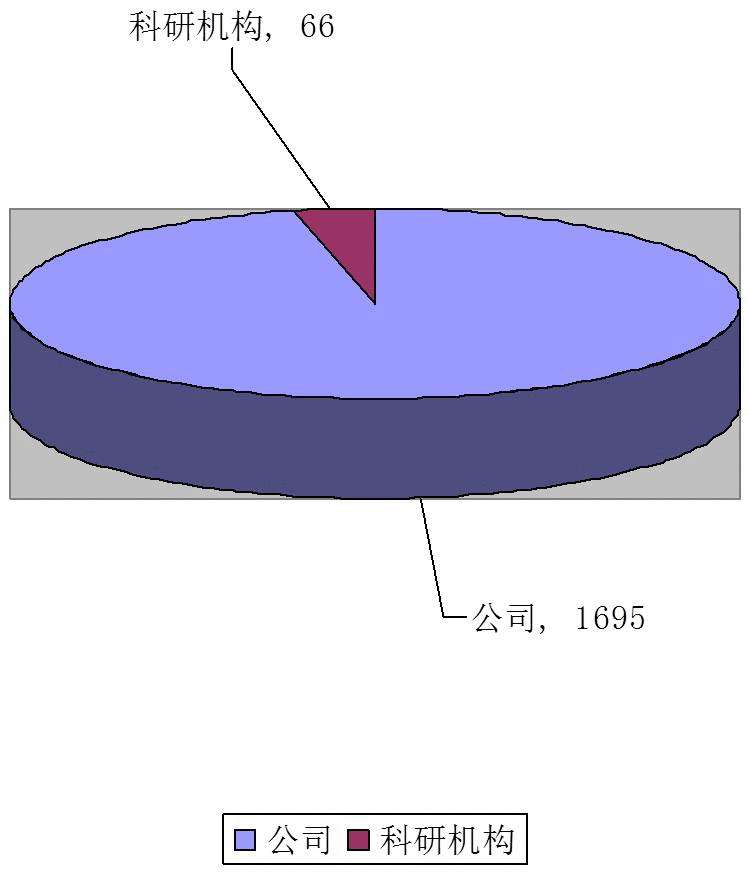
(语音识别领域中国申请申请人类别情况)
上图统计了三维人脸识别领域中国申请的申请人类别情况。国内申请人中,公司申请量占据了96%,科研机构申请仅仅占据了4%。通过上述数据不难发现,国内科研机构在语音识别领域专利申请与国内外公司相比,存在着巨大差距,相关科研探索有待进一步挖掘。
语音交互技术的发明人主要分布于微软、船井电机、三星、韩国电子通信研究院、松下等公司,主要发明人情况如下表所示。
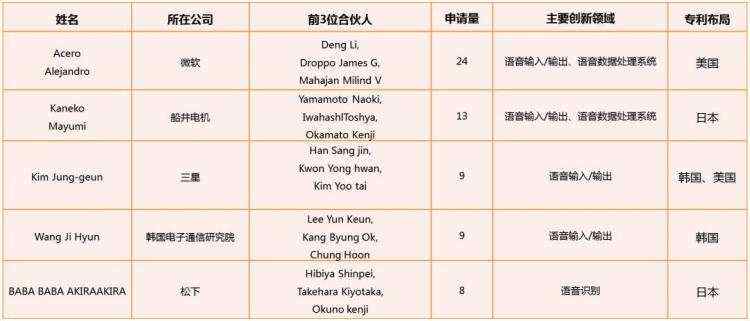
(语音识别技术主要发明人概况表)
(三)主要申请人及其技术分布
1.微软公司

微软公司作为全球最大的PC软件公司,在其推出的众多操作系统中,越来越重视语音识别技术的开发和应用,极大促进了语音识别技术的进一步竞争和发展。通过对微软公司语音识别方面专利的分析,可以把微软公司的技术发展历程分为三个阶段。
第一阶段1997-2001年,微软公司主要是在其产品中集成语音识别的功能。这一阶段的专利申请以语音识别的应用为主,其应用方向包括移动互联网、呼叫中心和教育等。如专利CN1295705A中,其提出了一种对用于语音识别系统中的语言模型进行适配的方法,其通过访问不同类型的数据存储器,以及在不同类型的存储器之间进行查询命令的优化级联查询,以提高了数据查询的效率。
第二阶段2002-2007年,是微软公司在语音识别方面技术爆发的阶段,在前端特征处理、声学模型、语言模型、后端处理、识别引擎及语音识别的应用方面都进行了大量申请。如专利CN1838694A中,其提出了一种并发地提供便于控制应用程序状态机的多个用户接口的机制系统,可以创建两个相对不同的用户体验,一个通过使用双音多频导航,一个通过语音识别导航。
第三阶段2008-2013年,微软公司在语音识别各方面的申请量都骤减,除了在语音识别应用领域申请量保持平稳之外,其他技术分支上的申请都很少。在这一阶段,微软公司的市场行为也主要集中在语音识别的应用方面,而在技术研发方面,微软公司似乎进入了一个瓶颈期,对语音识别率和识别速度等方面,都没有出现重大突破。其专利技术主要集中于语音输入/输出、语音软件产品和语音数据处理系统。形成了以邓立博士和宋歌平博士为核心成员的两个研发团队,团队主要成员概括如下表所示。
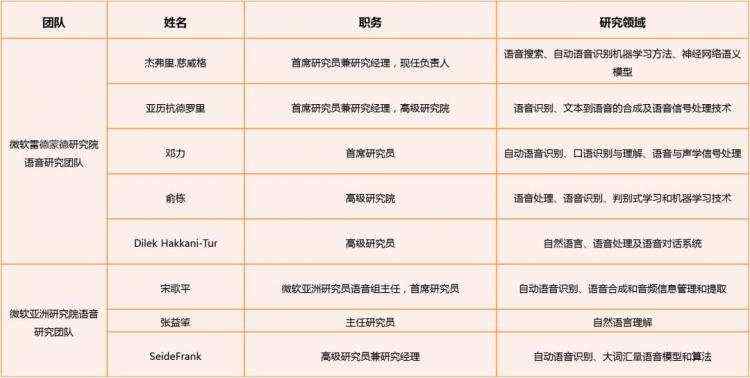
(微软公司语音研究团队主要成员概况表)
微软公司在全球申请和中国申请的发展态势整体上是对应的,中国是微软在全球市场的重要组成部分。虽然微软公司在中国的专利布局晚于全球市场,但其在中国市场的申请量一直处于较高的水平,可见,中国市场得到微软公司足够的重视,在语音识别领域具有十分广阔的前景。
2.三星电子株式会社

三星电子的触角已经延伸到生活中的方方面面,从家电到计算机、平板电脑、电灯泡、智能手机等等。作为手机行业的巨头,三星电子早期的语音识别专利申请中,更多关注于手机语音识别。如CN1272996A,其提出了一种具有语音拨号功能的蜂窝电话,其能够连接到一个免提装置,并有一个从输入话音信号中提取特征数据以便识别语音信号的语音识别设备和一个存储扩展特征数据的存储器,存储器被划分为用于存储从蜂窝电话输入的特征数据的第一存储区、用于存储从免提装置输入的特征数据的第二存储区、和用于存储语音慧芳数据的第三存储区,能够达到对语音识别存储器有效的利用管理。
随着近些年移动互联网与智能家居产业的兴起,三星电子将更多的经历投入其中。其专利申请CN101420543A公开了一种语音控制电视机的方法及其电视,通过预先录制用户的语音样本,并将录制好的语音样本进行存储;预先存储每个电视功能信号与所存储的录音样本之间的对应关系;采集用户的语音信号,将所采集的用户语音信号与存储的语音样本进行识别;当存在相匹配的语音样本时,根据上述电视功能信号与所存储的录音样本之间的对应关系,获知该相匹配的语音样本所对应的电视功能信号;根据用户语音信号所相匹配的语音样本所对应的电视功能信号,控制电视机的具体运行。通过语音识别可以获知用户的每个语音信号所对应的电视功能命令信号,让用户通过自己的语音就可以对电视进行控制。
(本文其余内容:语音识别关键技术展望及总结,将于明天推送,敬请期待)
如需咨询语音识别相关业务
作者简介
责任编辑:







 京公网安备 11010802041100号
京公网安备 11010802041100号